Batchsteuerung
Die Verarbeitung von Massendaten durch einen Batch-Job verläuft meist in mehreren Schritten: Die Verarbeitung einer Datei kann beispielsweise aus ihrer Übertragung auf einen internen Server, ihrer nachfolgenden Prüfung und der Verarbeitung ihres Inhalts bestehen. Diese Verarbeitungsschritte (Batch-Schritte) eines Batch-Jobs bilden eine netzartige Struktur. Jeder Batch-Schritt wird über den Aufruf eines Shell-Skripts gestartet.
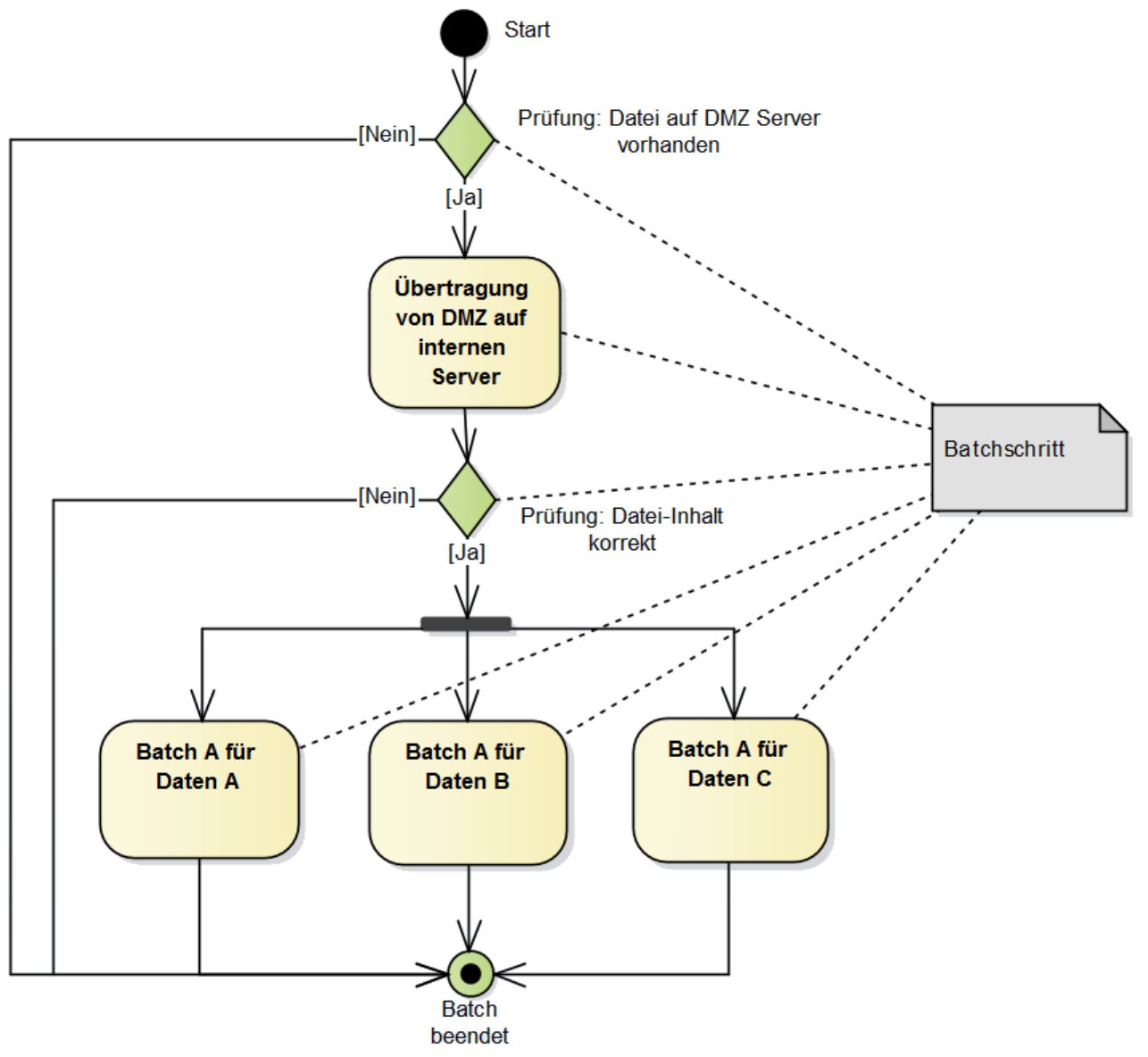
Die meisten Batch-Schritte sind keine IT-Systeme: Sie werden komplett über ein Skript umgesetzt. Nur die Schritte, welche die Verarbeitung durchführen, sind IT-Systeme und besitzen eine Implementierung gemäß der Referenzarchitektur Batch. Im Beispiel wird die Verarbeitung durch drei Batch-Schritte parallel durchgeführt. Alle drei verwenden Instanzen desselben IT-Systems (Batches), arbeiten aber auf anderen Daten.
Ein Batch-Job wird durch eine Batchsteuerung (job scheduler) gesteuert. Ein Batch-Schritt ist dabei das Skript, das vom Scheduler aufgerufen wird. Die Konfiguration eines Batch-Schrittes enthält stets eine Batch-ID, welche den Batch-Schritt eindeutig identifiziert. Das bedeutet, dass jeder der drei Batch-Schritte im Beispiel eine eigene Batch-ID erhält, obwohl alle drei Batch-Schritte Instanzen desselben IT-Systems (Batches) verwenden. Der Grund ist, dass jeder Batch-Schritt auf einem anderen Nummernkreis arbeitet und somit die Batch-Schritte eindeutig identifizierbar sein müssen.