Verfügbarkeit
Die IsyFact berücksichtigt die folgenden Anforderungen an die Verfügbarkeit von Services in Systemlandschaften.
Hohe Verfügbarkeit: Die IT-Systeme der Systemlandschaft müssen eine hohe Verfügbarkeit aufweisen. Die Berechnung der Verfügbarkeit einer Anwendung ist komplex. In die Berechnung fließen unter anderem betriebliche Aspekte wie Hardwareverfügbarkeit ein, während Wartungsfenster herausgerechnet werden. Weiter könnte man Verfügbarkeit auf der Ebene von angebotenen Services und nicht von IT-Systemen betrachten. Von der Seite der Software ist zu beachten, dass sich in einer serviceorientierten Systemlandschaft die Ausfallwahrscheinlichkeiten multiplizieren, wenn Systeme einander aufrufen.
Schnelles Antwortzeitverhalten im Fehlerfall: Die Nichtverfügbarkeit von Services ist ein Ausnahmefall, auf den angemessen reagiert werden muss. Sollte ein Service nicht verfügbar sein, ist es wichtig, dass das aufrufende IT-System zügig eine Fehlermeldung erhält. Speziell bei Online-Anwendungen ist der schnelle Erhalt einer Fehlermeldung notwendig. Der Nutzer soll auch im Fehlerfall eine gewohnt schnelle Antwort vom System erhalten. Die genaue Definition des Zeitrahmens, in dem die Fehlermeldung über die Nichtverfügbarkeit beim Aufrufer eintreffen muss, ist anwendungsspezifisch. Die Definition ist dementsprechend durch die jeweiligen Aufrufer vorzunehmen.
1. Definition und Messung
Die Verfügbarkeit (availability) eines Systems oder einer individuellen Systemkomponente ist definiert als der Prozentsatz eines Zeitraums, in welcher es ordnungsgemäß nach gesetzten Performance-Kriterien läuft (vgl. Oracle: Definition von Availability).
Das grundlegende Performance-Kriterium eines IT-Systems ist dessen korrekter Zustand und dessen Erreichbarkeit. Daher sind Health-Checks essenziell dafür, die Verfügbarkeit zu berechnen.
Diskussion und Anmerkung:
-
"Definierter Zeitraum": Eine Messung über einen Zeitraum von einer Woche, einem Monat oder bis zu mehreren Jahren kann bestimmt werden. Dieser kann gegliedert in abgetrennte Zeiträume erfolgen, oder jeweils den letzten zurückliegenden Zeitraum betreffen. Dieser ist wie die Performanz-Kriterien anwendungsspezifisch festzulegen.
-
Verfügbarkeit in Spring Boot: In Spring Boot ist keine Definition von Verfügbarkeit gegeben. Liveness und Readiness wird stattdessen unter Availability zusammengefasst (vgl. Spring Boot AvailabilityState).
-
Bedeutung der Definition: Es werden nicht-funktionale Anforderungen als Kriterien für Verfügbarkeit gesetzt. Diese stellen Anforderungen an die IT-Systeme, auf welche diese verwendet wird, dar. Die nicht-funktionalen Anforderungen, aus deren Erfüllung sich die Verfügbarkeit ableitet, können nicht von den Standards vorgegeben werden. Sie müssen von der jeweiligen Anwendung vorgegeben werden, da für diese unterschiedlichen Bedürfnisse an die Verfügbarkeit der jeweiligen Anwendung bestehen. Sind die nicht-funktionalen Kriterien erfüllt, dann ist die Anwendung bzw. das IT-System verfügbar (available). Verfügbarkeit als Messung des available-Zustands über die Zeit stellt entsprechend dar, in welchem zeitlichen Umfang die nicht-funktionalen Kriterien erfüllt sind.
-
Praktischer Nutzen der Messung: Verfügbarkeit wird zur quantitativen Messung der Resilienz eines Systems und der Feststellung des Erreichungsgrads eines angestrebten Resilienz-Ziels genutzt (vgl. aws: Berechnung von Availability).
1.1. Messung und Ausfallsicherheit
Die Verfügbarkeit wird unter Berücksichtigung von definierten Betriebs- und Wartungsfenstern gemessen. Die folgende Grafik gibt einen Überblick, was bei der Messung der Verfügbarkeit zu berücksichtigen ist.
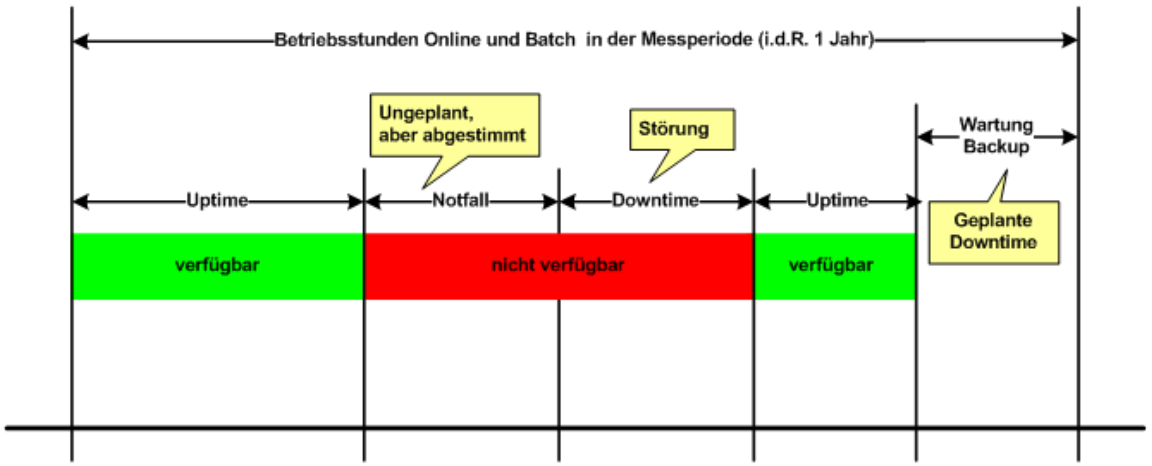
Der Aufbau der Produktionsumgebung ist so zu gestalten, dass die angestrebte Verfügbarkeit erreicht werden kann.
| Dies kann beispielsweise eine Verfügbarkeit von 7x24 Stunden und eine auf den Monat berechnete Verfügbarkeit von über 99 % sein. |
In der Produktionsumgebung einer IsyFact-Systemlandschaft wird die geforderte Verfügbarkeit über das Mittel der Redundanz realisiert. Jede Komponente der technischen Infrastruktur ist mehrfach vorhanden. Bei einem Ausfall einer Komponente kann der Wirkbetrieb immer noch über die andere Komponente abgewickelt werden (Failover). Die Zustandslosigkeit der Applikationsserver unterstützt diese Redundanz und das Failover. Beim Ausfall eines Applikationsservers gehen die notwendigen Informationen, um den Betrieb über einen anderen Applikationsserver abzuwickeln, nicht verloren.
Neben der technischen Redundanz sollte auch eine räumliche Redundanz gegeben sein. Die Komponenten der technischen Infrastruktur sollten über mehrere Rechenzentren redundant verteilt sein. Dadurch ist die Verfügbarkeit auch in Katastrophen-Szenarien (z.B. einem Brand in einem Rechenzentrum) sichergestellt.
1.2. Beispielszenario
Für das Szenario gehen wir im Folgenden davon aus, dass ein IT-System eine Gesamtverfügbarkeit von 98 % aufweisen soll. Hierbei ist zu beachten, dass IT-Systeme in der Regel andere IT-Systeme aufrufen, um Anfragen zu beantworten. Die Gesamtverfügbarkeit sinkt dadurch ab, da zur erfolgreichen Bearbeitung einer Anfrage alle Systeme zeitgleich verfügbar sein müssen. Im Szenario wird für alle Systeme ein Richtwert für die Verfügbarkeit von 99,7 % angenommen. Wie die Beispielrechnung der Verfügbarkeit zeigt, ergibt sich eine Gesamtverfügbarkeit von über 98 % bei einer Verfügbarkeit von 99,7 % pro System.
Eine Berechnung der Gesamtverfügbarkeit nach diesem Schema muss für jedes IT-System einzeln durchgeführt werden. Dabei müssen die berechneten oder gemessenen Verfügbarkeiten aller IT-Systeme zugrunde gelegt werden, die das IT-System aufruft.
| System | Verfügbarkeit |
|---|---|
IT-System |
99,7 % |
Aufgerufenes IT-System 1 |
99,7 % |
Aufgerufenes IT-System 2 |
99,7 % |
Aufgerufenes IT-System 3 |
99,7 % |
Service-Gateway (Infrastruktur) |
99,7 % |
Datenbank (Infrastruktur) |
99,7 % |
Gesamtverfügbarkeit |
(99,7 %)6 = 98,21 % |
2. Ursachen für Nichtverfügbarkeit
Die möglichen Ursachen für Nichtverfügbarkeit sind unter anderem:
Deployment eines IT-Systems: Bei einem Re-Deployment eines IT-Systems kommt es zu einer geplanten Auszeit.
Überlastung während Lastspitzen: Im Tagesverlauf variiert die Last, die ein System verarbeiten muss. Manche Systeme antworten bei Lastspitzen zu langsam.
Ausfall von Hard- oder Software: Auf einem Knoten eines Anwendungsclusters ist eine Störung durch einen Hardware- oder Softwareausfall aufgetreten. Der nicht funktionierende Knoten ist dadurch temporär nicht verfügbar, wodurch die verbleibenden Knoten die Last des ausgefallenen Knotens mitverarbeiten müssen.
Umschaltzeit bei Hard- oder Softwareausfall: Bei Ausfall von Hard- oder Software sorgt ein Loadbalancer dafür, dass alle Anfragen nur an die noch funktionierenden Knoten weitergeleitet werden. In dem kurzen Zeitraum, bis der Loadbalancer einen Server-Knoten als ausgefallen markiert ("Umschaltzeit"), kommt es jedoch zur Nichtverfügbarkeit von Services. In diesem Zeitraum werden Anfragen nicht beantwortet die noch an den ausgefallenen Knoten geleitet werden.
|
Die Regeln, nach denen der Loadbalancer entscheidet, wann ein Server-Knoten nicht mehr verfügbar ist, können üblicherweise konfiguriert werden. Beispielsweise kann ein Loadbalancer alle paar Sekunden per Script ("Health-Check") überprüfen, ob ein Server-Knoten noch verfügbar ist. Erst nach einer festgelegten Anzahl fehlgeschlagener fachlicher Anfragen und negativem Health-Check leitet dann der Loadbalancer keine Anfragen mehr an diesen Knoten. Unabhängig von der Konfiguration kann es trotz Loadbalancer und Anwendungscluster zu wenigen nicht beantworteten Anfragen und somit zu einer Nichtverfügbarkeit kommen. |
Lang laufende Batches: Wenn lang laufende Batches durchgeführt werden, dürfen in dieser Zeit u.U. keine Daten von außerhalb des Batches aus geschrieben werden, um Dateninkonsistenzen zu vermeiden. Schreibende Services sind in dieser Zeit u.U. nicht verfügbar. Aufrufe werden von den Backends der Anwendung mit einer entsprechenden Fehlermeldung beantwortet.
Retries des Loadbalancers: Tritt ein Ausfall von Hard- oder Software auf (siehe Ausfall von Hard- oder Software oben), bekommt der Loadbalancer beim Weiterleiten einer Anfrage an einen ausgefallenen Knoten ein Timeout. Loadbalancer können so konfiguriert werden, dass sie in diesem Fall die gleiche Anfrage an einen noch funktionierenden Knoten weiterleiten und nicht sofort eine Fehlermeldung an den Aufrufer zurückgeben. Für den Aufrufer hat der Service dadurch eine längere Antwortzeit. Der Aufrufer hat keine Möglichkeit dieses Timeout/Retry-Verhalten des Loadbalancers zu beeinflussen und auf seine Bedürfnisse anzupassen. Die lange Antwortzeit kann aufseiten des Aufrufers leicht zu einem Timeout führen.
Verschlimmerung von Nichtverfügbarkeiten: Das aufrufende IT-System reagiert nicht angemessen auf eine Nichtverfügbarkeit eines Service.
Beispiele:
-
Der Client versucht Retries, obwohl der Service-Aufruf aus fachlicher Sicht entfallen könnte (optionaler Aufruf).
-
Die fachliche Verarbeitung wird nicht rechtzeitig abgebrochen, obwohl ein verpflichtender Service-Aufruf bereits fehlgeschlagen ist.
-
Die Bearbeitung der Anfrage dauert bekanntermaßen beim Service-Anbieter sehr lange. Der Aufrufer hat einen sehr knappen Timeout gesetzt und schickt Aufrufwiederholungen. Dies verschlimmert die Antwortzeiten der Service-Aufrufe und führt eventuell zu Duplikaten beim Service-Anbieter.
Eine weitere bekannte Ursache für Nichtverfügbarkeit ist die Umgebungskonfiguration, Firewall-Verbindungen nach einer definierten Zeit automatisch zu schließen. Zustandsbehaftete Verbindungen wie sie bei Datenbank-Clients eingesetzt werden, sind von dieser Restriktion betroffen. Diese Clients müssen vorsehen, dass Sie eine von der Firewall geschlossene Verbindung erkennen und wieder neu aufbauen.
Die IsyFact setzt als Transportprotokoll, vor allem für das Kommunikationsmuster Request-Response, HTTP ein. HTTP ist ein zustandsloses Protokoll und baut bei jeder Anfrage eine neue Verbindung zwischen Client und Server auf. HTTP 1.1 bietet einen Mechanismus an, mehrere Anfragen über eine TCP-Verbindung zu transportieren. Wenn eine Schnittstellentechnologie diesen Mechanismus nutzt, müssen die TCP-Verbindungen vor ihrer Verwendung validiert werden.
3. Maßnahmen
Folgende Maßnahmen können ergriffen werden, um die Anforderungen an die Verfügbarkeit zu gewährleisten.
3.1. Anwendungscluster mit Loadbalancer
Die TI-Architektur der IsyFact setzt die hohen Verfügbarkeitsanforderungen durch Clustering der Applikations- und Datenbankserver um. IT-Systeme einer Anwendung werden redundant auf mehr als einem Server installiert. Kommt es zu einem Hard- oder Softwareausfall auf einem Server-Knoten, so werden alle Anfragen von einem vorgeschalteten Loadbalancer auf einen anderen Server-Knoten umgeleitet. Durch die Redundanz wird die Verfügbarkeit von Services bei auftretenden Hard- oder Softwareausfällen erhöht. Trotzdem kann es auch hier noch zu Nichtverfügbarkeit kommen.
3.2. Knotenweises Deployment
Diese Maßnahme hilft bei Nichtverfügbarkeit aufgrund von geplanten Wartungsarbeiten. Im Cluster-Betrieb besteht die Möglichkeit, diese Knoten für Knoten auszuführen. Bevor das Deployment auf einem Knoten ausgeführt wird, wird dem Loadbalancer mitgeteilt, dass der Knoten nicht mehr verfügbar ist. Während des Deployments des Knotens verarbeiten die restlichen Knoten alle ankommenden Anfragen. Nach Abschluss des Deployments des Knotens wird dem Loadbalancer mitgeteilt, dass der Knoten wieder zur Verfügung steht. Dann kann das Deployment des nächsten Knotens nach dem gleichen Schema erfolgen. Dadurch können Services im Zeitraum von Wartungsarbeiten voll verfügbar gehalten werden.
3.3. Time-To-Live
Ein Service-Aufruf ist nur für eine bestimmte Zeit gültig. Diese Zeitspanne wird als Time-To-Live (TTL) bezeichnet. Der Aufrufer definiert die TTL und legt so fest, wie lange er bei einem Aufruf auf eine Antwort wartet. Hierdurch wird eine schnelle Antwortzeit gewährleistet.
3.4. Aufrufwiederholung (Retry)
Durch Loadbalancer ausgeführte Retries können zu einer Erhöhung der Antwortzeit führen. Loadbalancer innerhalb der Plattform sind deshalb so zu konfigurieren, dass fehlgeschlagene Anfragen nicht an andere Knoten weitergeleitet werden. Eine Wiederholung von Aufrufen ist ausschließlich vom Aufrufer auszuführen. So kann der Aufrufer je nach Fachlichkeit entscheiden, bei welchen Anfragen Wiederholungen sinnvoll sind.
Grundsätzlich sind Retries nur mit größter Vorsicht anzuwenden! Hierfür gibt es mehrere Gründe:
Ruft ein Client einen Service auf und erhält einen technischen Fehler, so kann der Client anhand des technischen Fehlers in der Regel nicht einwandfrei erkennen, ob seine Anfrage nicht doch auf dem Server erfolgreich verarbeitet wurde. Beispielsweise kann durch einen Netzwerkausfall zwar die Netzwerkverbindung zum Server abgebrochen sein, das hindert den Server aber nicht daran, eine bereits in Verarbeitung befindliche Service-Anfrage weiterzuverarbeiten. In einem solchen Fall würde ein automatischer Retry dazu führen, dass ein und dieselbe Service-Anfrage zweimal ausgeführt würde. Dies kann bei nicht-idempotenten Service-Operationen fatale Auswirkungen haben (z. B. Löschen von falschen Daten).
Eine automatische Aufrufwiederholung kann im Falle einer echten Nichtverfügbarkeit zu einer erhöhten Netzwerklast führen und so die Nichtverfügbarkeit auch anderer Anwendungen in der Anwendungslandschaft erhöhen. Die Situation wird daher durch die Aufrufwiederholung deutlich verschlechtert.
Insbesondere bei einem Timeout eines TTL ist jedoch ein Retry mit großer Vorsicht zu genießen, da nicht klar ist, ob die Service-Anfrage nicht doch durch den Server bearbeitet wird. In einem solchen Fall führt eine Aufrufwiederholung zu einer erhöhten Last auf dem Server und kann im schlechtesten Fall zu einer echten Nichtverfügbarkeit des Services bzw. des kompletten Servers führen.
|
In Anbetracht der potenziellen Probleme der Aufrufwiederholung und der Tatsache, dass eine Aufrufwiederholung nur für idempotente Service-Operationen überhaupt zulässig ist, sollte von einer automatischen Aufrufwiederholung als Maßnahme zur Erhöhung der Verfügbarkeit in der Regel abgesehen werden. Ausgenommen davon sind Aufrufe, bei denen nur Daten gelesen werden, wie z. B. Suchen im Suchverfahren oder Abfragen von Verzeichnissen wie Schlüsselverzeichnis, Benutzerverzeichnis oder Behördenverzeichnis. Hierfür soll grundsätzlich eine Aufrufwiederholung durchgeführt werden. Diese ist sinnvoll über die folgenden Parameter konfigurierbar:
Die Parameter sind Bestandteil der betrieblichen Konfiguration. |
3.5. Deaktivierung von Services
Aufgrund von Wartungsaktivitäten oder Batches (z. B. einer Datenmigration) in einer Anwendung kann es vorkommen, dass schreibende Services ihrer Backends vorübergehend deaktiviert werden. Lesende Services können während dieser Zeit regulär ausgeführt werden. Während die schreibenden Services deaktiviert sind, wird dem Aufrufer eine entsprechende Fehlermeldung zurückgesendet. Da die Anforderung besteht, auch lesende Services vorübergehend deaktivieren zu können, werden generell alle Services deaktivierbar gemacht.