Tutorial
1. Einleitung
Dieses Dokument dient als Einstieg in die technischen Grundlagen der IsyFact. Es enthält in Kurzform die wesentlichen Designvorgaben und beschreibt, wie einzelne Aspekte in Anwendungen umzusetzen sind, die gemäß der Referenzarchitektur der IsyFact gebaut werden. Das Dokument unterstützt damit Entwickler und technische Chefdesigner bei der Konstruktion und Realisierung von Anwendungen einer zur IsyFact konformen Anwendungslandschaft. Im Sinne einer Referenz enthält es jedoch nicht alle Details der zugrunde liegenden Konzepte. Der Fokus liegt darauf, einen schnellen Überblick über die einzelnen Themen zu geben und die wichtigsten Realisierungsaufgaben zusammenfassend darzustellen.
Zunächst beschreibt das Kapitel Bezug IsyFact, wie sich die IsyFact in Entwicklungsprojekte einbinden lässt. Danach beleuchten die Kapitel Datenhaltung , Fachkomponenten der Anwendung und Batch-Verarbeitung jeweils Themen der Anwendungsentwicklung. Kapitel Querschnitt fasst alle Querschnittsthemen zusammen. Jedes Teilkapitel beginnt in der Regel mit der Auflistung der wichtigsten Designvorgaben und einem Klassendiagramm. Es folgt eine Realisierungsanleitung, die alle wesentlichen Schritte zur Umsetzung in Kurzform enthält.
2. Bezug und Nutzung der IsyFact
Alle Bibliotheken der IsyFact stehen über Maven Central zum Download bereit.
Zur Nutzung der Bibliotheken in der Anwendungsentwicklung steht ein zentrales BOM (Bill Of Materials) zur Verfügung, das Teil der Maven-Konfiguration (pom.xml) wird:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>de.bund.bva.isyfact</groupId>
<artifactId>isyfact-standards-bom</artifactId>
<version>5.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Somit kann zentral eine zu nutzende Version der IsyFact festgelegt werden. Diese legt über das darin enthaltene IsyFact-Products-BOM auch die Versionen aller Drittprodukte fest, die im Produktkatalog der IsyFact enthalten sind. Aktualisierungen geschehen zentral, durch die Erhöhung der Versionsnummer des IsyFact-Standards-BOM.
Durch die Nutzung des IsyFact-Standards-BOM ist es nicht mehr notwendig, die IsyFact-Bibliotheken mit einzelnen Versionsnummern einzubinden. Die Versionsnummer ermittelt Maven zentral über das BOM. Es reicht also folgender Abschnitt, um eine Bibliothek einzubinden:
<dependencies>
...
<dependency>
<groupId>de.bund.bva.isyfact</groupId>
<artifactId>isy-logging</artifactId>
</dependency>
...
</dependencies>3. Datenhaltung
In diesem Kapitel wird die Implementierung der Datenhaltung einer Anwendung beschrieben. Die Datenhaltung besteht im Wesentlichen aus den Entitäten (Entity) und den zugehörigen Data Access Objects (DAOs). Alle Konzepte und Vorgaben zum Thema Persistenz stehen in der Referenzarchitektur.
3.1. Designvorgaben
-
Der eigentliche Datenbankzugriff wird über die Java Persistence API (JPA) gekapselt. Als Implementierung für die JPA wird Hibernate verwendet.
-
Das Datenbank-Mapping wird über Annotation in den Klassen der Entitäten festgelegt.
-
Der Zugriff auf Entitäten erfolgt immer über DAOs oder durch die Traversierung des persistenten Datenmodells.
-
DAOs stellen Zugriffsmethoden (Suchen, Schreiben, Löschen …) für genau eine Entität bereit.
-
Datenbank-Queries werden im Normalfall aus den Methodennamen generiert. Sonst werden sie per
@Query-Annotation an der Methode beschrieben. -
Entitäten werden von genau einer fachlichen Komponente verwaltet.
-
Der Datenzugriff erfolgt über die Komponenten-Schnittstelle.
-
Für persistente Entitäten, die über eine Komponentenschnittstelle angeboten werden, werden eigene Schnittstellenobjekte definiert, die per Deep-Copy gefüllt werden. Hierfür wird ein Bean-Mapper verwendet. Innerhalb einer Teilanwendung dürfen persistente Entitäten allerdings über Komponentengrenzen hinweg genutzt werden.
-
DAOs und Entitäten werden in einer festgelegten Paketstruktur abgelegt.
Aspect-Oriented Programming (AOP) ist ein Programmierparadigma, das anstrebt, verschiedene logische Aspekte eines Programmes getrennt voneinander zu entwerfen, zu entwickeln und zu testen. Die getrennt entwickelten Aspekte werden dann zur endgültigen Anwendung zusammengefügt. * Der Primärschlüssel einer Entität besteht aus genau einem Attribut. Besteht der fachliche Schlüssel der Entität aus genau einem Attribut, so wird er auch als Primärschlüssel verwendet. Ansonsten wird ein künstlicher technischer Primärschlüssel verwendet.
3.2. Realisierung
Zur Realisierung der Datenhaltung müssen folgende Aktivitäten durchgeführt werden.
3.2.1. Anlegen des Datenbankschemas
Das Datenbankschema muss angelegt werden. Dazu werden die benötigten DDL-Anweisungen, wie in Versionierung von Datenbankschemas beschrieben, in einem Verzeichnis abgelegt.
Das initiale Datenmodell kann über das Tool hbm2ddl erzeugt werden.
Dieses muss anschließend noch bearbeitet werden.
hbm2ddl ist Teil der von Hibernate bereitgestellten Werkzeuge.
Nutzungsdokumentation unter:
Hibernate Toolset Guide
|
3.2.2. Einbinden der Bibliotheken
Die benötigten Bibliotheken müssen als Abhängigkeiten in die Maven-Konfiguration (pom.xml) aufgenommen werden:
<dependencies>
...
<dependency>
<groupId>de.bund.bva.isyfact</groupId>
<artifactId>isy-persistence</artifactId>
</dependency>
...
</dependencies>3.2.3. Implementierung der Entitätsklassen und DAOs
Die Entitätsklassen und Schnittstellen-Klassen müssen implementiert werden. In den Entitätsklassen müssen die Mapping-Informationen für JPA als Annotationen eingetragen werden. Die Implementierung der DAOs wird automatisch generiert.
3.2.4. Implementierung von Schnittstellen-Klassen
Schnittstellen-Klassen dienen als eine nur Lese-Sicht auf persistente Entitäten. Dieses wird benötigt, wenn Komponenten persistente Entitäten über ihre Schnittstelle herausgeben, um zu verhindern, dass andere Komponenten diese Daten ändern.
Schnittstellen-Klassen enthalten alle Attribute, die auch ihre persistenten Gegenstücke besitzen. Zusätzlich besitzen sie Getter-/Settermethoden für alle Attribute.
Die Schnittstellen-Objekte werden per Deep-Copy mittels eines Bean-Mappers erzeugt und dem Aufrufer außerhalb der Teilanwendung zurückgeliefert. So stehen dem Aufrufer alle Informationen zur Verfügung, es ist ihm aber nicht möglich, Änderungen zu persistieren. Damit ist die Datenhoheit der Komponente gewahrt.
Im Folgenden ist ein beispielhaftes Mapping zu sehen:
/* Bean-Mapper */
protected MapperFacade mapper;
// Entität mappen
RegisterEintragDaten daten = mapper.map(registerEintrag, RegisterEintragDaten.class);4. Fachkomponenten der Anwendung
In diesem Kapitel wird die Realisierung von Fachkomponenten beschrieben.
4.1. Designvorgaben
-
Alle Komponenten definieren ihre Schnittstelle über ein Java-Interface.
-
Komponenten bieten an ihrer Schnittstelle eine Nur-Lese-Sicht auf ihre Daten an. Für jeden Entitätstyp wird eine nicht-persistente Schnittstellenklasse erstellt. Die Komponentenschnittstelle wird von einer Java-Klasse implementiert. Diese Klasse kann die Anwendungsfälle im einfachen Fall direkt implementieren oder an Anwendungsfall-Klassen delegieren.
-
Die interne Strukturierung von Komponenten ist nicht im Detail vorgeben. Für fachliche Komponenten wird eine Basisimplementierung im Anwendungskern beschrieben.
4.2. Klassendesign
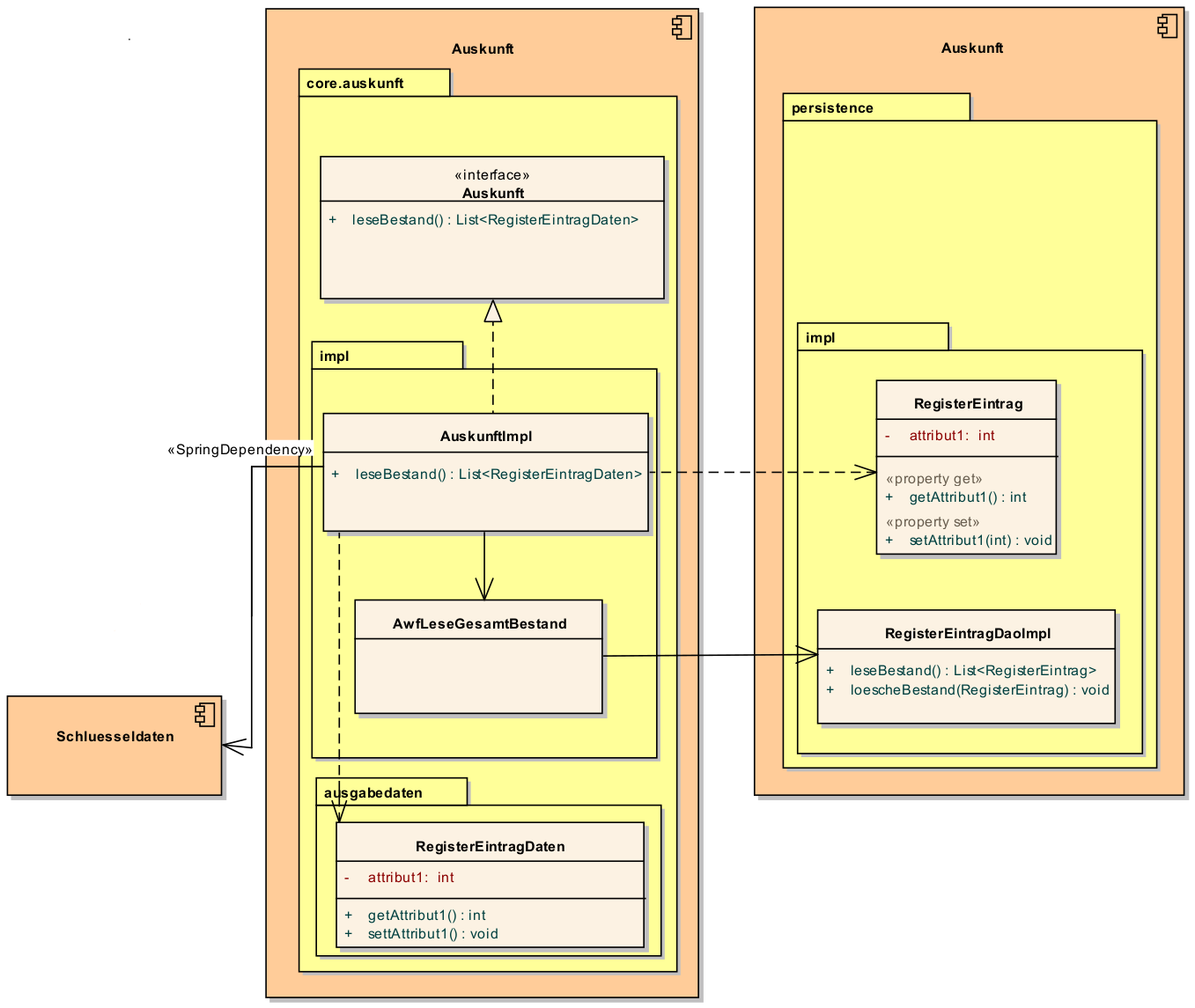
Auskunft |
Interfaces zur Definition der Schnittstelle der Komponente "Auskunft". |
AuskunftImpl |
Implementierung der Komponente |
AwfLeseGesamtBestand |
Beispielklasse zur Implementierung eines Anwendungsfalls. Diese Klassen werden explizit instanziiert, also nicht als Spring Bean konfiguriert. Falls ein Anwendungsfall weitere Komponenten (Konfiguration, Regelwerk) etc. benötigt, werden diese durch die instanziierende Impl-Klasse übergeben. |
RegisterEintrag |
Persistente Entität für Register-Einträge. |
RegisterEintragDaten |
Nur-Lese-Sicht auf Register-Einträge (siehe Kapitel Implementierung von Schnittstellen-Klassen). |
4.3. Package-Struktur
-
Die Realisierung der Komponenten-Schnittstelle erfolgt im Package
<organisation>.<domäne>.<system>.core.<komponente>Für das Bundesverwaltungsamt ist dies z.B. de.bund.bva -
Die Realisierung der Komponenten-Implementierung erfolgt im Package
<organisation>.<domäne>.<system>.core.<komponente>.impl.* -
Die nicht-persistenten Schnittstellen-Klassen werden im Package
<organisation>.<domäne>.<system>.core.<komponente>.ausgabedaten.*
implementiert.
4.4. Realisierung
-
Die Implementierungsklassen und Interfaces der Komponente werden implementiert.
-
Die Komponente mit
@Componentbzw. mit einer passenden Spezialisierung annotiert, damit sie von Spring als Bean konfiguriert wird. -
Je nach Bedarf wird die Komponente anderen Komponenten per Dependency Injection bekannt gemacht.
5. Batch-Verarbeitung
In diesem Kapitel wird die Implementierung von Batches zu einer Anwendung beschrieben.
5.1. Designvorgaben
-
Die Batch-Verarbeitung verwendet den Anwendungskern der zugehörigen Anwendung. Der Anwendungskern ist Teil des Batch-Deployments, d.h. der Code ist sowohl Teil der Server-Anwendung als auch der Batch-Anwendung in Bezug auf Deploymenteinheiten.
-
Zur Realisierung der Batchlogik wird eine Batch-Ausführungs-Bean implementiert.
-
Falls für die Verarbeitung im Batch eigene Geschäftslogik benötigt wird, ist diese trotzdem den entsprechenden Anwendungskomponenten der zugehörigen Geschäftsanwendung hinzuzufügen.
-
Im Rahmen der Initialisierung hat die Ausführungs-Bean unter anderem die Aufgabe, die Konsistenz und Korrektheit der Eingabedaten zu prüfen.
-
Falls die zu verarbeitenden Sätze eines Batches das Ergebnis einer Datenbank-Query sind, ist in der Initialisierung die Query über eine Anwendungskomponente der zugehörigen Geschäftsanwendung abzusetzen. Diese Query soll die (fachlichen) Schlüssel von Entitäten, nicht Entitäten selbst auslesen.
-
Die Batches sind möglichst robust zu konstruieren: Falls auf ein fachliches Problem in der Ausführungs-Bean reagiert werden kann, sollte dies getan werden.
-
Batches erzeugen ein Ausführungsprotokoll. Der Batchrahmen, die Steuerungsimplementierung, die jeden Batch und dessen Arbeitsschritte steuert, stellt die notwendige Implementierung bereit. Die Ausführungs-Bean übermittelt dem Batchrahmen Status-Informationen für das Protokoll.
-
Batches verwenden einen (konfigurierten) technischen Benutzer, um sich vor Start der fachlichen Verarbeitung am IAM-Service der Anwendung oder der Anwendungslandschaft zu authentifizieren.
-
Alle Batches zu einer Anwendung werden als eigenständige Deployment-Einheit ausgeliefert.
5.2. Klassendesign
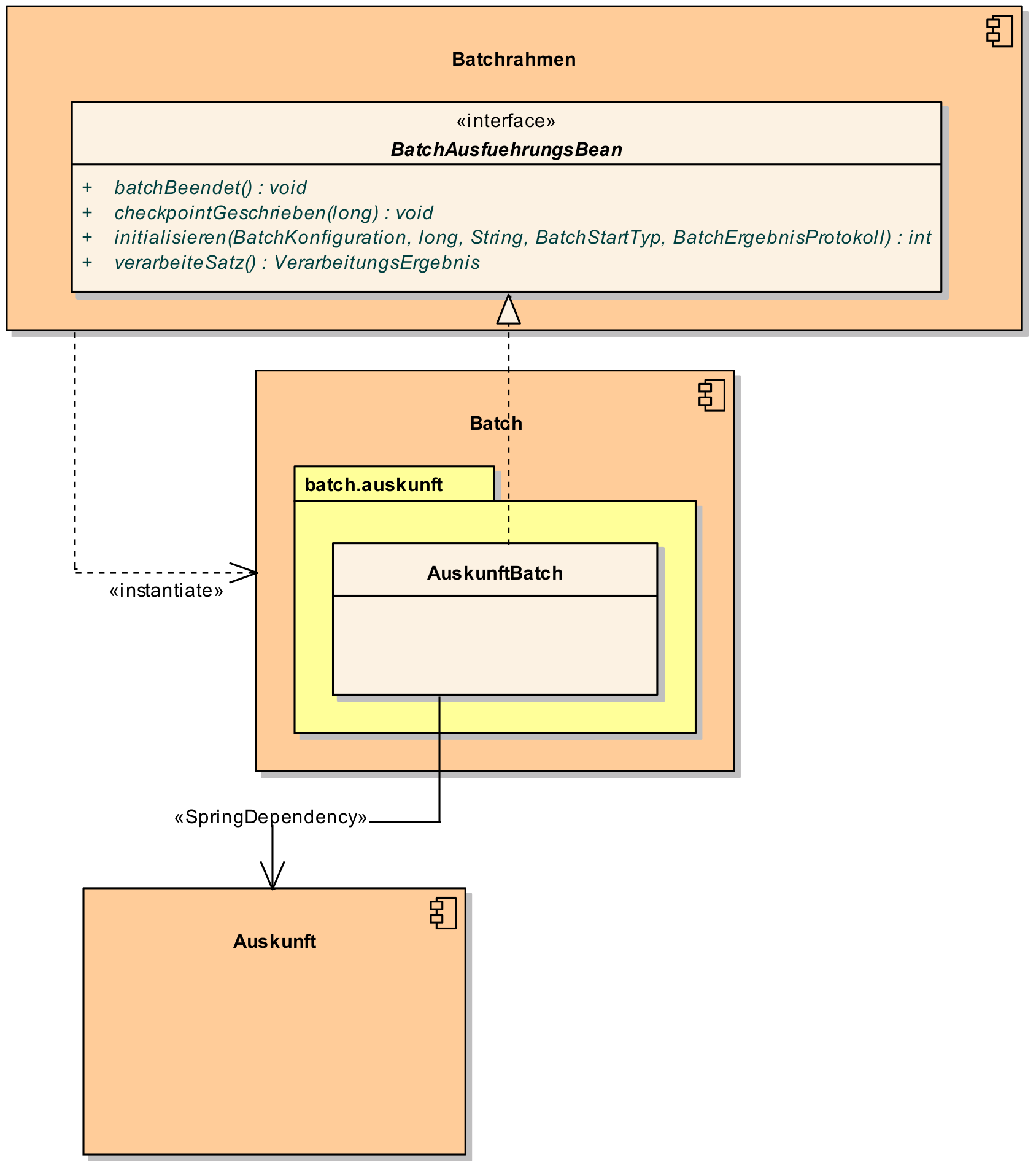
Abbildung 2 zeigt eine beispielhafte Implementierung eines Batches, der die Komponente Auskunft verwendet.
Der Batchrahmen definiert das Interface BatchAusfuehrungsBean. Dieses dient der Steuerung des Batches durch den Batchrahmen.
Es muss vom Batch implementiert werden.
Der Batchrahmen sorgt auch für die Initialisierung und Ausführung des Batches.
Der Batchrahmen übernimmt die Transaktionssteuerung. Die Transaktionssteuerung im Batch sieht vor, mehrere Arbeitsschritte in einer Transaktion abzuwickeln. Die Größe der Transaktion (Commit-Rate) wird über den Batchrahmen konfiguriert.
5.3. Realisierung
5.3.1. Einbinden der Bibliothek
Zur Realisierung von Batches muss die in Listing 5 aufgelistete Bibliothek eingebunden werden.
<dependencies>
...
<dependency>
<groupId>de.bund.bva.isyfact</groupId>
<artifactId>isy-batchrahmen</artifactId>
</dependency>
...
</dependencies>5.3.2. Implementierung der Batch-Logik
Die Batch-Logik wird implementiert, in dem eine Batch-Bean im Package <organisation>.<domäne>.<anwendung>.batch implementiert wird.
Für die Realisierung ist es notwendig, dass die Batch-Bean das Interface BatchAusfuehrungsBean aus der Bibliothek isy-batchrahmen implementiert.
Der Batchrahmen ruft als Erstes die Methode initialisieren auf.
Dabei werden alle zur Initialisierung benötigten Informationen übergeben.
Details dazu werden im JavaDoc der Methode beschrieben.
Der Parameter BatchErgebnisProtokoll enthält eine Referenz auf ein Protokollobjekt, welches der Batch verwendet, um Protokoll-Meldungen und Statistiken an den Batchrahmen zu übergeben.
5.3.3. Konfiguration des Batches und Batchrahmens
Für jeden Batch muss eine Property-Datei in /src/main/resources/resources/batch angelegt werden.
In dieser statischen Konfiguration werden unter anderem die Batch-ID und die Transaktionssteuerung konfiguriert.
Eine Beschreibung der Parameter ist im Batchrahmen enthalten.
Die betriebliche Konfiguration des Batches ist identisch zu derjenigen der zugehörigen Anwendung. Auch Parameter, die nur für den Batch benötigt werden, werden in die betriebliche Konfiguration der Geschäftsanwendung aufgenommen.
5.3.4. Spring-Konfiguration anlegen
Für den Batchrahmen werden in der Konfigurationsklasse der Batch-Schicht die Spring Beans des Batchrahmens und für jeden existierenden Batch die Ausführungs-Bean als Spring Bean definiert.
Zusätzlich müssen folgende Beans erstellt werden:
-
Eine Bean vom Typ
BatchRahmenMBeanzur Überwachung des Batchrahmens. Diese muss über den Spring MBeanExporter exportiert werden. -
Eine Bean für einen
JpaTransactionManager. -
Die Konfigurationsklasse der Batch-Schicht muss mit der Annotation
@EntityScan("de.bund.bva.isyfact.batchrahmen.persistence.rahmen")versehen werden, damit die Entitäten des Batchrahmens gefunden werden.
Die Spring-Konfiguration der Anwendung kann auch für den Batches verwendet werden.
Dazu müssen Beans, die nicht für Ausführung eines Batches instanziiert werden sollen, mit
@ExcludeFromBatchContext annotiert werden.
5.3.5. Konfiguration des Batch-Deployments
Für das Deployment des Batches wird ein neues Maven-Projekt <system>-batch angelegt.
Dieses hat die Aufgabe das Deployment-Paket für den Batch zusammenzustellen.
Dazu wird eine neue pom.xml angelegt, die als Ziel-Typ ein Jar mit allen Dateien des Batches erzeugt. Zusätzlich können in diesem Projekt Shell-Skripte und ähnliches für den Batch abgelegt werden.
Das Batch-Projekt enthält keinen Java-Code. Die Batch-Beans liegen im normalen Anwendungsprojekt.
6. Querschnitt
In diesem Kapitel wird die Umsetzung querschnittlicher Aspekte beschrieben.
6.1. Logging
In diesem Abschnitt wird beschrieben, wie das Logging umzusetzen und zu konfigurieren ist.
6.1.1. Designvorgaben
-
Für Logging wird die Bibliothek
isy-loggingverwendet. -
Es wird ein Debug-, Info- und ein Error-Log geführt. Die Zuordnung der Log-Levels auf diese Log-Arten wird im Dokument Konzept Logging definiert. Ebenso welche Informationen mit welchem Log-Level ausgeben werden sollen.
-
Für das Logging wird die im Rahmen der IsyFact erstellten Layouts für Entwicklung und Produktion verwendet.
-
In jeder Log-Meldung ist eine Correlation-ID mitzuloggen. Diese identifiziert den Aufruf über die Anwendungslandschaft hinweg.
6.1.2. Realisierung
6.1.2.1. Implementierung von Log-Ausgaben
Log-Ausgaben können an beliebigen Stellen im Code erzeugt werden. Dazu wird in jeder Klasse ein eigener Logger erzeugt (Listing 6).
public class MyClass {
...
private static final IsyLoggerStandard LOG = IsyLoggerFactory.getLogger(MyClass.class);
...Der IsyLoggerStandard ist dabei für technisches Logging gedacht.
Je nach Anwendungsszenario sind andere spezifische Logger (IsyLoggerFachdaten, IsyLoggerTypisiert) zu verwenden.
6.1.2.2. Einbinden der Bibliotheken
Um die Logging Funktionen in der eigenen Anwendung nutzen zu können müssen die in Listing 7 aufgelisteten Bibliotheken eingebunden werden.
<dependencies>
...
<dependency>
<groupId>de.bund.bva.isyfact</groupId>
<artifactId>isy-logging</artifactId>
</dependency>
...
</dependencies>Dadurch wird die Bibliothek isy-logging sowie Logback als verwendetes Produkt automatisch in die Anwendung integriert.
6.2. Fehlerbehandlung
In diesem Kapitel wird beschrieben, wie die Fehlerbehandlung durchzuführen ist.
6.2.1. Designvorgaben
-
In jeder Anwendung bzw. Bibliothek wird eine eigene Exception-Hierarchie angelegt.
-
Für Anwendungs-Exceptions wird die oberste Exception dieser Hierarchie von den in der Bibliothek
isy-exception-coreenthaltenen Exception-Klassen abgeleitet. Diese Ober-Exceptions sind als abstrakt zu kennzeichnen. -
Für Exceptions in selbst entwickelten Bibliotheken werden nicht die Exception-Klassen aus
isy-exception-coreverwendet. Die zugrundeliegenden Designprinzipien sind jedoch identisch umzusetzen. So wird für jede Bibliothek eine abstrakte Ober-Exception angelegt. Diese sorgt für das Laden der Nachrichten, erbt aber direkt von einer derjava.lang.Exceptionbzw.java.lang.RuntimeException. -
Fehlertexte werden in Resource-Bundles ausgelagert und über eine Ausnahme-ID identifiziert. Die Schlüssel der Ausnahme-IDs werden in einer Konstantenklasse zusammengefasst.
-
Exceptions werden grundsätzlich nur zur Signalisierung abnormer Ergebnisse bzw. Situationen eingesetzt.
-
Exceptions sind in der Regel zu behandeln und zu loggen. Ist es nicht möglich die Exception zu behandeln, muss sie an den Aufrufer weitergegeben werden. Die Exception wird im Fall eines Weiterwerfens nicht geloggt.
-
Nur Exceptions in Methodensignaturen verwenden, die auch vorkommen können.
-
Bei der Behandlung von Fehlern ist ein geordneter Systemzustand herzustellen, z. B. das Schließen der Datenbankverbindung über einen
finally-Block. -
Fehler sollten möglichst früh erkannt werden und zu entsprechenden Ausnahmen führen.
-
Interne Exceptions dürfen in der Service-Schnittstelle nicht vorkommen.
-
Catch-Blöcke dienen der Fehlerbehandlung und dürfen nicht als
else-Zweige genutzt werden. -
Keine leeren Catch-Blöcke.
-
Das destruktive Wrappen einer Exception zerstört den StackTrace und ist nur für Exceptions an den Außen-Schnittstellen sinnvoll. Destruktiv gewrappte Exceptions sind in jedem Fall vor dem Wrappen zu loggen.
Weitere Hinweise für die richtige Behandlung von Fehlern sind in Konzept Fehlerbehandlung enthalten.
6.2.2. Paketstruktur
Exceptions die querschnittlich, also von mehreren Komponenten genutzt werden, werden im Paket:
<organisation>.<domäne>.<anwendung>.common.exception
<organisation> z.B. bva.bund.de
|
implementiert. Komponentenspezifische Exceptions, also solche die nur von einer einzigen Komponente genutzt werden, gehören in das Paket:
<organisation>.<domäne>.<anwendung>.core.<komponente>
6.2.3. Realisierung
Die Bibliothek enthält anwendungsinterne Exception-Klassen und Hilfsklassen für das Exception-Mapping.
6.2.3.1. Einbinden der Bibliothek
Zur Realisierung der Fehlerbehandlung und Implementierung von Exceptions muss die in Listing 8 aufgelistete Bibliothek eingebunden werden.
<dependencies>
...
<dependency>
<groupId>de.bund.bva.isyfact</groupId>
<artifactId>isy-exception-core</artifactId>
</dependency>
...
</dependencies>isy-exception-core enthält abstrakte Exception-Klassen und Interfaces, die in Anwendungen zu verwenden sind.
6.2.3.2. Anlegen der Exception-Klassen
In jeder Anwendung wird für jede Exception-Art (technisch, fachlich) eine eigene Oberklasse angelegt.
Diese erbt von der entsprechenden Klasse aus isy-exception-core.
Zum Laden der Fehlertexte muss das Interface FehlertextProvider aus derselben Bibliothek implementiert und getMessage überschrieben werden.
Hier empfiehlt sich der Einsatz eines java.util.ResourceBundle, dem als baseName der Pfad zu den Properties übergeben wird.
6.2.3.3. Fehlerbehandlung an der Anwendungsschnittstelle
Fehler sind entweder zu behandeln und zu loggen oder weiter zu werfen. Es muss jedoch sichergestellt werden, dass interne Fehler der Anwendung nicht über die Service-Schnittstelle geworfen werden. Dazu wird an der Service-Schnittstelle eine explizite Fehlerbehandlung durchgeführt.
Alle Exceptions der Anwendungen werden hier in Transport-Exceptions umgewandelt. Dazu wird das im Folgenden beschrieben Muster verwendet.
Es wird ein Catch-Block für alle auftretenden eigenen Exceptions angelegt.
In jedem Catch-Block wird die Exception geloggt und über ExceptionMapper.mapException()
in eine passende Transport-Exception umgewandelt.
Als Letztes wird ein Catch-Throwable-Block eingefügt.
Hier wird für die aufgetretene Exception über ExceptionMapper.createToException()
eine neue Transport-Exception erzeugt.
Zur Ermittlung der Ausnahme-ID wird eine Klasse AusnahmeIdUtil angelegt.
Diese implementiert eine statische Methode getAusnahmeId, die zu einer übergebenen Exception
eine passende Ausnahme-ID ermittelt.
Vor dem Werfen der so erzeugten Exception über die Schnittstelle wird ein Log-Eintrag erzeugt.
Beim Umwandeln der internen Exceptions in Transport-Exceptions wird der Stack-Trace der internen Exceptions verworfen.
6.3. Überwachung
In diesem Abschnitt wird beschrieben, wie die Überwachung einer Anwendung realisiert wird.
| Detaillierte Informationen zur Überwachung sind im Dokument Konzept Überwachung und in Nutzungsvorgaben Überwachung enthalten. |
6.3.1. Designvorgaben
-
Die Erreichbarkeit des Systems wird über einen HealthCheck von Spring Boot Actuator realisiert.
-
Server-Metriken werden anbieterneutral mit Micrometer angeboten.
-
Einzelne Services können detailliert überwacht werden. Dazu stellen die Services Statistiken über ihre Nutzung als Metriken bereit.
-
Zur Steuerung des Loadbalancing ist ein Servlet enthalten, um die Anwendung innerhalb eines Clusters deaktivierbar zu machen.
6.3.2. Realisierung
6.3.2.1. Einbinden der Bibliothek
Zur Realisierung der Überwachung muss die in Listing 9 aufgelistete Bibliothek eingebunden werden.
<dependencies>
...
<dependency>
<groupId>de.bund.bva.isyfact</groupId>
<artifactId>isy-ueberwachung</artifactId>
</dependency>
...
</dependencies>6.3.2.2. Konfiguration der Überwachungsschnittstelle
Der HealthCheck, die Server-Metriken und das Loadbalancing Servlet werden automatisch durch die Verwendung der Bibliothek in die Anwendung eingebunden und aktiviert. Für den HealthCheck muss explizit eine Konfiguration in den Application Properties erfolgen, damit der Health-Status automatisch aktualisiert wird.
Die im Detail zu überwachenden Services müssen explizit konfiguriert werden. Dazu werden die Service-Beans in Service-Statistik-Beans gekapselt, und jeder Service-Aufruf wird durch die Service-Statistik-Beans delegiert. Die Konfiguration besteht aus zwei Teilen:
-
Konfigurieren der Service-Statistik-Beans als Spring Beans.
-
Anbinden der Service-Statistik-Beans an die Service-Beans durch einen AOP-Advice. Dieser Advice wird so konfiguriert, dass bei jedem Aufruf einer Methode der Service-Bean die Statistik-Bean aufgerufen wird.