Nutzungsvorgaben Logging
![]() Diese Seite ist ein Teil der IsyFact-Standards.
Alle Inhalte der Seite, insbesondere Texte und Grafiken, sind urheberrechtlich geschützt.
Alle urheberrechtlichen Nutzungs- und Verwertungsrechte liegen beim Bundesverwaltungsamt.
Diese Seite ist ein Teil der IsyFact-Standards.
Alle Inhalte der Seite, insbesondere Texte und Grafiken, sind urheberrechtlich geschützt.
Alle urheberrechtlichen Nutzungs- und Verwertungsrechte liegen beim Bundesverwaltungsamt.
 Die Nutzung ist unter den Lizenzbedingungen der Creative Commons Namensnennung 4.0 International gestattet.
Die Nutzung ist unter den Lizenzbedingungen der Creative Commons Namensnennung 4.0 International gestattet.
Java Bibliothek / IT-System
| Name | Art | Version |
|---|---|---|
|
Bibliothek |
v3.3.x |
1. Einleitung
Im Dokument Logging - Konzept werden die Anforderungen und Vorgaben für das Logging der IsyFact definiert, um eine einheitliche Umsetzung in der gesamten Anwendungslandschaft zu gewährleisten.
Das vorliegende Dokument beschreibt alle Aspekte, die bei der Entwicklung einer Anwendung zu berücksichtigen sind, um die definierten Anforderungen zu erfüllen.
Die IsyFact stellt eine eigene Bibliothek isy-logging bereit, um die Anforderungen einfach und einheitlich umsetzen zu können.
Die Nutzung der Bibliothek ist ebenfalls in diesem Dokument beschrieben.
Das Dokument richtet sich daher vorrangig an Entwickler, Konstrukteure und Technische Chefdesigner von Anwendungssystemen, die gemäß den Vorgaben der IsyFact umgesetzt werden.
Abgrenzung
Die Umsetzung bzw. Konfiguration des Loggings in Systemen, die nicht nach der IsyFact entwickelt wurden (bspw. Anwendungsservern), ist nicht Teil des Dokuments. Dies wird in den jeweiligen systemspezifischen Nutzungskonzepten adressiert.
2. Aufbau und Zweck des Dokuments
Zweck des Dokuments ist die Vereinheitlichung des Loggings in der Anwendungslandschaft, um eine effiziente Auswertbarkeit der Logeinträge durch die relevanten Parteien zu ermöglichen. Dies umfasst:
-
technische Vereinheitlichung des Loggings, also die einheitliche Konfiguration und Nutzung des Logging-Frameworks im Rahmen der Anwendungsentwicklung, sowie die
-
fachliche Vereinheitlichung des Loggings, also Vorgaben, wann welche Logeinträge mit welchen Inhalten zu erstellen sind.
Das Dokument ist entsprechend dieser Zielsetzungen in die folgenden Kapitel untergliedert:
Im Kapitel Grundlagen werden grundlegende Aspekte des Loggings beschrieben, die zum Verständnis der nachfolgenden Kapitel relevant sind und die Nutzungsvorgaben geprägt haben.
Im Kapitel Einsatz des Logging-Frameworks wird die Konfiguration und Nutzung von isy-logging, dem Logging-Framework der IsyFact, beschrieben.
Im Kapitel Vorgaben zur Logerstellung werden alle Aspekte beschrieben, die die fachlich / inhaltliche Umsetzung des Loggings betreffen. Dies beinhaltet die zu unterstützenden Auswertungsmöglichkeiten der Logeinträge sowie die konkreten Szenarien, in denen Logeinträge zu erstellen sind.
Im Kapitel Ereignisschlüssel isy-logging ist eine Übersicht der verwendeten Ereignisschlüssel dargestellt.
Das Dokument ist beim erstmaligen Lesen im Ganzen zu lesen und zu berücksichtigen, später dient es als Nachschlagewerk. Während der Anwendungsentwicklung ist insbesondere das Kapitel Vorgaben zur Logerstellung relevant und darin im Speziellen die Vorgaben zur Logerstellung, da die dort definierten Szenarien durch die Entwickler erkannt und gemäß den Vorgaben umgesetzt werden müssen.
3. Grundlagen
In diesem Kapitel sind die Grundlagen des Loggings beschrieben.
3.1. Grundprinzipien des Loggings
Im Folgenden werden zunächst die Grundprinzipien des Loggings beschrieben, die den nachfolgenden Kapiteln zu Grunde liegen und das Logging in der IsyFact geprägt haben. Diese sollen ein einheitliches Verständnis und „Gefühl“ für das Logging vermitteln.
Logs als Ereignisdatenbank: Logdateien werden häufig als einfache Textdateien verstanden, in die Einträge – vergleichbar mit der Ausgabe von Text in der Konsole – hinzugefügt werden. Zur Umsetzung eines effizienten Loggings müssen die Logs jedoch vielmehr als Ereignisdatenbank verstanden werden, in die wichtige Ereignisse über die komplette Anwendungslandschaft hinweg aufgenommen werden, um Analysen bzgl. des Verhaltens der Systeme und von wichtigen Systemereignissen zu ermöglichen. Das Schreiben eines Logeintrags darf daher explizit nicht wie das Schreiben eines Fließtextes in eine Logdatei verstanden werden, sondern wie das Speichern eines Ereignisses in einer Datenbank. Daher gelten die Prinzipien:
Zielgerichtetes Logging: Logging muss zielgerichtet erfolgen, d.h. das Schreiben eines Logeintrags erfolgt zu einem bestimmten Zweck. Logeinträge, die von niemandem ausgewertet werden, sind überflüssig. Logeinträge, die nicht die relevanten Informationen enthalten, um sinnvoll ausgewertet werden zu können, sind unbrauchbar. Daher gelten die Prinzipien:
Logging als Funktionalität der Anwendungen: Logausgaben sind Teil der Funktionalität der Anwendung und daher gilt:
3.2. Kennzeichnung von Logeinträgen
Jeder Logeintrag wird mit einem Log-Level gekennzeichnet. Darüber hinaus werden Logeinträge bestimmter Level zusätzlich mit einer Log-Kategorie und einem Ereignisschlüssel gekennzeichnet, um die maschinelle Auswertung der Logeinträge zu erleichtern. Die zugrundeliegenden Konzepte werden in den folgenden Abschnitten erläutert. Die in Logszenarien beschriebenen Szenarien treffen konkrete Vorgaben, wann welche Ausprägungen zu verwenden sind.
3.2.1. Log-Level
Jeder Logeintrag wird bei seiner Erstellung mit einem Log-Level gekennzeichnet. Dieses dient der Klassifizierung des Logeintrags im Hinblick auf dessen Wichtigkeit. Die Wichtigkeit ergibt sich dabei insbesondere aus dem Einfluss des geloggten Ereignisses auf den Systembetrieb. Darüber hinaus wird der Log-Level zur Steuerung der Granularität der erzeugten Logausgaben verwendet. So kann das Log-Level bspw. auf INFO gestellt werden, wodurch nur noch Logeinträge der gleichen Kategorie oder darunter (WARN, ERROR; FATAL) erzeugt werden. Die folgenden Log-Level haben sich dabei im Java-Umfeld etabliert und werden auch in der IsyFact eingesetzt:
| # | Level | Inhalt | Beispiel(e) |
|---|---|---|---|
1 |
FATAL |
Schwerwiegende Fehler, von denen sich die Anwendung nicht erholen kann und beendet werden muss ("Unrecoverable Error"). Es ist ein Eingreifen des Betriebs notwendig, um die Anwendung wieder zu starten. |
Die Eingabe-Datei eines Batchs kann nicht gelesen werden und der Batch muss beendet werden. OutOfMemoryError. |
2 |
ERROR |
Fehler, die zum Abbruch einer Operation geführt haben und behandelt (gefangen und nicht weitergereicht) wurden. Die Anwendung läuft weiter. Der Betrieb muss die Fehlerursache analysieren und ggf. Gegenmaßnahmen einleiten, um ein erneutes Auftreten des Fehlers zu verhindern. |
Nachbarsystem ist endgültig nicht erreichbar. Datenbank ist nicht erreichbar. Fehlerhafter Satz wurde gelesen. |
3 |
WARN |
Beim Durchführen einer Operation ist ein Problem aufgetreten. Die Operation wurde jedoch grundsätzlich durchgeführt. Der Betrieb muss im Hinblick auf die Fehleranalyse hierbei (zunächst) nicht aktiv werden. |
Aufruf eines Nachbarsystems muss wiederholt werden. |
4 |
INFO |
(Status-) Hinweise |
Meldungen über den laufenden Betrieb, zum Beispiel zu verarbeiteten Anfragen, ihrem Ergebnis und ihrer Dauer, Anwendung gestartet/beendet Durchführung eines Retries (bspw. auf Grund eines OptimisticLocking-Fehlers) |
5 |
DEBUG |
Erweiterte Informationen, um Details im Programmablauf zur Fehleranalyse nachvollziehen zu können. |
Meldungen zu markanten Verarbeitungsschritten (bspw. „ Führe Suche nach Personen durch“) |
6 |
TRACE |
Feingranulare und umfangreiche Informationen als Ergänzung des DEBUG-Levels für besonders schwierige Fehleranalysen. |
Vollständige HTTP-Kommunikation an einer Schnittstelle (Header, Body, technische Informationen). |
Hinweis zum Log-Level FATAL: SLF4J und damit auch logback (welches isy-logging zugrunde liegt) besitzen kein Log-Level FATAL.
Die Unterscheidung, ob ein Error-Logeintrag „FATAL“ ist oder nicht, kann mit Hilfe von Markern umgesetzt werden.
| Siehe auch bei SLF4J FATAL |
isy-logging stellt Methoden zum Schreiben von Logeinträgen im Level ERROR als auch in FATAL bereit.
Bei beiden wird ein Logeintrag im Level ERROR erzeugt, dieser aber je nach verwendeter Methode mit der Kategorie „FATAL“ oder „ERROR“ versehen.
Das Log-Level FATAL kann aus Sicht eines Aufrufers von isy-logging daher wie alle anderen Level verwendet werden.
Bei der Auswertung ist auf diese Besonderheit jedoch zu achten.
3.2.1.1. Ausgabe des Log-Levels FATAL
Das Log-Level FATAL wird ist durch SLF4J nicht vorgesehen und wird daher auch durch logback nicht unterstützt. Aus diesem Grund werden Logeinträge die im Level FATAL geschrieben werden, im Level ERROR in die Logdatei geschrieben und mit einer entsprechenden Log-Kategorie (FATAL bzw. ERROR) versehen (siehe auch nachfolgender Abschnitt).
3.2.2. Log-Kategorien
Log-Kategorien dienen der Klassifizierung der Logeinträge im Hinblick auf deren Zweck. Dies erleichtert die maschinelle Auswertung der Logs und ermöglicht es, gezielt Logeinträge einer Kategorie gesondert zu behandeln (bspw. deren Ausgabe umzuleiten oder zu verwerfen). Die Log-Kategorien stellen dabei Verfeinerungen der Log-Level dar. Log-Kategorien werden ausschließlich im Level INFO verwendet und werden in folgender Tabelle beschrieben:
| Level | Kategorie | Beschreibung | Beispiel(e) |
|---|---|---|---|
ERROR |
FATAL |
Logeinträge des Log-Levels FATAL (vgl. Ausgabe des Log-Levels FATAL) |
siehe Log-Level FATAL |
ERROR |
Logeinträge des Log-Levels ERROR (vgl. Ausgabe des Log-Levels FATAL) |
siehe Log-Level ERROR |
|
INFO |
JOURNAL |
Informationen zu Systemzustand, Systemereignissen und durchgeführten Operationen. |
Herunterfahren des Systems, Änderung der Konfiguration |
PROFILING |
Informationen zum Laufzeitverhalten des Systems. |
Dauer der Verarbeitung eines Nachbarsystemaufrufs |
|
METRIK |
Kennzahlen zum Systembetrieb und zur Systemnutzung. |
Erfolgreiche/Fehlerhafte Nutzung einer Service-Methode |
|
SICHERHEIT |
(Potentieller) Angriffsversuch. |
Benutzer-Account wird gesperrt wegen zu vieler ungültiger Anmeldeversuche |
3.2.3. Ereignisschlüssel
Ereignisschlüssel dienen der eindeutigen Identifikation des Zwecks, auf Grund dessen der Logeintrag im Log-Level INFO erstellt wurde (bspw. Erstellung eines Logeintrags beim Verlassen einer Systemgrenze zur Performancemessung). Dies ist notwendig, da das Log-Level INFO eine Vielzahl unterschiedlicher Auswertungsmöglichkeiten bietet. Ohne die Verwendung des Schlüssels könnte der Zweck des jeweiligen Eintrags meist nur mit Kenntnis des Quellcodes oder Interpretation der Lognachricht ermittelt werden, was eine maschinelle Auswertung der Einträge erschwert oder gar unmöglich macht.
Wenn an mehreren Stellen Logeinträge für den gleichen Zweck erstellt werden, wird hierfür der gleiche Ereignisschlüssel verwendet. Dies ist bspw. im Logszenario „Loggen fachlicher Operationen“ (siehe Loggen fachlicher Operationen) der Fall, in dem die Durchführung fachlicher Operationen jeweils mit dem gleichen Ereignisschlüssel geloggt werden, so dass alle diese Einträge mit einer einzelnen Abfrage auf den definierten Schlüssel ausgewertet werden können.
In den Log-Leveln FATAL, ERROR und WARN wird der jeweilige Fehlerschlüssel als Ereignisschlüssel verwendet. In den Log-Leveln DEBUG und TRACE werden keine Ereignisschlüssel verwendet, da dort der Zweck bereits eindeutig durch den Log-Level (Zweck „Fehleranalyse“) bestimmt ist. Dadurch kann der Aufwand für die Verwendung der Ereignisschlüssel gering gehalten werden.
In Ereignisschlüssel isy-logging wird eine Reihe von Standardschlüsseln definiert, die durch das Logging-Framework verwendet werden. Darüber hinaus können in jeder Anwendung eigene Ereignisschlüssel, für systemspezifische Zwecke, definiert werden.
Der Aufbau der Ereignisschlüssel entspricht dem folgenden Schema:
|
Dieses setzt sich aus den folgenden Elementen zusammen:
-
Jedem Schlüssel wird die feste Zeichenkette „E“ vorangestellt, um den Eintrag als Ereignisschlüssel zu Kennzeichnen und zu verhindern, dass dieser mit Fehler- oder Hinweisschlüsseln verwechselt wird.
-
5 Buchstaben, zur Identifikation des Systems. Diese ist analog zur Identifikation, die auch bei den Ausnahme-IDs (siehe Konzept Fehlerbehandlung) verwendet wird.
Anmerkung: Die Systemidentifikation ist Teil des Ereignisschlüssels, um sicherzustellen, dass systemspezifische / bibliotheksspezifische Schlüssel nicht in mehreren Komponenten redundant vergeben werden.
-
2 Ziffern, zur eindeutigen Identifikation der Komponente, in der der Logeintrag erstellt wird (Komponenten-ID). Bei der Erstellung einer neuen Anwendung ist in der Spezifikations- bzw. Konstruktionsphase festzulegen, welche Komponente welche ID zugeordnet wird. Dies ist ebenfalls analog zur Definition der Ausnahme-IDs – es wird für Ausnahme-IDs und Ereignisschlüssel die gleiche Komponenten-ID verwendet.
-
3 Ziffern, als laufende Nummer der Ereignisschlüssel der jeweiligen Komponente.
Ein exemplarischer Ereignisschlüssel der Geschäftsanwendung XYZ ist demnach:
|
Der Aufbau des Ereignisschlüssels besitzt darüber hinaus explizit keine weitere Semantik, um Redundanzen mit den weiteren Attributen des Logeintrags zu vermeiden.
3.3. Vorgaben für Logdateien
Jede Applikation schreibt eine einzelne Logdatei. Weitere Logdateien sind nicht erlaubt. Ausnahmen bilden Logdateien, die durch den Container geschrieben werden, z.B. ein Wrapper- oder Access-Log eines Tomcat-Servers.
3.3.1. Namenskonventionen
Die Logdateien haben fest vorgegebene Namen, die dem folgenden Namensschema entsprechen:
|
Die einzelnen Platzhalter im Namensschema sind in folgender Tabelle beschrieben:
| Bestandteil | Werte | Beschreibung |
|---|---|---|
HOST |
z.B. xyzweb01 |
Name des Servers, auf dem die Logs entstehen |
SYSTEM-ID |
Durch den Technischen Chefdesigner für die jeweilige Anwendung in Abstimmung mit dem Auftraggeber festzulegen (siehe IsyFact Namenskonventionen) |
Name der Anwendung bzw. des Batches. Anwendung bezieht sich hierbei auf die Anwendungen, die im Tomcat laufen, in Abgrenzung zu Batches. |
ZEITSTEMPEL |
YYYY-MM-DD_HH00 |
Datum der Logdateien inkl. stundengenauer Uhrzeit. Zu beachten ist, dass der Zeitstempel erst beim Rotieren der Logs an die Datei angehängt wird (siehe Log-Rotation und Komprimierung). |
Ein Beispiel des Namens einer Logdatei ist demnach:
|
3.3.2. Speicherort
Um die Logdateien durch die Infrastruktur möglichst einfach weiterverarbeiten zu können, werden Logdateien in einem definierten Logverzeichnis je Host abgelegt, welches Unterverzeichnisse für jede Anwendung besitzt. Diese Verzeichnishierarchie ist für alle Anwendungen und Umgebungen gleich, um den Pflegeaufwand für diese Aufgabe so gering wie möglich zu halten.
Logdateien müssen entsprechend dem folgenden Schema abgelegt werden:
|
Bei der Einführung einer neuen Anwendung ist die System-ID (Anwendungsname/Batch-ID) entsprechend abzustimmen und der Betrieb darüber in Kenntnis zu setzen.
3.3.3. Log-Rotation und Komprimierung
Um zu verhindern, dass Logdateien zu groß werden und es gleichzeitig zu ermöglichen, die Logdateien nur für bestimmte Fristen vorzuhalten, werden die anfallenden Logeinträge stündlich in neue Dateien geschrieben (rollierendes Logging).
Zu beachten ist, dass für den Zeitstempel der rotierten Logdateien die Zeitzone UTC verwendet wird – analog zum Zeitstempel der einzelnen Logeinträge. Dieser kann von der Systemzeit des Systems abweichen.
4. Einsatz des Logging-Frameworks
In diesem Abschnitt wird der Einsatz des Logging-Frameworks isy-logging beschrieben.
4.1. Aufruf des Frameworks
Zur Erstellung von Logeinträgen gibt es drei Schnittstellen, die jeweils ein spezifisches Anwendungsszenario umsetzen: IsyLoggerStandard, IsyLoggerFachdaten und IsyLoggerTypisiert.
Wird innerhalb einer Klasse mehr als ein Anwendungsszenario verwendet, kann die Schnittstelle IsyLogger verwendet werden, welche alle drei Schnittstellen umfasst.
Jede Klasse, in der Logs geschrieben werden, muss eine eigene Logger-Instanz verwenden.
Es ist nicht vorgesehen Logger zu vererben.
Die Erzeugung der Logger-Instanz erfolgt mit der Logger-Factory, die durch isy-logging bereitgestellt wird.
public class MyClass {
...
private static final IsyLogger LOG = IsyLoggerFactory.getLogger(MyClass.class);
... oder ...
private static final IsyLoggerStandard LOG = IsyLoggerFactory.getLogger(MyClass.class);
... oder ...
private static final IsyLoggerFachdaten LOG = IsyLoggerFactory.getLogger(MyClass.class);
... oder ...
private static final IsyLoggerTypisiert LOG = IsyLoggerFactory.getLogger(MyClass.class);
...
}Der Name des Loggers muss dem Namen der Klasse entsprechen, in welcher der Logger instanziiert wird – dazu wird die Klasse beim Aufruf der Factory übergeben. Dies ist notwendig, um Logeinträge ihrer Quelle zuordnen zu können.
Zwar stellt der Logger eine Vielzahl von Methoden bereit, allerdings unterscheidet sich der Aufruf kaum von den üblichen Methoden anderer Frameworks – die Vielzahl der Methoden ergibt sich primär durch die Bereitstellung unterschiedlich typisierter Methoden zum Loggen von Ausnahmen, datenschutzrelevanter Daten und der Verwendung von Markern.
Anmerkungen
-
Die Schnittstelle bietet nicht alle bzw. andere Methoden an, als bspw. SLF4J. Dies ist beabsichtigt, um die Log-Inhalte in Systemen, die gemäß der IsyFact entwickelt werden, besser standardisieren zu können. Drittsoftware (bspw. Frameworks wie Hibernate, Spring etc.) oder Systeme, die schrittweise auf das Logging-Framework migriert werden, nutzen automatisch die Logger-Schnittstelle, die durch logback bereitgestellt wird (zum Umgang mit Drittsoftware siehe Umgang mit Drittsoftware).
-
Die Logeinträge werden beim Schreiben einheitlich mit einem Zeitstempel der Zeitzone „UTC“ versehen. Hierauf kann beim Aufruf des Loggers keinen Einfluss genommen werden.
4.1.1. Loggen von technischen Daten
Zum Loggen von technischen und nicht datenschutzrelevanten Daten bietet isy-logging die Schnittstelle IsyLoggerStandard an. Abbildung 1 zeigt eine Übersicht der Schnittstelle:
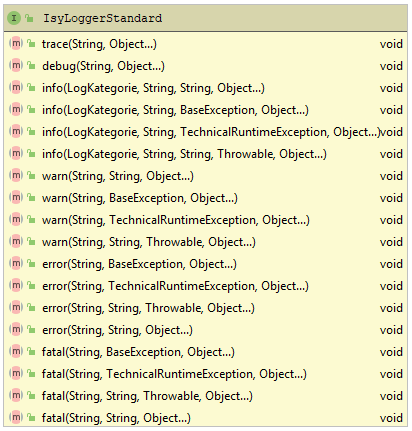
4.1.1.1. Loggen einfacher Nachrichten (TRACE/DEBUG/WARN/INFO)
Die folgenden Methoden dienen der einfachen Ausgabe von Lognachrichten:
trace(String nachricht, Object... werte)
debug(String nachricht, Object... werte)
warn(String schlussel, String nachricht, Object... werte)
info(LogKategorie kategorie, String schlussel, String nachricht, Object... werte)Der Aufruf wird an die entsprechende Methode des SLF4J-Loggers (mit gleicher Signatur) delegiert. Dabei werden alle Werte (d.h. die Inhalte für Platzhalter in der Nachricht) zusätzlich als Marker übergeben, so dass sie im Logeintrag als separate Attribute ausgegeben werden können und damit einfacher auswertbar sind:
-
parameter1: werte[1]. -
parameter2: werte[2]. -
etc.
Beispiel: Der Aufruf
debug("Die Methode {} wurde mit dem Parameter {} aufgerufen.", "addiere", "5")ergänzt die folgenden Attribute im Logeintrag:
-
parameter1: addiere -
parameter2: 5
4.1.1.2. Loggen von Ausnahmen (FATAL/ERROR/WARN/INFO)
In den Log-Leveln FATAL, ERROR und WARN existieren je drei Methoden zum Loggen von Exceptions:
-
<fatal/error/warn>(String nachricht, BaseException exception, Object… werte) -
<fatal/error/warn>(String nachricht, TechnicalRuntimeException exception, Object… werte) -
<fatal/error/warn>(String schluessel, String nachricht, Throwable exception, Object… werte)
Für das Log-Level INFO wird zusätzlich eine Log-Kategorie benötigt. Beim Loggen einer IsyFact-eigenen Ausnahme wird der Fehlerschlüssel automatisch als Ereignisschlüssel übernommen. Bei anderen Ausnahmen muss zusätzlich ein Ereignisschlüssel übergeben werden.
Der Aufruf wird an die entsprechende Methode des SLF4J-Loggers delegiert. Als Marker werden dabei übergeben:
-
fehlerschluessel: Fehlerschlüssel derBaseException. -
parameter[1..n]: siehe oben (Loggen einfacher Nachrichten (TRACE/DEBUG/WARN/INFO))
4.1.1.3. Loggen von Informationen (INFO)
Zum Erstellen von INFO-Logeinträgen wird die folgende Methode bereitgestellt:
-
info(LogKategorie kategorie, String schluessel, String nachricht, Object… werte)
Der Aufruf wird an die entsprechende Methode des SLF4J-Loggers delegiert. Als Marker werden dabei übergeben:
-
kategorie: Mit dem Wert des übergebenen Parameters -
schluessel: Mit dem Wert des übergebenen Parameters -
parameter[1..n]: siehe oben (Loggen einfacher Nachrichten (TRACE/DEBUG/WARN/INFO))
4.1.2. Loggen von fachlichen Daten
Lognachrichten dürfen gemäß dem Grundsatz der Datensparsamkeit nur die fachlichen Daten enthalten, die für den Betrieb der jeweiligen Anwendung unbedingt notwendig sind. Fachliche Daten sind in der Regel alle Teile des fachlichen Datenmodells. Sie unterliegen häufig den Auflagen des Datenschutzes. Eine Ausnahme stellen fachliche IDs dar; sie werden nicht als fachliches Datum behandelt. Welche weiteren Daten als fachlich anzusehen sind, muss in der Systemspezifikation festgelegt werden. Welche fachlichen Daten im Log enthalten sein müssen, muss im Systementwurf festgelegt werden.
Die folgenden zwei Beispiele verdeutlichen, warum es notwendig sein kann, fachliche Daten ins Log aufzunehmen:
-
Die Daten ermöglichen die in Auswertungen definierten Auswertungen.
-
Zur generellen Analyse von Fehlern an einer Schnittstelle werden einige der an ihr übertragenen Daten benötigt.
Zum Loggen fachlicher Daten bietet isy-logging die Schnittstelle IsyLoggerFachdaten an.
Abbildung 2 zeigt eine Übersicht der Schnittstelle.
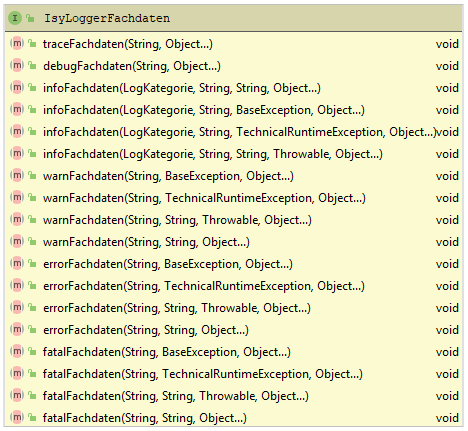
Zu allen Methoden, die in Loggen von technischen Daten beschrieben wurden, bietet die Schnittstelle IsyLoggerFachdaten eine äquivalente Methode mit gleicher Signatur an, die zum Loggen fachlicher Daten im jeweiligen Log-Level verwendet wird.
Die Methoden tragen dabei jeweils das Suffix Fachdaten im Namen.
Eine besondere Rolle innerhalb der fachlichen Daten spielen personenbezogenen Daten und insbesondere Daten gemäß Artikel 9 DSGVO. Diese sollten nur in absoluten Ausnahmefällen ins Log geschrieben werden und müssen zwingend mit speziellen Markern versehen werden (s. Verwendung von Markern in Logeinträgen).
4.1.3. Verwendung von Markern in Logeinträgen
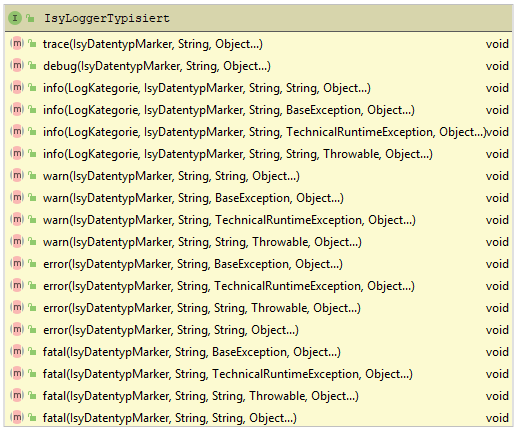
Zum beliebigen Markieren von Logeinträgen bietet isy-logging die Schnittstelle IsyLoggerTypisiert an.
Abbildung 3 zeigt eine Übersicht der Schnittstelle:
Die in Loggen von fachlichen Daten beschriebene Funktionalität verwendet intern einen festen Marker, um einen Logeintrag als datenschutzrelevant („Fachdaten“) zu kennzeichnen.
Die Schnittstelle IsyLoggerTypisiert ermöglicht es Anwendungen darüber hinaus, Logeinträge mit beliebigen Markern zu versehen.
Zu allen Methoden, die in Loggen von technischen Daten beschrieben wurden, bietet die Schnittstelle IsyLoggerTypisiert eine äquivalente Methode mit gleicher Signatur an, die zum Markieren der jeweiligen Logeinträge verwendet werden kann.
Die Methoden besitzen jeweils einen zusätzlichen Parameter vom Typ IsyDatentypMarker.
Anwendungen können ihre Marker von der Klasse AbstractIsyDatentypMarker ableiten.
Für die Kennzeichnung von personenbezogenen Daten und für Daten gemäß Artikel 9 DSGVO werden von isy-logging die Marker PersonenbezogeneDatenMarker und DsgvoArtikel9DatenMarker bereitgestellt.
Sie werden zusammen mit der Schnittstelle IsyLoggerTypisiert verwendet:
LOG.info(LogKategorie.JOURNAL, DsgvoArtikel9DatenMarker.INSTANZ, "schluessel", "nachricht")
4.1.4. Verwendung von Platzhaltern in Nachrichten
In den Lognachrichten können Platzhalter verwendet werden, die beim Erstellen des Logeintrags mit dem konkreten Wert des aktuellen Aufrufs ersetzt werden (bspw. gemessene Laufzeit).
Platzhalter sind in den Nachrichten durch geschweifte Klammern {} zu kennzeichnen, bspw.:
// RICHTIG:
LOG.debug("Die Methode {} wurde mit dem Parameter {} aufgerufen.", method.getName(), wert)Die Verwendung des Parameters wert zum Ersetzen der Platzhalter ermöglicht es zudem, die übergebenen Parameter als separate Attribute in den Logeintrag zu übernehmen (siehe vorhergehende Abschnitte), was die Auswertbarkeit der Einträge erleichtert.
Zudem wird die Performance des Systems leicht erhöht, da die Konkatenation des Strings nur dann erfolgt, wenn der Logeintrag auch geschrieben wird (d.h. der Log-Level eingeschaltet ist) – dieser Performance-Gewinn ist vernachlässigbar und nicht die Motivation dieser Vorgehensweise.
Das direkte Konkatenieren von Zeichenketten zum Aufbau einer Lognachricht ist nicht erlaubt:
//FALSCH:
LOG.debug("Die Methode " + method.getName() + " wurde mit dem Parameter " + wert + " aufgerufen.")Das früher weitverbreitete isDebugEnabled ist im Normalfall nicht mehr notwendig (da die Konkatenation durch logback nur stattfindet, wenn der Logeintrag auch geschrieben wird) und sollte daher auch nicht mehr verwendet werden, um den Code übersichtlich zu halten:
//FALSCH:
if (LOG.isDebugEnabled()) {
LOG.debug("Die Methode {} wurde mit dem Parameter {} aufgerufen.", method.getName(), wert).
}Ausnahme ist hierbei jedoch das Loggen komplexer Meldungen:
//RICHTIG:
if (LOG.isDebugEnabled()) {
LOG.debug("Debug-Meldung: {} ", myObject.complexMethod());
}In diesem Code-Beispiel wird sehr viel Rechenzeit verbraucht, um die Log-Information von der Methode myObject.complexMethod() zu bekommen.
Um den komplexen Aufruf nur durchzuführen, wenn der Logeintrag auch wirklich geschrieben wird, ist es in diesem Fall sinnvoll die Prüfung isDebugEnabled durchzuführen.
4.1.5. Hilfsklassen
isy-logging stellt die folgenden Hilfsklassen zum Erstellen von Logeinträgen bereit.
4.1.5.1. LoggingMethodInterceptor und LoggingMethodInvoker
Die Klassen LoggingMethodInterceptor und LoggingMethodInvoker bieten die Möglichkeit, einheitliche Logeinträge vor und nach dem Aufruf einer Methode für verschiedene Zwecke (insbesondere dem Messen der Laufzeit für das Profiling) zu erstellen.
Beide erzeugen die gleichen Logeinträge, dienen jedoch unterschiedlichen Einsatzzwecken.
Der Interceptor wird per Spring als Method-Interceptor konfiguriert und kann dadurch querschnittlich für eingehende Methodenaufrufe konfiguriert werden.
Der Invoker wird direkt im Anwendungscode für die Durchführung von Methodenaufrufen verwendet. Zur Verwendung des Invokers, muss eine Instanz des Interceptors als Klassenvariable erstellt werden:
public class MyClass {
private static final LoggingMethodInterceptor _LOG_INTERCEPTOR_ = new LoggingMethodInterceptor(true, true, false, false);
...Der Konstruktor besitzt folgende Signatur:
-
LoggingMethodInvoker(Method methode, IsyLogger logger, boolean loggeAufruf, boolean loggeErgebnis, boolean loggeDauer, boolean loggeDaten, boolean loggeDatenBeiException, long loggeMaximaleParameterGroesse): Methode ist die aufzurufende Methode. Die Flags werden verwendet, um zu steuern, welche Logeinträge erstellt werden (siehe unten).
Das Loggen eines Methodenaufrufs erfolgt mit der Methode:
-
fuehreMethodeAus(Object zielobjekt, Object… parameter): Ruft per Reflection die Methode, welche per Konstruktor gesetzte wurde, auf dem Zielobjekt mit den übergebenen Parametern auf und schreibt die Logeinträge mit folgenden Ereignisschlüsseln (Details zu den Inhalten der jeweiligen Logeinträge finden sich in Kapitel Ereignisschlüssel isy-logging):
| Ereignisschlüssel LoggingMethodInvoker |
|---|
Falls loggeAufruf = true |
|
Falls loggeErgebnis = true und keine Exception geliefert wurde |
|
Falls loggeErgebnis = true und eine Exception geliefert wurde |
|
Falls loggeDauer = true und keine Exception geliefert wurde |
|
Falls loggeDauer = true und eine Exception geliefert wurde |
|
Darüber hinaus werden folgende Debug-Logeinträge erstellt:
| Level | Text |
|---|---|
Falls loggeDatenBeiException = true |
|
DEBUG |
Die <Klasse. Methode> wurde mit folgenden Parametern aufgerufen <Parameter>. ANMERKUNG: Der Logeintrag wird als „Fachdaten“ gekennzeichnet. |
Falls loggeDaten = true und eine Exception geliefert wurde |
|
DEBUG |
Die <Klasse. Methode> wurde mit folgenden Parametern aufgerufen <Parameter>. ANMERKUNG: Der Logeintrag wird als „Fachdaten“ gekennzeichnet. |
Falls Debug-Einträge erstellt werden und ein Parameter zu groß ist |
|
DEBUG |
Die <Klasse.Methode> wurde mit einem zu großen Parameter aufgerufen. Position: <Position des Parameters>, Klasse: <Klasse des Parameters> ANMERKUNG: Der Logeintrag wird als „Fachdaten“ gekennzeichnet. Außerdem werden zu große Parameter in den oben genannten Logeinträgen durch „<Maximale Größe überschritten>“ ersetzt. |
Den Aufrufen von Nachbarsystemen kommt eine besondere Wichtigkeit bei der Analyse des Laufzeitverhaltens von Systemen zu. Daher stellt der Invoker für Methodenaufrufe von Nachbarsystemen einen eigenen Konstruktor bereit:
-
LoggingMethodInvoker(Method methode, IsyLogger logger, boolean loggeAufruf, boolean loggeErgebnis, boolean loggeDauer, boolean loggeDaten, boolean loggeDatenBeiException , long loggeMaximaleParameterGroesse, String nachbarsystemName, String nachbarsystemUrl): Analog zu oben, nur das der Name und die URL des aufgerufenen Nachbarsystems übergeben wird.
Dieser Konstruktor ist beim Aufruf einer Service-Schnittstelle eines Nachbarsystems zu verwenden (vgl. auch Szenario „Performance überwachen“ in Performance überwachen).
Zu beachten ist, dass die Klasse IsyHttpInvokerClientInterceptor, welche durch den Baustein Service bereitgestellt wird (siehe Detailkonzept Komponente Service), bereits einen entsprechenden Aufruf des Invokers durchführt.
Bei Verwendung dieses Konstruktors werden die Logeinträge mit folgenden Ereignisschlüsseln erstellt:
Ereignisschlüssel LoggingMethodInvoker (Nachbarsystemaufruf)
| Ereignisschlüssel LoggingMethodInvoker (Nachbarsystemaufruf) |
|---|
Falls loggeAufruf = true |
|
Falls loggeErgebnis = true und keine Exception geliefert wurde |
|
Falls loggeErgebnis = true und eine Exception geliefert wurde |
|
Falls loggeDauer = true und keine Exception geliefert wurde |
|
Falls loggeDauer = true und eine Exception geliefert wurde |
|
4.1.5.2. LogApplicationListener
Die Hilfsklasse LogApplicationListener dient dem Loggen von Änderungen des Systemzustands.
Sie muss gemäß LogApplicationListener als Spring-Bean konfiguriert, aber danach nicht mehr explizit aufgerufen werden.
Die Klasse erstellt die Logeinträge mit folgenden Ereignisschlüsseln (Details zu den Inhalten der jeweiligen Logeinträge finden sich in Ereignisschlüssel isy-logging):
| Ereignisschlüssel LogApplicationListener |
|---|
Beim Starten einer Anwendung / eines Batches |
|
Beim Stoppen einer Anwendung / eines Batches |
|
4.1.5.3. MdcHelper
Die Klasse MdcHelper erleichtert das Setzen von Informationen im MDC (Mapped Diagnostic Context).
Es werden Methoden zum Setzen und Lesen der Korrelations-ID bereitgestellt:
-
pushKorrelationsId(…): Zum „pushen“ einer neuen Korrelations-ID in den MDC. Dies bedeutet: Wenn die Korrelations-ID „X“ gesetzt wird, wird diese im Attribut „korrelationsid“ im MDC gesetzt. Sollte dieses Attribut bereits gesetzt sein (bspw. mit der Korrelations-ID „Y“), so wird das Attribut durch „Y;X“ ersetzt.
-
liesKorrelationsId(): Liest die Korrelations-ID aus dem MDC. -
entferneKorrelationsId(): Entfernt die zuletzt „gepushte“ Korrelations-ID (bspw. „Y;X“ wird zu „Y“). -
entferneKorrelationsIds(): Entfernt alle Korrelations-IDs.Darüber hinaus werden Methoden zum Kennzeichen der Inhalte im MDC als fachlich bereitgestellt (vgl. Abschnitt Loggen von fachlichen Daten):
-
setzeMarkerFachdaten(…): Markiert den MDC als fachlich / nicht fachlich. -
liesMarkerFachdaten(): Gibt an, ob der MDC fachliche Daten enthält. -
entferneMarkerFachdaten(): Entfernt den Marker für Fachdaten.
4.1.6. MDC-Filter
Durch die Spring-Autokonfiguration in isy-logging wird ein Servlet-Filter erstellt, welcher automatisch bei jedem Request die Korrelations-ID aus dem Http-Header ausliest und in den MDC setzt.
Ist der Header nicht gesetzt, wird eine neue Korrelations-ID generiert, indem die autokonfigurierte Bean FilterRegistrationBean<HttpHeaderNestedDiagnosticContextFilter> aus isy-logging aufgerufen wird.
Das URL-Pattern "/*" schließt dabei alle URLs ein.
@Bean
FilterRegistrationBean<HttpHeaderNestedDiagnosticContextFilter> httpHeaderNestedDiagnosticContextFilter() {
FilterRegistrationBean<HttpHeaderNestedDiagnosticContextFilter> registrationBean = new FilterRegistrationBean<>();
registrationBean.setFilter(new HttpHeaderNestedDiagnosticContextFilter());
registrationBean.addUrlPatterns("/*");
registrationBean.setOrder(Ordered.HIGHEST_PRECEDENCE);
return registrationBean;
}Falls HttpInvoker-Schnittstellen verwendet werden, muss diese Bean im Anwendungssystem so überschrieben werden, dass sie für die HttpInvoker-Schnittstellen deaktiviert ist. Grund dafür ist, dass bei HttpInvoker-Schnittstellen durch den Aufruf der Klasse IsyHttpInvokerClientInterceptor bereits eine Korrelations-ID generiert wird. Ohne das Überschreiben dieser Bean werden beim Aufruf einer HttpInvoker-Schnittstelle beide Mechanismen aktiv, sodass zwei neue Korrelations-IDs für eine einzige Aktion neu erzeugt werden. Dies ist zu vermeiden.
Beim Überschreiben der Bean müssen die URL-Patterns so angegeben werden, dass die HttpInvoker-URLs nicht enthalten sind.
Die Verwendung des Asterisk-Platzhalters * ist dabei am Ende des URL-Patterns möglich.
Stellt eine Anwendung beispielsweise HttpInvoker-Schnittstellen unter "/httpinv-endpoint0" sowie REST-Schnittstellen unter "/rest-endpoint1", "/api/rest/example/endpoint2" und "/api/rest/example/endpoint3" bereit, muss die Bean im Anwendungssystem wie folgt überschrieben werden:
@Bean
FilterRegistrationBean<HttpHeaderNestedDiagnosticContextFilter> httpHeaderNestedDiagnosticContextFilter() {
FilterRegistrationBean<HttpHeaderNestedDiagnosticContextFilter> registrationBean = new FilterRegistrationBean<>();
registrationBean.setFilter(new HttpHeaderNestedDiagnosticContextFilter());
registrationBean.addUrlPatterns("/rest-endpoint1", "/api/rest/example/*");
registrationBean.setOrder(Ordered.HIGHEST_PRECEDENCE);
return registrationBean;
}Dadurch wird der HttpHeaderNestedDiagnosticContextFilter wie gewünscht nur für die REST-Schnittstellen aufgerufen.
4.1.7. Diagnosekontext / Korrelations-ID
Die Korrelations-ID (siehe Logging - Konzept) ist in jedem Eintrag mitzuloggen, damit die Logeinträge einzelnen Aufrufen zugeordnet und über die Komponenten der Anwendungslandschaft verfolgt werden können.
Das Ermitteln der Korrelations-ID erfolgt automatisch durch isy-logging.
Hierzu wird der Mapped Diagnostic Context (MDC) verwendet, der durch SLF4J bzw. logback zur Verfügung gestellt wird.
Der MDC wird über eine statische Methode gesetzt, und zwar pro Thread:
MDC.put("Korrelations-ID", "<Korrelations-ID>");
Die Korrelations-ID kann sich aus mehreren Unique-IDs zusammensetzen, durch die der Aufruf durch die Anwendungslandschaft nachverfolgt werden kann. Die IDs müssen hintereinander gehängt, getrennt durch ein Semikolon, im Kontext gesetzt werden, bspw.:
MDC.put("Korrelations-ID", "c15638a2-4c38-4d18-b887-5ebd2a1c427d;f60143b3-3408-4501-9947-240ec1c48667;c893d44f-3b8e-446e-a360-06a520440e64");
Am Ende der Verarbeitung ist der MDC wieder zu entfernen:
MDC.remove("Korrelations-ID");
Anmerkung zu Multi-Threading
Es wird davon ausgegangen, dass es innerhalb eines Request kein Multi-Threading gibt, sondern nur in den Clients. Da der Client einem bestimmten Benutzer zugeordnet werden kann, wird hier kein MDC benötigt.
Sollte jedoch Multi-Threading innerhalb eines Requests vorhanden sein, so ist der MDC dem Thread mitzugeben. Somit müssen alle Klassen, die das Interface Runnable implementieren, eine Methode vorsehen, um den MDC von der Klasse zu bekommen, die den Thread startet. Ansonsten besitzt der gestartete Thread nicht den Kontext des aufrufenden Threads. Zusätzlich muss im Thread eine weitere Unique-ID an die Korrelations-ID im MDC angehängt werden, so dass auch die Logeinträge des Threads eindeutig identifiziert werden können.
Anmerkung zum Parallelbetrieb von AufrufKontextVerwalter und MdcHelper
Innerhalb der Anwendung wird die Korrelations-ID sowohl über das AufrufKontext-Objekt im AufrufKontextVerwalter als auch über den MdcHelper verwaltet und zur Verfügung gestellt.
An der Service-Schnittstelle werden dazu die Annotationen @StelltLoggingKontextBereit und @StelltAufrufKontextBereit in Zusammenspiel verwendet.
Die Annotation @StelltLoggingKontextBereit liest die Korrelations-ID aus einem AufrufKontextTo, welches der annotierten Methode als Parameter übergeben wird und befüllt den Logging-Kontext, indem die Korrelations-ID in den MdcHelper geschrieben wird.
Enthält das AufrufKontextTo keine (null) oder eine leere ("") Korrelations-ID, so wird eine neue Korrelations-ID generiert. Die neu generierte Korrelations-ID wird in das AufrufKontextTo-Objekt zurückgeschrieben und ebenfalls an den MdcHelper weitergegeben.
Die @StelltLoggingKontextBereit-Annotation kann auch ohne vorhandenes AufrufKontextTo-Objekt verwendet werden. Dazu muss nutzeAufrufKontext auf false gesetzt werden. In diesem Fall wird eine neue Korrelations-ID generiert und in den MdcHelper geschrieben.
Nach Aufruf des StelltLoggingKontextBereitInterceptors über die @StelltLoggingKontextBereit-Annotation ist die Korrelations-ID sowohl im MDC also auch im AufrufKontextTo vorhanden.
Um die Daten des AufrufKontextTo in den AufrufKontextVerwalter zu schreiben, wird die Annotation @StelltAufrufKontextBereit verwendet. Im StelltAufrufKontextBereitInterceptor wird hierfür ein neues AufrufKontext-Objekt erstellt. Nach der Erstellung werden die Daten aus dem AufrufKontextTo in das AufrufKontext-Objekt übertragen und der AufrufKontext in den AufrufKontextVerwalter gesetzt. Der vorherige AufrufKontext wird hierbei zwischengespeichert und nach Aufruf der mit @StelltAufrufKontextBereit annotierten Methode wiederhergestellt. Entsprechend stehen die Daten aus dem AufrufKontextTo innerhalb des Methodenaufrufs in Form eines AufrufKontext-Objekts über den AufrufKontextVerwalter zur Verfügung.
Nach dem Durchlaufen beider Interceptoren steht die Korrelations-ID sowohl im AufrufKontext(Verwalter) als auch über den MdcHelper zur Verfügung.
4.2. Konfiguration
In diesem Abschnitt werden die notwendigen Konfigurationen zum Einrichten des Loggings beschrieben.
Die Konfiguration erfolgt dabei ausschließlich über die Konfigurationsdatei von logback und Spring – isy-logging besitzt selbst keine zusätzliche Konfigurationsdatei.
4.2.1. Logback-Konfiguration
Folgende Aspekte sind bei der Logback-Konfiguration zu beachten:
Konfigurationsdateien
Alle Anwendungen dürfen ihre Logging-Konfiguration ausschließlich über die Konfigurationsdateien logback.xml und application.properties vornehmen.
Die Auslieferung der Logging-Konfiguration geschieht mit den applikationsspezifischen Konfigurationsdateien für die jeweilige Umgebung.
Die Ablage der Konfigurationsdatei in Sourcen und Kompilaten ist durch das Konzept Konfiguration) definiert.
Die Konfigurationsdateien dürfen nicht in einem Archiv (JAR-Bibliothek) abgelegt werden, sondern müssen als einzelne Dateien installiert werden.
Konfiguration des Log-Levels
In Produktion ist die Konfiguration in aller Regel fix, da sie auf die betriebliche Infrastruktur abgestimmt sein muss.
In der Produktionsumgebung darf daher nur der Log-Level angepasst werden.
Der Log-Level wird über application.properties eingestellt.
Damit dies funktioniert, wird das Attribut level bei der Definition der Logger in logback.xml weggelassen.
Standardmäßig werden die Systeme in Produktion im Log-Level INFO betrieben.
Bei Bedarf kann jedoch auf DEBUG und in Ausnahmefällen auf TRACE gewechselt werden, um detaillierte Informationen zur Fehleranalyse bereitzustellen.
Andere Log-Level sind zu vermeiden.
4.2.1.1. Anwendungen (zeitbasiertes Rollieren)
Die Bibliothek isy-logging stellt bereits einen vorkonfigurierten Appender bereit, durch den Logdateien gemäß den in Vorgaben für Logdateien definierten Vorgaben erstellt werden.
In der Anwendung bzw. im Batch selbst ist daher nur noch eine minimale Logging-Konfiguration notwendig:
<configuration scan="true" scanPeriod="1 minutes">
<!-- Eindeutige mIdentifikation der Instanz der Anwendung. -->
<contextName>testserver_testsystem</contextName>
<!-- Pfad der Logdatei, ohne Endung -->
<property name="LOGFILE_PATH" value="logausgaben/testserver_testsystem" />
<!-- MDC in die Ausgabe mitaufnehmen. -->
<property name="INCLUDE_MDC" value="false" />
<!-- Include der vorkonfigurierten Appender. -->
<include resource="resources/isylogging/logback/appender.xml" />
<!-- Root-Logger als Grundlage für alle Logger-Instanzen -->
<root>
<appender-ref ref="DATEI_ANWENDUNG" />
</root>
</configuration>Folgende Parameter sind zu setzen:
-
LOGFILE_PATH: Der Pfad der Logdatei (LOGFILE_PATH) muss gemäß den Vorgaben für Logdateien angepasst werden. -
INCLUDE_MDC: Gibt an, ob der komplette Inhalt des MDC in das Log aufgenommen werden soll (true) oder nicht (false). -
CONTEXT_NAME: AlscontextNamewird „<HOST>_<SYSTEM-ID>“ zur eindeutigen Identifikation der Instanz der Anwendung bzw. des Batches angegeben.
4.2.1.2. Lokale Entwicklungsumgebung (Konsolenausgabe)
In der lokalen Entwicklungsumgebung ist es hilfreich, die Log-Ausgaben direkt auf der Konsole in einem einfachlesbaren Format auszugeben. Hierfür wird folgende Konfiguration verwendet:
<configuration scan="false">
<!-- Include der vorkonfigurierten Appender. -->
<include resource="resources/isylogging/logback/appender-entwicklung.xml" />
<!-- Root-Logger als Grundlage für alle Logger-Instanzen -->
<root>
<appender-ref ref="KONSOLE" />
</root>
</configuration>4.2.1.3. Weitere Konfigurationsmöglichkeiten
In diesem Abschnitt werden weitere Möglichkeiten der Konfiguration von logback beschrieben, die bei Bedarf genutzt werden können:
4.2.1.4. Maximale Länge des Logeintrags festlegen
Es kann die maximale Länge eines Logeintrags in Bytes festgelegt werden.
Sollte ein Logeintrag länger als dieser Wert sein, so wird der Logeintrag gekürzt (siehe Logging - Konzept).
Wird kein Wert angegeben, so beträgt der Standardwert 32000 Bytes.
Wird der Wert auf 0 festgelegt, so gibt es keine Begrenzung in der Länge des Logeintrags.
Die Beschränkung der Länge gilt nur für Logeinträge der Levels INFO, WARN und ERROR.
Die maximale Länge eines Logeintrags wird wie folgt gesetzt:
<property name="MAX_LENGTH" value="32000" />4.2.1.5. Logging für einzelne Klassen deaktivieren
Es kann sinnvoll sein, das Log-Level einer einzelnen Klasse oder eines Packages abweichend zum Root-Logger zu konfigurieren – bspw. falls ein Framework in einer bestimmten Klasse irreführende Logeinträge erzeugt. Dies geschieht nach folgendem Schema:
<configuration>
<root>
<appender-ref ref="KONSOLE" />
</root>
<logger name="de.bund.bva.isyfact" additivity="false">
<appender-ref ref="KONSOLE"/>
</logger>
</configuration>logging.level.root=INFO
logging.level.de.bund.bva.isyfact=DEBUGDas Attribut additivity=false gibt dabei an, dass für die konfigurierte Klasse bzw. das konfigurierte Package ausschließlich dieser Logger und nicht zusätzlich der Root-Logger verwendet werden soll.
4.2.2. Spring-Konfiguration
Im Folgenden werden die Spring-Konfigurationen zur Integration von logback in Spring und zur Konfiguration der genutzten Hilfsmechanismen (vgl. Logging - Konzept) beschrieben.
4.2.2.1. LoggingMethodInterceptor
Der LoggingMethodInterceptor besitzt die folgenden Konfigurationsparameter:
loggeDauer, loggeAufruf, loggeErgebnis, loggeDaten, loggeDatenBeiException und loggeMaximaleParameterGroesse (vgl. LoggingMethodInterceptor und LoggingMethodInvoker).
Durch isy-logging werden zwei Instanzen des LogInterceptors mit unterschiedlichen Ausprägungen der oben genannten Parameter automatisch konfiguriert:
-
boundaryLogInterceptor: Dieser wird verwendet, um Aufrufe an Systemgrenzen zu loggen. Zur Kennzeichnung von Systemgrenzen wird die vonisy-loggingbereitgestellt Annotation@Systemgrenzeverwendet. Damit werden alle Service-Schnittstellen, GUI-Controller und Batchausführungsbeans annotiert (siehe Szenarien in Aufruf an Systemgrenze und Rückliefern einer Exception an Systemgrenze). -
komponentLogInterceptor: Dieser wird verwendet, um Aufrufe an Komponentengrenzen zu loggen. Hierfür wird die analog die Annotation@Komponentengrenzebereitgestellt. Damit werden alle relevanten Komponenten-Schnittstellen annotiert (siehe Szenario in Abschnitt Aufruf an Komponentengrenze).
Die Standardkonfiguration der Interceptoren zeigt Tabelle 8.
Sie kann in Ausnahmefällen über application.properties geändert werden:
Ereignisschlüssel isy-logging
| Parameter | Default | Bemerkung |
|---|---|---|
|
|
Muss auf |
|
|
|
|
|
|
|
|
Kann in einer Testumgebung oder temporär in Produktion auf |
|
|
Muss auf |
|
|
Setzt die maximale Größe von Parametern, die ins Log geschrieben werden dürfen, in Bytes. Ist nur aktiv, wenn 0 bedeutet keine Beschränkung. |
|
|
Die Ausgabe der Dauer und der durchgeführten Aufrufe an Komponentengrenzen führt zu einem hohen Logvolumen. Daher ist es sinnvoll, den Parameter im Produktivbetrieb nur bei Bedarf auf v zu stellen (vgl. Logszenario Aufruf an Komponentengrenze). |
|
|
|
|
|
Kann in einer Testumgebung oder temporär in Produktion zur Unterstützung der Fehlersuche |
|
|
|
|
|
|
|
|
Setzt die maximale Größe von Parametern, die ins Log geschrieben werden dürfen, in Bytes. Ist nur aktiv, wenn loggeDaten oder loggeDatenBeiException auf 0 bedeutet keine Beschränkung. |
Anpassen der Konvertierung
Ist der Parameter loggeDatenBeiException auf true gesetzt, werden die übergebenen Schnittstellenparameter der Methode, bei der eine Exception aufgetreten ist, falls sie nicht zu groß sind oder die Größenbeschränkung deaktiviert ist, konvertiert (serialisiert) und in den Logeintrag übernommen.
Handelt es sich bei einem der Parameter um eine Objektstruktur, wird diese Struktur teilweise rekursiv durchlaufen und sämtliche Attribute in den Logeintrag übernommen.
Bei dieser Konvertierung gelten standardmäßig folgende Regeln:
-
Sämtliche Objekte im Package
de.bund.bva(inkl. Subpackages) werden rekursiv durchlaufen. -
Alle anderen Objekte, Primitives und Enums werden mit
toStringumgewandelt.
Dieses Verhalten kann bei Bedarf konfigurativ angepasst werden, in dem die beiden Properties isy.logging.<boundary | component>.converterIncludes und isy.logging.<boundary | component>.converterExcludes angegeben werden.
Dabei gilt:
-
Alle Objekte aus Packages (und Sub-Packages) in der Liste
converterIncludeswerden Rekursiv durchlaufen. -
Alle Objekte aus Packages (und Sub-Packages) in der Liste
converterExcludeswerden ignoriert. -
Alle anderen Objekte werden mit
toStringumgewandelt.
Gründe für die Anpassung der Konfiguration können bspw. sein:
-
Exkludieren einzelner Packages, die nicht serialisiert werden können oder nicht relevant sind und dadurch zu unnötigen Loginhalten führen.
-
Inkludieren einzelner Packages, falls die Anwendung nicht in der Domäne
de.bund.bvaentwickelt wird.
Eine exemplarische Konfiguration ist im Folgenden dargestellt:
isy.logging.boundary.converterIncludes=x.y.z, u.v.w
isy.logging.boundary.converterExcludes=a.b.c4.2.2.2. LogApplicationListener
Der LogApplicationListener wird über folgende Properties konfiguriert:
isy.logging.anwendung.typ=<SYSTEMART>
isy.logging.anwendung.name=<SYSTEMNAME>
isy.logging.anwendung.version=<SYSTEMVERSION>Die Platzhalter müssen dabei wie folgt ersetzt werden:
-
SYSTEMART: Kürzel der Systemart gemäß den Namenskonventionen – bspw.REGbei einem Register,GAbei einer Geschäftsanwendung,QAbei einer Querschnittsanwendung,BATbei einem Batch. -
SYSTEMNAME: Name der Anwendung analog zu Anwendungen (zeitbasiertes Rollieren). -
VERSIONSNUMMER: Versionsnummer der Anwendung. Diese ist als interner Konfigurationsparameter in der Anwendung abzulegen.
4.2.3. Performance-Logging
In diesem Abschnitt werden die notwendigen Konfigurationen zum Einrichten des Performance-Loggings beschrieben.
Die Auswahl der zu loggenden Aufrufe erfolgt über die Namenskonventionen von IsyFact. Eine Übersicht über die erfassten Klassen bietet die folgende Tabelle:
| Schicht / Klassen | Pointcut |
|---|---|
Controller / Webaufrufe |
|
Serviceschicht |
|
Core-Komponenten |
|
AWF-Klassen |
|
AFU-Klassen |
|
DAOs |
|
Bei allen Aufrufen wird nur die Dauer des Aufrufs geloggt.
Das Performance-Logging wird über die Property isy.logging.performancelogging.enabled=true eingeschaltet.
4.2.3.1. Annotation für Performance-Logging
Für den Fall, dass Aufrufe außerhalb der Namenskonventionen geloggt werden sollen, wird die Annotation @PerformanceLogging bereitgestellt.
Damit werden Methoden annotiert, die vom Performance-Logging erfasst werden sollen.
So können z.B. auch die Aufrufe fremder RemoteBean-Schnittstellen geloggt werden.
4.2.4. Umgang mit Drittsoftware
Es muss sichergestellt werden, dass alle Bibliotheken – auch solche die nicht nach den Vorgaben der IsyFact entwickelt wurden – logback, mit der in Logback-Konfiguration definierten Konfiguration, nutzen. Dadurch wird gewährleistet, dass die definierten Vorgaben zu Logdateien und Struktur der Logeinträge einheitlich umgesetzt werden.
Beim Einsatz von Bibliotheken, die nicht nach der IsyFact entwickelt wurden, muss daher unterschieden werden:
-
Die Bibliothek loggt mittels logback oder SLF4J: Es sind keine Maßnahmen notwendig.
-
Die Bibliothek setzt ein anderes Logging-Framework ein: Es muss eine entsprechende „Bridge“ integriert werden, welche die Aufrufe der Bibliothek an das jeweilige Logging-Framework auf logback umleitet.
SLF4J stellt bereits fertige Bridges für alle gängigen Logging-Frameworks zur Verfügung, deren Einsatz im Folgenden beschrieben wird. Grundsätzlich ist es unkritisch, wenn alle Bridges konfiguriert werden. Um die Komplexität der Konfiguration und deren Wartung nicht unnötig zu erhöhen, sollten jedoch nur die Bridges eingerichtet werden, die auch tatsächlich benötigt werden.
Bei sämtlichen Bridges muss sichergestellt werden, dass das logback.jar als einzige SLF4J-Implementierung in der Anwendung vorhanden ist.
4.2.4.1. Bridge für commons-logging
SLF4J stellt mit der Bibliothek jcl-over-slf4j.jar eine Bridge von commons-logging zu slf4j zur Verfügung.
Diese kann wie folgt eingesetzt werden:
-
commons-logging*.jaraus der Anwendung entfernen (bzw. sicherstellen, dass diese durch Maven nicht in die Anwendung integriert werden) -
jcl-over-slf4j.jarin die Anwendung ergänzen
4.2.4.2. Bridge für java.util.logging
SLF4J stellt für die java.util.logging API ebenfalls eine Bridge zur Verfügung (jul-to-slf4j.jar). Um die Bridge zu aktivieren müssen zunächst alle vorhandenen Log-Handler entfernt und danach ein Handler zum Weiterleiten der Log-Aufrufe an SLF4J installiert werden.
| Weitere Informationen über SLF4J unter SLF4JBridgeHandler |
Dies kann wie folgt umgesetzt werden:
-
jul-to-slf4j.jarin die Anwendung ergänzen -
Den folgenden Abschnitt in die Spring-Konfiguration der Anwendung ergänzen:
@Configuration
public class LoggingBridgeConfig {
@Bean
public SLF4JBridgeHandler slf4JBridgeHandler() {
SLF4JBridgeHandler.removeHandlersForRootLogger();
SLF4JBridgeHandler.install();
return new SLF4JBridgeHandler();
}
}5. Vorgaben zur Logerstellung
Die Zielsetzung des Loggings ist es, unterschiedliche Auswertungen zu ermöglichen, um damit verschiedene Problemstellungen und Informationsbedarfe, die während des Betriebs der Systeme entstehen, einfach und effizient beantworten zu können. Grundlage hierfür bildet zum einen die technische Vereinheitlichung des Loggings, die in den vorangegangen Abschnitten (Nutzung und Konfiguration) beschrieben wurde. Zum Anderen muss das Logging jedoch insbesondere auch inhaltlich – also wann wird was geloggt – einheitlich und zielgerichtet im Hinblick auf die verschiedenen Auswertungen erfolgen. Dadurch wird sichergestellt, dass die Logeinträge einfach ausgewertet werden können und alle notwendigen Informationen vorliegen.
Aus diesem Grund werden im folgenden Abschnitt zunächst die verschiedenen Auswertungen beschrieben, die für alle Anwendungen relevant sind. Bei Entwurf eines Systems können systemspezifische Anforderungen definiert werden, die analog zu den hier aufgeführten Themen adressiert werden müssen. Es ist Aufgabe des Technischen Chefdesigners diese Anforderungen im Rahmen des Systementwurfs abzustimmen und zu berücksichtigen.
Die konkreten Szenarien, in denen Logeinträge zu erstellen sind, werden in Logszenarien definiert.
5.1. Auswertungen
In diesem Abschnitt werden Auswertungen beschrieben, die auf den Logs der Anwendungslandschaft durchgeführt werden können müssen. Die Auswertung erfolgt dabei meist durch den Betrieb und nicht durch die Entwickler. Es ist jedoch Aufgabe der Entwickler sämtliche Informationen in den Logs bereitzustellen, so dass die Szenarien effizient durchgeführt werden können.
Es wird zwischen folgenden Akteuren unterschieden:
-
Betrieb: Mitarbeiter der IT-Abteilung, in der das System bzw. die Anwendungslandschaft betrieben wird.
-
Entwickler: Mitarbeiter der Entwicklungsabteilung, durch die die Anwendung entwickelt, gewartet und/oder weiterentwickelt wird.
-
Fachbereich: Mitarbeiter des Fachbereichs / der Fachabteilung, durch die die Anwendung fachlich betreut und geführt wird.
5.1.1. Schwerwiegenden Fehler erkennen und behandeln
| Akteur | Betrieb, Entwickler |
|---|---|
Log-Level |
FATAL |
Kategorie |
FATAL |
Beschreibung |
Schwerwiegende Fehler, von denen sich die Anwendung nicht erholen kann und beendet werden muss ("Unrecoverable Error"), müssen umgehend erkannt werden. Zu diesem Zweck überwacht das betriebliche Monitoring das Log-Level FATAL und alarmiert den Betrieb bei jedem neuen Eintrag. Logeinträge im Level FATAL signalisieren, dass der Systembetrieb unterbrochen ist und der Betrieb schnellstmöglich aktiv werden muss, um die Fehlerursache mit Hilfe der bereitgestellten Informationen zu analysieren, zu beheben und die Anwendung wieder neu zu starten. Falls der Betrieb im Rahmen der Fehleranalyse feststellt, dass die Exception auf einen Fehler in der Anwendung zurückzuführen ist, wird der Logeintrag zur Fehleranalyse an die Entwickler übergeben. Beispiele:
|
5.1.2. Beeinträchtigung des Betriebs erkennen und behandeln
| Akteur | Betrieb, Entwickler |
|---|---|
Log-Level |
ERROR |
Kategorie |
ERROR |
Beschreibung |
Beeinträchtigungen des Systembetriebs (bspw. Netzwerkverbindung kann nicht aufgebaut werden), müssen umgehend erkannt werden. Zu diesem Zweck überwacht das betriebliche Monitoring das Log-Level ERROR und alarmiert den Betrieb bei jedem neuen Eintrag. Logeinträge im Level ERROR signalisieren, dass der Fehler durch die Anwendung behandelt wurde und die Anwendung weiterläuft. Der Betrieb muss jedoch schnellstmöglich aktiv werden, um die Fehlerursache mit Hilfe der bereitgestellten Informationen zu analysieren, zu beheben und damit ein erneutes Auftreten des Fehlers zu verhindern. Falls der Betrieb im Rahmen der Fehleranalyse feststellt, dass die Exception auf einen Fehler in der Anwendung zurückzuführen ist, wird der Logeintrag zur Fehleranalyse an die Entwickler übergeben. Beispiele:
|
5.1.3. Unerwartetes Systemverhalten erkennen und behandeln
| Akteur | Entwickler |
|---|---|
Log-Level |
WARN |
Kategorie |
WARN |
Beschreibung |
Unerwartetes Systemverhalten muss umgehend erkannt werden. Zu diesem Zweck überwacht das betriebliche Monitoring das Log-Level WARN. Die entsprechenden Logeinträge werden an die Entwicklungsabteilung zur Analyse des Verhaltens und Identifikation notwendiger Maßnahmen übergeben. Logeinträge im Level WARN signalisieren, dass der Fehler den Systembetrieb (wahrscheinlich) nicht beeinträchtigt. Die bereitgestellten Informationen richten sich an die Entwickler. Der Betrieb muss im Hinblick auf die Fehleranalyse hierbei zunächst nicht aktiv werden. Beispiele:
|
5.1.4. Betriebliche Überwachung
| Akteur | Betrieb |
|---|---|
Log-Level |
INFO |
Kategorie |
METRIK |
Beschreibung |
Logeinträge können dazu verwendet werden, Statistiken zu ermitteln, um eine betriebliche Überwachung des Systems zu realisieren. Die folgenden Auswertungen werden dazu durchgeführt:
|
5.1.5. Performance überwachen
| Akteur | Betrieb |
|---|---|
Log-Level |
INFO |
Kategorie |
PROFIL |
Beschreibung |
„Performance-Analyse“ meint die Analyse von Laufzeiten an bestimmten kritischen Stellen der Anwendungslandschaft (bspw. an Service-Methoden) und insbesondere deren Entwicklung über die Zeit. Dies wird durchgeführt, um
|
5.1.6. Nutzungshäufigkeit auswerten
| Akteur | Betrieb |
|---|---|
Log-Level |
INFO |
Kategorie |
METRIK |
Beschreibung |
Die Analyse der Nutzungshäufigkeit bestimmter kritischer Stellen der Anwendungslandschaft (bspw. von Service-Methoden oder Komponenten) und insbesondere deren Entwicklung über die Zeit wird zu folgenden Zwecken durchgeführt:
|
5.1.7. Systemzustand und -ereignisse überwachen
| Akteur | Betrieb |
|---|---|
Log-Level |
INFO |
Kategorie |
JOURNAL |
Beschreibung |
Die Analyse des Systemzustands und der Systemereignisse umfasst bspw. welche Version sich mit welcher Konfiguration in Betrieb befand, welche Änderungen vorgenommen wurden, ob die Anwendung gestartet oder beendet wurde, etc. Diese Analyse wird querschnittlich zur Unterstützung der anderen Analysen durchgeführt, um bspw. Fehler auf Änderungen des Systemzustands zurückzuführen, oder Performance-Schwankungen zu erklären. |
5.1.8. Verarbeitung eines Aufrufs in Anwendungslandschaft nachvollziehen
| Akteur | Entwickler |
|---|---|
Log-Level |
INFO |
Kategorie |
JOURNAL |
Beschreibung |
Das Nachvollziehen, durch welche Systeme ein Aufruf der Anwendungslandschaft verarbeitet und weitergeleitet wurde (die Korrelation der Logs zu einem Aufruf aus verschiedenen Systemen), dient den folgenden Zwecken:
|
5.1.9. Fachliche Verarbeitung eines Aufrufs nachvollziehen
| Akteur | Fachbereich |
|---|---|
Log-Level |
INFO |
Kategorie |
JOURNAL |
Beschreibung |
Der Fachbereich kann die Anforderung an ein System stellen, dass die fachliche Verarbeitung eines Aufrufs über das Logging nachvollziehbar sein muss. Hierzu werden an definierten Stellen in der Anwendung spezifische Logeinträge erstellt – bspw. beim Start oder Beenden eines Anwendungsfalls, beim Aufruf einer Anwendungsfunktion etc. Die Anforderungen an das Logging sowie die Auswertung der Logeinträge sind spezifisch für das jeweilige System und müssen mit dem Fachbereich abgestimmt werden. |
5.1.10. Fehleranalyse (Debugging)
| Akteur | Entwickler |
|---|---|
Log-Level |
DEBUG, TRACE |
Kategorie |
DEBUG |
Beschreibung |
Die Fehleranalyse ist das „klassische“ Szenario der Log-Auswertung. Hierbei werden detaillierte Debug-Informationen analysiert, um die Ursache eines Fehlers im Programmcode zu finden und diesen zu beheben. |
5.2. Logszenarien
In diesem Abschnitt werden die verschiedenen Logszenarien beschrieben, die definieren, wann welche Logeinträge zu erstellen sind, um die im vorhergehenden Abschnitt definierten Auswertungen zu ermöglichen.
Die Bibliothek isy-logging stellt bereits einige Mechanismen bereit, durch die die notwendigen Logeinträge für einzelne Auswertungen querschnittlich und rein konfigurativ umgesetzt werden können.
Diese sind in Konfiguration beschrieben.
Logeinträge die individuell in bei der Anwendungsentwicklung zu erstellen sind, sind in Anwendungsentwicklung beschrieben.
Wichtig ist, dass bei der Umsetzung einer Anwendung keine Logeinträge erstellt werden, zu denen es kein Szenario gibt – oder umgekehrt: sollte es sinnvoll sein einen Logeintrag zu erstellen, dann muss dafür auch ein Szenario definiert werden.
Die Szenarien sind nach folgendem Schema aufgebaut:
Beschreibung |
Beschreibung der Situation innerhalb einer Anwendung. |
Logging |
Das durchzuführende Logging. |
Auswertungsszenario |
Die Auswertungen, für die die erstellten Logeinträge verwendet werden. |
5.2.1. Vorgaben für alle Logszenarien
Die folgenden Regeln sind für alle Logeinträge zu beachten:
-
Keine Binärdaten loggen: Binärdaten sind nur schwer auswertbar und führen potentiell zu sehr langen Einträgen. Binärdaten dürfen daher nicht gelogged werden.
-
Größe der Parameter beschränken: Beim Loggen der Schnittstellenkommunikation können durch große Objektstrukturen ebenfalls sehr große Logeinträge entstehen. Das Loggen von Parametern kann durch entsprechende Konfiguration auf eine Maximalgröße beschränkt werden.
-
Größe des Logeintrags beschränken: Große Logeinträge können zu Fehlern bei der weiteren Verarbeitung führen. Daher sollte darauf geachtet werden, dass Logeinträge eine invidiuell definierte maximale Länge nicht überschreiten. Zudem sollte diese maximale Länge in der Konfigurationsdatei
logback.xmldefiniert sein (s. Maximale Länge des Logeintrags festlegen).
5.2.2. Konfiguration
Die folgenden Szenarien können rein konfigurativ umgesetzt werden, mit Mitteln, die durch isy-logging bereitgestellt werden.
Sollte einer dieser Mechanismen in einer Anwendung nicht umgesetzt werden können (bspw. weil die Anwendung nur Teile der IsyFact einsetzt und bspw. Spring nicht verwendet), müssen die entsprechenden Einträge explizit durch Aufruf des Logging-Frameworks erstellt werden.
5.2.2.1. Aufruf an Systemgrenze
Beschreibung |
Es wird eine Außenschnittstelle des Systems – Service, GUI-Controller oder Batch – aufgerufen (eingehender Aufruf). |
Logging |
Der Aufruf der Methode wird mit Hilfe des |
Auswertungsszenario |
|
5.2.2.2. Rückliefern einer Exception an Systemgrenze
Beschreibung |
Beim Aufruf eines Systems ist ein Fehler aufgetreten. Es wird eine Exception an den Aufrufer zurückgegeben. |
Logging |
Es müssen die übermittelten Eingabeparameter mit Hilfe des |
Auswertungsszenario |
|
5.2.2.3. Aufruf an Komponentengrenze
Beschreibung |
Es wird eine Methode einer Komponentenschnittstelle im Anwendungskern aufgerufen (eingehender Aufruf). |
Logging |
Das Loggen von Aufrufen an Komponentengrenzen liefert insbesondere für die Performanceanalyse wichtige Informationen, führt jedoch in den meisten Anwendungen zu einem sehr hohen Logvolumen. Jede Anwendung muss den LogInterceptor gemäß LoggingMethodInterceptor konfigurieren, so dass das Logging an den Komponentengrenzen bei Bedarf aktiviert werden kann. |
Auswertungsszenario |
|
5.2.2.4. Aufruf eines DAOs
Beschreibung |
Es wird eine Methode eines DAOs aufgerufen (eingehender Aufruf). |
Logging |
Der Aufruf der Methode wird mit Hilfe des |
Auswertungsszenario |
|
5.2.2.5. Aufruf eines Nachbarsystems
Beschreibung |
Es wird ein entfernter Service eines Nachbarsystems aufgerufen. |
Logging |
Der Aufruf der Methode wird mit Hilfe des |
Auswertungsszenario |
|
5.2.2.6. Hochfahren / Herunterfahren
Beschreibung |
Ein Anwendungssystem oder ein Batch wird gestartet oder beendet. |
Logging |
Der Vorgang wird durch den |
Auswertungsszenario |
|
5.2.2.7. Neueinlesen eines geänderten Konfigurationsparameters
Beschreibung |
Es wird festgestellt, dass sich ein Konfigurationsparameter der betrieblichen Konfiguration oder eine Laufzeitkonfiguration geändert hat. Der geänderte Wert wird im laufenden Betrieb übernommen. |
Logging |
Es muss ein Logeintrag erstellt werden, der die Änderung des Konfigurationsparameters dokumentiert:
Dies wird durch die Klasse |
Auswertungsszenario |
|
5.2.2.8. Loggen der Schnittstellenkommunikation
Beschreibung |
In Ausnahmefällen kann es notwendig sein, Teile oder die gesamten Daten, die über eine Schnittstelle ausgetauscht werden, zu loggen. Dies ist insbesondere dann der Fall, wenn:
|
Logging |
Das Erstellen der Logeinträge erfolgt mittels des LogInterceptors der bereits für die Szenarien in Schwerwiegenden Fehler erkennen und behandeln und Beeinträchtigung des Betriebs erkennen und behandeln konfiguriert wurde. Zur Ausgabe der Schnittstellenkommunikation muss der Schalter loggeDaten auf true gesetzt werden (LoggingMethodInterceptor). |
Auswertungsszenario |
|
5.2.3. Anwendungsentwicklung
In diesem Abschnitt sind alle Szenarien beschrieben, bei denen Logeinträge im Anwendungscode explizit durch den Entwickler vorzusehen sind.
Wenn durch ein Logszenario ein Eintrag im Level INFO gefordert ist, muss ein entsprechender Ereignisschlüssel definiert werden – dies ist in Ereignisschlüssel beschrieben. Die definierten Schlüssel müssen im Systementwurf dokumentiert werden – analog zu Ereignisschlüssel isy-logging dieses Dokuments.
5.2.3.1. Behandlung einer Exception
Beschreibung |
Es wird eine Exception gefangen und behandelt. Wichtig: Exceptions werden nur geloggt, wenn Sie auch behandelt werden. Wird eine Exception nicht behandelt (also an den Aufrufer weitergereicht), wird sie auch nicht geloggt. |
Logging |
Je nach Schwere des Fehlers wird die Exception in einem der folgenden Log-Level geloggt (siehe Log-Level):
Das Erstellen der Logeinträge erfolgt mittels der Methoden Die Lognachricht muss das eingetretene Szenario kurz und möglichst Präzise beschreiben, bspw.: „Fehler beim Zugriff auf die Datenbank“. Anmerkung: Zur Fehleranalyse sind insbesondere der Fehlerschlüssel, Fehlertext und der Stacktrace relevant. Diese werden automatisch durch das Logging-Framework geloggt und müssen daher nicht manuell in die Lognachricht übernommen werden. |
Auswertungsszenario |
|
5.2.3.2. Wichtige Systemereignisse
Beschreibung |
Es tritt ein wichtiges Ereignis auf, welches für die Durchführung der folgenden Auswertungen relevant ist:
Es ist Aufgabe des technischen Chefdesigners diese Stellen im Rahmen des Systementwurfs zu Identifizieren und mit dem Auftraggeber abzustimmen. |
Logging |
Es muss ein spezifischer Ereignisschlüssel definiert, im Systementwurf dokumentiert und ein Logeintrag im Level INFO erstellt werden.
Tritt an mehreren Stellen in der Anwendung das gleiche zu loggende Ereignis auf, kann der gleiche Ereignisschlüssel verwendet werden. |
Auswertungsszenario |
|
5.2.3.3. Durchführen einer Bulk-Query
Beschreibung |
Es wird eine native SQL-Bulk-Query (Manipulation mehrerer Datensätze) in der Datenbank durchgeführt. |
Logging |
Es muss ein Logeintrag erstellt werden, der die Query beschreibt und die Anzahl der betroffenen Datensätze als Platzhalter enthält: |
Auswertungsszenario |
|
5.2.3.4. Unterstützung der Fehleranalyse (Debug)
Beschreibung |
An allen Stellen der Verarbeitungslogik, die für eine spätere Fehleranalyse relevant sind, müssen entsprechende DEBUG-Einträge erstellt werden. Welche Stellen relevant sind, ist abhängig vom konkreten System und kann nicht allgemein festgelegt werden. Es liegt im Ermessen des Technischen Chefdesigners und der Entwickler, diese Stellen zu identifizieren. Typische Szenarien sind:
|
Logging |
Das Erstellen der Logeinträge erfolgt mittels der Methode:
Anmerkung: Für eine detaillierte Fehleranalyse ist es natürlich meist unerlässlich auch den Programmcode einzusehen. Durch die verständliche Formulierung der Logeinträge kann der Hergang, der zu einem Fehler geführt hat, jedoch viel einfacher und schneller nachvollzogen werden und damit die Fehlerquelle schneller identifiziert werden. |
Auswertungsszenario |
|
5.2.3.5. Fachliche Korrelation von Einträgen
Beschreibung |
In komplexen Verfahren kann es notwendig sein, die erstellten Logeinträge fachlich in Verbindung zueinander zu setzen – bspw. Kennzeichnen aller Logeinträge, die sich auf einen bestimmten Datensatz beziehen, durch Aufnahme des eindeutigen Schlüssel des betroffenen Datensatzes. Wenn diese Anforderung gegeben ist, kann dies beim Aufruf an der Systemgrenze (vgl. Szenario Aufruf an Systemgrenze) wie im Folgenden beschrieben berücksichtigt werden. |
Logging |
An der Systemgrenze wird der eindeutige Schlüssel des Datensatzes in den MDC aufgenommen. Dabei müssen folgende Aspekte berücksichtigt werden:
|
Auswertungsszenario |
|
5.2.3.6. Loggen fachlicher Operationen
Beschreibung |
Der Fachbereich hat für das System Anforderungen definiert, dass die Verarbeitung einzelner Aufrufe fachlich nachvollziehbar sein muss. Dies ist im Auswertungsszenario „Fachliche Verarbeitung eines Aufrufs nachvollziehen“ (siehe Fachliche Verarbeitung eines Aufrufs nachvollziehen) beschrieben. |
Logging |
Die zu erstellenden Logeinträge sind spezifisch für das jeweilige Verfahren. Zu beachten ist jedoch, dass die Aufrufe im Log-Level INFO zu erstellen sind. Für alle Logeinträge, die dem gleichen Zweck dienen (also der gleichen fachlichen Anforderung), muss der gleiche Ereignisschlüssel verwendet werden. |
Auswertungsszenario |
|
6. Ereignisschlüssel isy-logging
Im Folgenden werden die spezifischen Ereignisschlüssel der Komponente isy-logging beschrieben:
| Schlüssel (s.u.) | Level | Kategorie | Text |
|---|---|---|---|
|
INFO |
JOURNAL |
Methode <Klasse.Methode> wird aufgerufen. |
|
INFO |
METRIK |
Aufruf von <Klasse.Methode> erfolgreich beendet. |
|
INFO |
METRIK |
Aufruf von <Klasse.Methode> mit Fehler beendet. |
|
INFO |
PROFILING |
Aufruf von <Klasse.Methode> erfolgreich beendet. Der Aufruf dauerte <Dauer in Millisekunden> ms. |
|
INFO |
PROFILING |
Aufruf von <Klasse.Methode> mit Fehler beendet. Der Aufruf dauerte <Dauer in Millisekunden> ms. |
|
INFO |
JOURNAL |
Die Methode <Klasse.Methode> des Nachbarsystems <systemname> wird unter der URL <url> aufgerufen. |
|
INFO |
METRIK |
Aufruf von <Klasse.Methode> des Nachbarsystems <systemname> unter der URL <url> erfolgreich beendet. |
|
INFO |
METRIK |
Aufruf von <Klasse.Methode> des Nachbarsystems <systemname> unter der URL <url> mit Fehler beendet. |
|
INFO |
PROFILING |
Aufruf von <Klasse.Methode> des Nachbarsystems <systemname> unter der URL <url> erfolgreich beendet. Der Aufruf dauerte <Dauer in Millisekunden> ms. |
|
INFO |
PROFILING |
Aufruf von <Klasse.Methode> des Nachbarsystems <systemname> unter der URL <url> mit Fehler beendet. Der Aufruf dauerte <Dauer in Millisekunden> ms. |
|
INFO |
JOURNAL |
ApplicationContext des Systems <Systemname> (Systemart) wurde gestartet oder aktualisiert. |
|
INFO |
JOURNAL |
Der ApplicationContext des Systems <Systemname> (Systemart) wurde gestopped. |
|
INFO |
JOURNAL |
Die Systemversion ist <Versionsnummer>. |
|
INFO |
JOURNAL |
Der Laufzeitparameter <Parametername> besitzt den Wert <Wert>. |