Detailkonzept Anwendungskern
![]() Diese Seite ist ein Teil der IsyFact-Standards.
Alle Inhalte der Seite, insbesondere Texte und Grafiken, sind urheberrechtlich geschützt.
Alle urheberrechtlichen Nutzungs- und Verwertungsrechte liegen beim Bundesverwaltungsamt.
Diese Seite ist ein Teil der IsyFact-Standards.
Alle Inhalte der Seite, insbesondere Texte und Grafiken, sind urheberrechtlich geschützt.
Alle urheberrechtlichen Nutzungs- und Verwertungsrechte liegen beim Bundesverwaltungsamt.
 Die Nutzung ist unter den Lizenzbedingungen der Creative Commons Namensnennung 4.0 International gestattet.
Die Nutzung ist unter den Lizenzbedingungen der Creative Commons Namensnennung 4.0 International gestattet.
1. Einleitung
Im Anwendungskern werden die fachlichen Funktionen der Anwendung realisiert. Diese Funktionen sind im Anwendungskern genau einmal implementiert und können von unterschiedlichen Komponenten einer Anwendung genutzt werden. Eine Meldung in einer Geschäftsanwendung kann z.B. sowohl über die GUI als auch über einen Batch oder einen Serviceaufruf vorgenommen werden. Alle diese Aufrufer nutzen dieselbe Implementierung. Der Anwendungskern wird aus Fachkomponenten und Komponenten zur Nutzung externer Services aufgebaut.
Die Implementierung wird durch die Verwendung eines Anwendungskern-Frameworks unterstützt. Die Hauptaufgabe des Anwendungskern-Frameworks ist es, die Komponenten zu konfigurieren und miteinander bekannt zu machen. Als zentrales Framework für die Implementierung des Anwendungskerns wird das Spring-Framework verwendet.
Neben der Verwendung als Anwendungskern-Framework, bietet das Spring-Framework auch weitere Funktionalität, die die Entwicklung von Anwendungen für die Plattform vereinfacht.
Dieses Dokument richtet sich an Architekten und Entwickler. Neben der Festlegung der Architektur des Anwendungskerns ist die Hauptaufgabe dieses Dokuments, die Verwendung von Spring als Anwendungskern-Framework zu erläutern. Daher werden im Folgenden Spring-Kenntnisse vorausgesetzt.
2. Überblick
Gemäß den Vorgaben der Referenzarchitektur der Referenzarchitektur basiert die Architektur eines IT-Systems auf der bekannten Drei-Schichten-Architektur. Eine dieser Schichten ist die Anwendungskernschicht mit der Komponente Anwendungskern.
Im Anwendungskern werden die fachlichen Funktionen der Anwendung realisiert. Dazu gehören zum Beispiel Datenvalidierungen oder Funktionen zum Verarbeiten von Geschäftsobjekten, die über die Komponente Datenzugriff geladen wurden. Außerdem übernimmt der Anwendungskern die Transaktionssteuerung. In Richtung Nutzungsschicht bietet der Anwendungskern nur Funktionalitäten an, die allgemein verwendbar sind und die im Prinzip von mehreren Nutzern verwendet werden könnten.
In folgender Abbildung ist die Referenzarchitektur eines IT-Systems grafisch dargestellt, wobei die Anwendungskernschicht mit der Komponente Anwendungskern hervorgehoben ist.

In diesem Dokument werden die Vorgaben zum Bau der Komponente Anwendungskern im Detail beschrieben. Als zentrales Framework für die Implementierung des Anwendungskerns wird das Spring-Framework verwendet.
Neben der Verwendung als Anwendungskern-Framework bietet das Spring-Framework auch weitere Funktionalität, die die Entwicklung von Anwendungen für die Plattform vereinfacht. Daher werden in diesem Dokument auch Aspekte des Spring-Frameworks behandelt, die über die Verwendung im Anwendungskern hinausgehen.
3. Aufbau des Anwendungskerns
Der Anwendungskern ist der zentrale Baustein eines IT-Systems. Hier werden die fachlichen Funktionen der Anwendung realisiert.
Der Anwendungskern besteht aus zwei wesentlichen Bestandteilen: den Fachkomponenten und dem Anwendungskern-Framework. Weiterhin ist dort dargestellt, dass externe Services als Komponente in den Anwendungskern integriert sind. Diese drei Aspekte werden im Folgenden im Detail beschrieben.
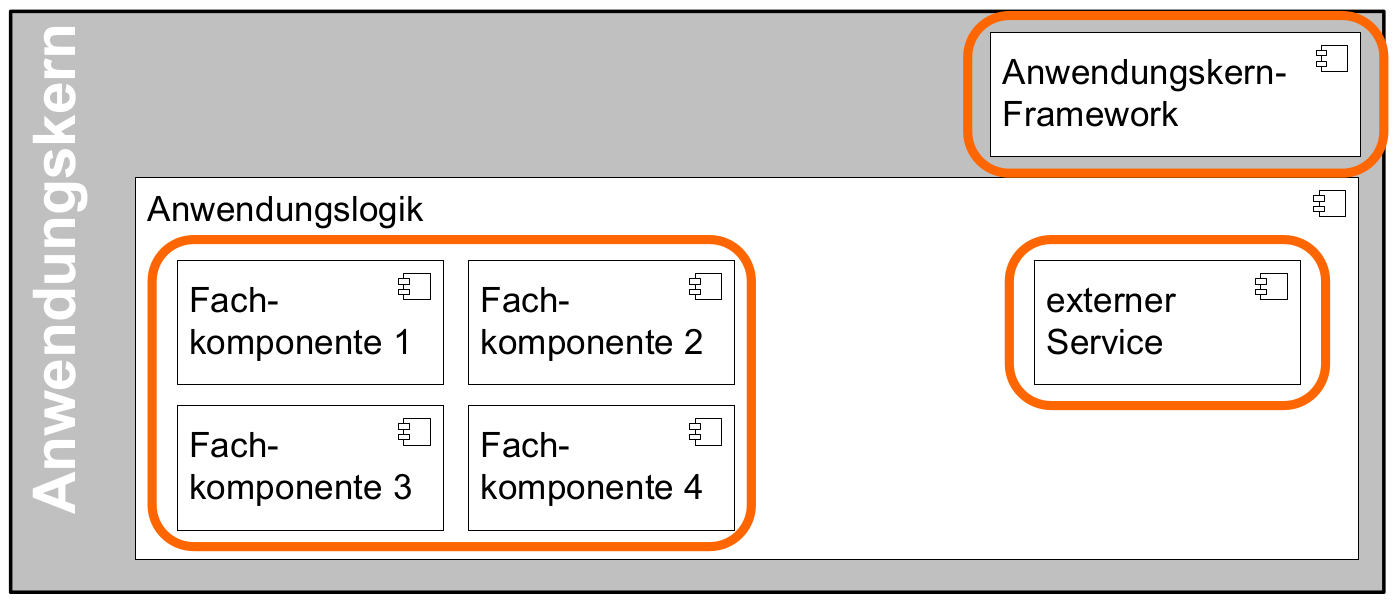
3.1. Fachkomponenten
Fachkomponenten setzen die Anwendungskomponenten aus der fachlichen Architektur um. Sie bilden damit den Schnitt der Anwendungskomponenten in die technische Architektur ab. Fachkomponenten beinhalten möglichst wenig Technik und trennen so Anwendungslogik von Technologie.
Eine allgemeine Anwendung enthält die Fachkomponenten Erstellung, Teilnahme und Verwaltung.
| Fachkomponenten sind der Schlüssel für gute Wartbarkeit und einfache Weiterentwickelbarkeit des Anwendungskerns. Die Trennung von Anwendungslogik und Technik ist deshalb auch in anderen Schichten der technischen Architektur vorgesehen, z. B. in der Persistenz. |
Von außen betrachtet besteht jede Fachkomponente aus einer Schnittstelle (Interface) und den von ihr verwendeten Geschäftsobjekten (Model) sowie Ausnahmen (Exceptions). Alle Zugriffe auf die Fachkomponente von außen, auch von anderen Fachkomponenten aus, geschehen über die Schnittstelle.
Die Schnittstelle stellt eine Fassade (Facade) für mindestens eine Anwendungsfallklasse dar. Die Aufgaben der Schnittstelle sind:
-
Aufrufe von außen entgegenzunehmen,
-
Aufrufe an die entsprechenden Anwendungsfallklassen weiterzuleiten,
-
Antworten der Anwendungsfallklassen an den Aufrufer zurück zu übermitteln,
-
Ausnahmen der Anwendungsfallklassen in Ausnahmen der Schnittstelle zu übersetzen.
Geschäftsobjekte dienen zur Kommunikation der Fachkomponente nach außen sowie zur Umsetzung der Fachlichkeit (z.B. für interne Berechnungen). Sie werden im Anwendungskern definiert, sind nicht persistent und können in der Nutzungsschicht wiederverwendet werden, sofern hierfür keine Anpassungen durch Mappings o.ä. nötig sind. Ein Geschäftsobjekt ist genau einer Fachkomponente zugeordnet, welche die Hoheit über es besitzt und seinen Lebenszyklus verwaltet. Sie werden primär nach ihrer Funktion benannt.
| Geschäftsobjekt | |
|---|---|
Schema |
|
Beispiel |
|
In einer allgemeinen Anwendung gibt es z.B. die Geschäftsobjekte Aufgabe, Zeitpunkt und Nutzer.
In Ausnahmefällen können Geschäftsobjekte fachlich nicht genau einer Komponente zugeordnet werden. Hierfür wird die Komponente Basisdaten definiert, die nur die eine Aufgabe hat, solche Geschäftsobjekte an zentraler Stelle zu verwalten.
Eine Anwendungsfallklasse setzt genau einen Anwendungsfall um.
Ihr Schnitt ergibt sich aus der fachlichen Architektur.
Anwendungsfallklassen werden anhand des Namens des Anwendungsfalls aus der Spezifikation benannt und mit dem Präfix Awf gekennzeichnet.
| Anwendungsfallklassen | |
|---|---|
Schema |
|
Beispiele |
|
Eine Anwendungsfunktion setzt Teil-Abläufe um, die in mehreren Anwendungsfällen verwendet werden.
Anwendungsfunktionen werden somit von Anwendungsfallklassen aufgerufen.
Anwendungsfunktionen werden anhand des Namen der Anwendungsfunktion aus der Spezifikation benannt und mit dem Präfix Afu gekennzeichnet.
| Anwendungsfunktion | |
|---|---|
Schema |
|
Beispiele |
|
Die folgende Abbildung fasst den Aufbau einer Fachkomponente noch einmal grafisch zusammen.

3.2. Anwendungskern-Framework
Für querschnittliche Funktionalität innerhalb des Anwendungskerns wird das Spring-Framework genutzt. Hauptaufgabe des Frameworks ist es, die Komponenten zu konfigurieren und miteinander bekanntzumachen. Dadurch wird die Trennung zwischen Fachlichkeit und Technik verbessert. Beispiel für querschnittliche Funktionalität ist die deklarative Steuerung von Transaktionen.
Die Vorgaben zur Nutzung und Konfiguration des Spring-Frameworks werden in Kapitel Verwendung des Spring-Frameworks beschrieben.
3.3. Externe Services
Wenn der Anwendungskern fachliche Services benötigt, die von anderen IT-Systemen innerhalb der Plattform angeboten werden, so werden diese Services als Komponente im Anwendungskern abgebildet. Dadurch ist die Funktionalität sauber gekapselt, was die Wartbarkeit erhöht: Wenn der externe Service ausgetauscht werden soll, ist keine Änderung der gesamten Anwendung notwendig – es ist lediglich eine interne Änderung der externen Service-Komponente notwendig. Für andere fachliche Komponenten des Anwendungskerns ist nicht zu unterscheiden, ob es sich beim Aufruf einer Komponentenschnittstelle um eine in dieser Komponente implementierte Funktion oder um einen Serviceaufruf handelt. Komponenten, die externe Services kapseln, sind im Idealfall von außen nicht von fachlichen Komponenten des Anwendungskerns unterscheidbar. Neben der technischen Kommunikation erfolgt durch diese Komponenten auch die Abbildung von Schnittstellendaten und Exceptions auf die Daten der Anwendung.
3.4. Austausch von Geschäftsobjekten
Der Anwendungskern hat die Hoheit über die Geschäftsobjekte des IT-Systems. In Referenzarchitektur wurde bereits beschrieben, dass zur Strukturierung eines IT-Systems zwei Sichten verwendet werden können:
Technische Sicht: Die technische Sicht unterteilt die IT-Anwendung in Schichten für die jeweils eigene Technologien verwendet werden: Nutzung (GUI, Batch und Service), Anwendungskern und Datenzugriff. Das Ziel ist es, eine Durchmischung von Technologien zu verhindern, so darf z. B. in der GUI kein SQL formuliert werden.
Fachliche Sicht: Die fachliche Sicht beschreibt eine Teilaufgabe, z. B. Meldung, Auskunft oder Fristenkontrolle. Innerhalb dieser Teilaufgabe wird der Anwendungskern über eine GUI, Services oder Batches angesprochen, der wiederum über die Datenzugriffsschicht mit der Datenbank kommunizieren muss. Daher zerlegt die fachliche Sicht das IT-System in fachliche Säulen. Diese fachlichen Säulen werden im folgenden Teilanwendungen genannt. Das Ziel ist die fachliche Trennung und Minimierung inhaltlicher Abhängigkeiten. Die Teilanwendungen sollen Fachlichkeit kapseln.
Damit kann eine IT-Anwendung sowohl vertikal in Teilanwendungen (fachliche Sicht) und horizontal in Schichten (technische Sicht) strukturiert werden, wie die folgende Abbildung verdeutlicht.
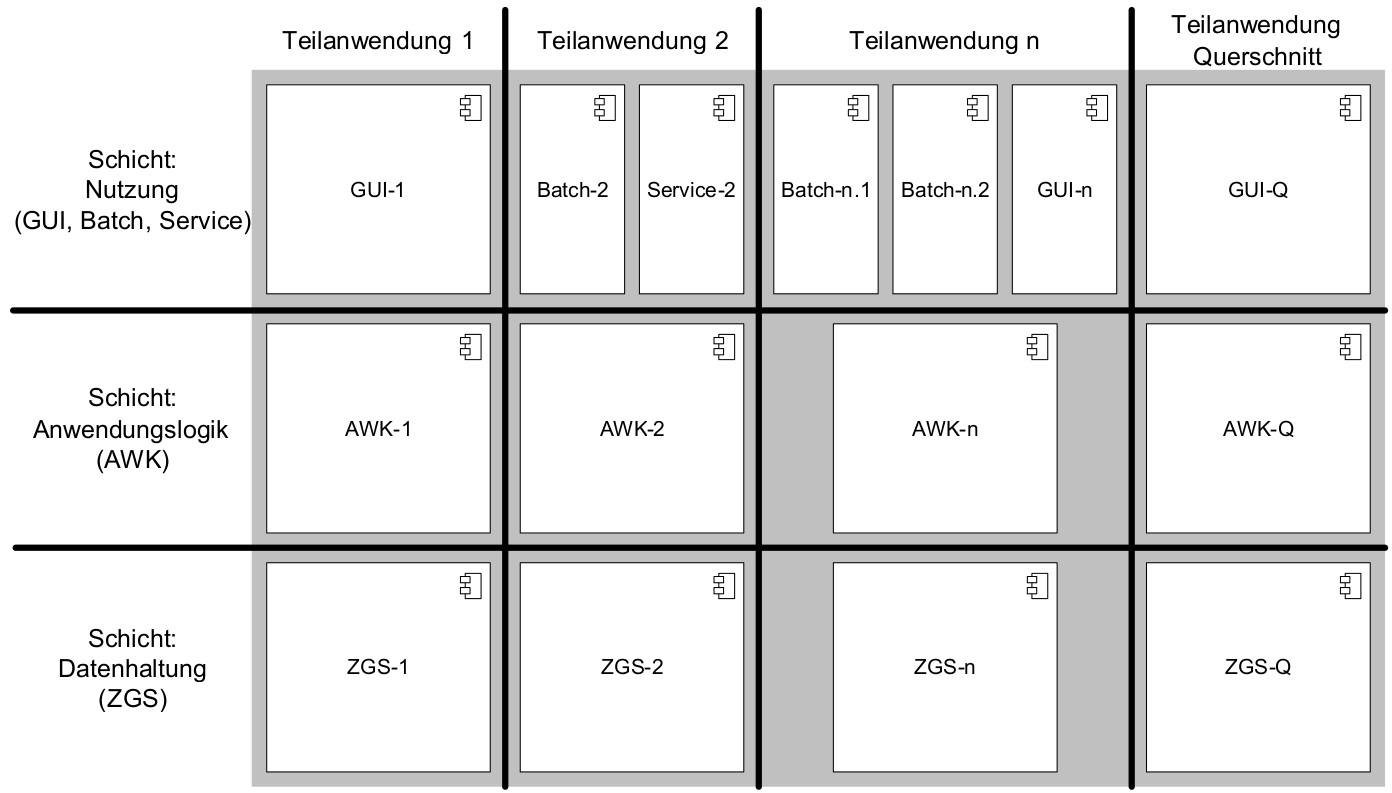
Eine Teilanwendung erstreckt sich über alle technischen Schichten, kapselt aber die Fachlichkeit, zu der gewisse Geschäftsobjekte gehören. Um den Austausch von Objekten innerhalb einer Teilanwendung zwischen den Schichten zu vereinfachen, gleichzeitig aber unterschiedliche Teilanwendungen gegeneinander abzugrenzen, wird für die Verwendung von Objekten in Schnittstellen folgende Regel aufgestellt:
-
Zwischen zwei Teilanwendungen dürfen nur Objekte ausgetauscht werden, deren Modifikation keine Auswirkungen auf die liefernde Teilanwendung hat.
Das kann erreicht werden, indem nur Deep-Copies von Objekten an andere Teilanwendungen herausgegeben werden.
Innerhalb einer Teilanwendung dürfen über die Schichten hinweg durchaus änderbare Objekte ausgetauscht werden. Die hierfür bereitgestellte Schnittstelle der Schicht gehört damit aber zur Teilanwendung darf von einer anderen Teilanwendung nicht genutzt werden.
In einer allgemeinen Anwendung ist z.B. „Aspektanwendung“ eine Teilanwendung.
Zu dieser Teilanwendung gehören in der Schicht Nutzung die Oberfläche Aspektanwendung und der Batch AspektanwendungLoeschBatch, in der Schicht Anwendungslogik die Fachkomponenten Erstellen, Verwalten und Datenpflege und in der Schicht Datenhaltung die Entitäten Aspektanwendung, Zeitpunkt, Nutzer, Intervall und Nutzerintervall.
4. Verwendung des Spring-Frameworks
Das Spring-Framework ist ein Java EE Framework, welches im Kern sehr verständlich und leicht zu verwenden ist. In ihm werden die Bestandteile eines Systems als „Beans“ definiert. Neben seiner Kern-Funktionalität der Verwaltung, Konfiguration und aspektorientierten Erweiterung von Beans bietet Spring viele Funktionalitäten, welche die Entwicklung einer Anwendung erleichtern sollen.
Die IsyFact verwendet ausgewählte Funktionalitäten des Spring-Frameworks in der Anwendungsentwicklung. Die Verwendung dieser Funktionalitäten ist in den Blaupausen und Bausteinen wie folgt beschrieben:
-
Konfiguration der Datenzugriffsschicht: beschrieben im Nutzungskonzept des Bausteins JPA/Hibernate,
-
Konfiguration des Logging über Spring: beschrieben in den Nutzungsvorgaben Logging,
-
Bereitstellung von Metriken zur Überwachung: beschrieben im Konzept Überwachung,
-
Verwendung der Schnittstellentechnologie HttpInvoker: beschrieben im Konzept HttpInvoker,
-
Implementierung von Dialogen und Masken mit JSF und Spring-Webflow: beschrieben im Detailkonzept Web-GUI.
Alle anderen Spring-Funktionalitäten (Validierung über Spring, Emailing, Thread Pooling, Scripting) werden nicht verwendet.
Dieses Kapitel teilt sich in vier Teile:
-
Die Auflistung der Anforderungen an die Verwendung des Spring-Frameworks.
-
Die Vorgaben für die Konfiguration der Spring-Beans sowie von Spring selbst.
-
Die Vorgaben für den direkten Zugriff auf das Spring-Framework in der Anwendung.
-
Die Vorgaben für aspektorientierte Programmierung mit Spring.
4.1. Anforderungen
Dies bezieht sich unter anderem auf die Bestandteile von Spring: Spring bietet verschiedene Komponenten, welche getrennt voneinander eingesetzt werden können. Es sollen nur die Komponenten eingesetzt werden, welche zu geringerer Komplexität und geringerem Entwicklungsaufwand führen.
Einheitlichkeit der Nutzung: Spring soll in den verschiedenen Anwendungen einheitlich eingesetzt werden. Hierfür sind geeignete Vorgaben für die Nutzung zu verwenden.
Verständlichkeit der Konfiguration: Die Konfiguration der Spring-Komponenten erfolgt über Annotationen an den Komponenten. Wenn erforderlich, werden Komponenten außerhalb der Anwendung über Java-Konfigurationsklassen konfiguriert.
Komponentenorientierung wahren: Über Spring sollen Komponenten konfiguriert werden: Es soll nicht möglich sein, direkt auf Implementierungsklassen einer Komponente zuzugreifen.
4.2. Konfiguration von Spring
Das grundlegende Konzept von Spring ist das der Spring-Bean. Die Konfiguration von Spring teilt sich deshalb in zwei Teile: in die Konfiguration der Spring-Beans sowie in die Konfiguration von Spring selbst (innerhalb eines Tomcat Servers). Um die Konfiguration von Spring und der eingesetzten Bausteine einfach zu halten, werden die Autokonfigurationsmechanismen von Spring Boot eingesetzt. Diese Konfigurationsarten werden in den folgenden Kapiteln beschrieben.
4.2.1. Die Konfiguration von Spring-Beans
Spring ist ein Applikations-Container, welcher sogenannte Spring-Beans instanziiert, per Dependency Injection konfiguriert und bereitstellt.
Spring-Beans sind beliebige Java-Klassen.
Für diese Klassen kann man benötigte andere Beans oder Konfigurationsparameter konfigurieren, welche der Klasse daraufhin im Konstruktor oder per set-Methode übergeben werden.
Konfiguriert werden Beans und ihre Abhängigkeiten durch von Spring bereitgestellte Annotationen. Diese werden beim Start des Applikations-Containers gescannt und ausgewertet (Component Scan).
Ein Spring-Beans Beispiel zeigt einen Ausschnitt der für eine allgemeine Anwendung erstellten Beans. Beans werden grün dargestellt und besitzen „referenzierte“ Abhängigkeiten zu benötigten anderen Beans.

Das Beispiel zeigt bereits, dass nicht alle Klassen der Anwendung als Beans konfiguriert werden:
Für die Komponente Verwaltung wird eine Klasse als Bean konfiguriert, welche die Funktionalität der Komponente bereitstellt.
Generell gilt, dass jede zentrale und wichtige Klasse aber als Spring Bean konfiguriert werden sollte.
Für die Modellierung und Konfiguration der Spring-Beans werden im folgenden Vorgaben aufgestellt.
4.2.1.1. Konfiguration einer Fachkomponente
Eine Komponente sollte durchgängig über Spring konfiguriert werden. Alle relevanten und zentralen Klassen werden daher als Spring Beans konfiguriert. Das umfasst vor allem, aber nicht ausschließlich, die Fassade und zugehörige Anwendungsfallklassen.
Ein Beispiel dafür ist die Klasse VerwaltungImpl einer allgemeinen Anwendung.
Bei Anwendungsfunktionsklassen oder Hilfsklassen ist je nach Relevanz zu entscheiden, ob diese als eigene Spring Beans definiert werden. Im Zweifel sollte die Konfiguration über Spring bevorzugt werden. Wenn eine Klasse nur an einer Stelle genutzt wird, kann sie als Kompromiss auch als anonyme Spring Bean definiert werden. Sind Klassen nicht von relevanter Bedeutung, so können sie beim Erzeugen der Spring Bean programmatisch erzeugt werden.
4.2.1.2. Querschnittliche Funktionalität als Beans konfigurieren
Querschnittliche Funktionalität (etwa für JMX, für Nachrichten, für die Versendung von Mails) sind als Beans zu konfigurieren. Ebenfalls über Beans durchzuführen ist die Konfiguration diverser Frameworks, z.B. Hibernate. Die Konfiguration dieser Frameworks wird in ihren Nutzungsvorgaben beschrieben.
4.2.1.3. Beans standardmäßig als Singletons definieren
Beans können entweder als Singletons mit nur einer Instanz, mit einer Instanz pro Aufruf oder mit einer Instanz pro Abhängigkeit (Prototype) erzeugt werden. Die Komponenten-Beans einer Anwendung sollen zustandslos sein und werden als Singleton-Beans erzeugt. Wo technisch erforderlich können auch andere Scopes verwendet werden.
4.2.1.4. Vorgaben zur Spring-Konfiguration
Die Spring-Konfiguration der Anwendung ist nach folgenden Vorgaben zu erstellen.
Der zentrale Ausgangspunkt für die Spring-Konfiguration ist die Applikationsklasse der Anwendung (Listing 1).
Diese wird im Wurzelpackage der Anwendung (<org>.<domäne>.<anwendung>.<anwendung>Application) erstellt.
Sie ist mit @Configuration und @EnableAutoConfiguration annotiert.
Damit wird die Autokonfiguration von Spring Boot eingeschaltet.
Zusätzlich erbt die Klasse von SpringBootServletInitializer, damit die Anwendung im Tomcat deployt werden kann.
Die Konfigurationsklassen der Schichten werden per @Import-Annotation eingebunden.
package de.beispiel.if2anwendung;
...
@Configuration
@EnableAutoConfiguration
@Import({ CoreConfig.class, PersistenceConfig.class, ServiceConfig.class })
public class IsyFactApplication extends SpringBootServletInitializer {
@Override
protected SpringApplicationBuilder configure(SpringApplicationBuilder application) {
return application.sources(IsyFactApplication.class);
}
}Für jede Schicht wird im Stammpackage <org>.<domäne>.<anwendung>.<schicht> parallel zu den Interfaces der Komponentenschnittstellen eine mit @Configuration annotierte Konfigurationsklasse erstellt (Listing 2).
Diese wird zusätzlich mit @ComponentScan annotiert;
durch die Positionierung im Stammpackage entfällt der Bedarf, ein Attribut zu übergeben.
Annotationen, die querschnittliche Aspekte konfigurieren (z.B. @EnableTransactionManagement), werden an die Konfigurationsklasse der inhaltlich passenden Schicht geschrieben.
package de.beispiel.if2anwendung.core;
...
@Configuration
@EnableTransactionManagement
@ComponentScan
public class CoreConfig {
@Bean
public ...
}Die Beans der Komponenten werden mit der Annotation @Component bzw. deren Spezialisierungen (@Repository, @Service, @Controller etc.) versehen.
Externe Beans, die nicht annotiert werden können, werden in der Konfigurationsklasse der Schicht per @Bean-Methoden konfiguriert.
4.2.2. Konfigurationsparameter über Property-Objekte konfigurieren
Die Konfiguration der Anwendung wird (wie im Konzept Konfiguration beschrieben) über die Datei application.properties durchgeführt.
Diese Datei enthält sämtliche betrieblichen Konfigurationsparameter der Anwendung.
Das Setzen einzelner Konfigurationsparameter über set-Methoden ist nur in Ausnahmefällen erlaubt.
Eine beispielhafte Konfiguration hat folgenden Inhalt:
package de.beispiel.if2anwendung.core.config;
...
@Configuration
@ComponentScan("de.bund.bva.pliscommon.konfiguration.common.impl")
public class ReloadablePropertyKonfiguration {
@Bean
public ReloadablePropertyKonfiguration config() {
return new ReloadablePropertyKonfiguration(String[]{
"/resources/nachrichten/gui-linksnavigation.properties",
"/config/isy-webgui.properties",
"/config/allgemeine-anwendung.properties",
"/config/jpa.properties",
"/config/tasks.properties"
});
}
}Abweichungen für technische Beans sind erlaubt.
4.2.2.1. Abhängigkeiten von Komponenten konfigurieren
Benötigte Beans müssen über Konstruktor-Parameter injiziert werden.
Falls eine benötigte Bean nicht zum Zeitpunkt der Objekterzeugung vorhanden sein muss, sollte sie über eine set-Methode und nicht über einen Konstruktor-Parameter konfiguriert werden.
Grund dafür ist, dass bei Konstruktor-Parametern eine zusätzliche Reihenfolge-Abhängigkeit erzeugt wird.
Für den Fall, dass eine Bean Code zur Initialisierung ausführen soll, nachdem ihre Abhängigkeiten gesetzt sind, ist eine mit @PostConstruct annotierte Methode zu implementieren.
Generell sind die standardisierten Lifecycle-Annotationen @PostConstruct und @PreDestroy den spring-spezifischen Interfaces InitializingBean und DisposableBean vorzuziehen.
4.2.3. webAppRootKey konfigurieren
Der Kontextparameter webAppRootKey muss in der web.xml auf den eindeutigen Namen der Webanwendung gesetzt werden, wie in Listing 4 gezeigt.
<context-param>
<param-name>webAppRootKey</param-name>
<param-value>allgemeine-anwendung</param-value>
</context-param>Hintergrund: Spring speichert standardmäßig den Pfad zum Wurzelverzeichnis der Webanwendung im Webserver in der Kontextvariable webapp.root.
Wenn mehrere Anwendungen gleichzeitig in einem Tomcat betrieben werden (bspw.
in einer Entwicklungsumgebung), wird dieser Parameter durch die verschiedenen Anwendungen überschrieben.
Dies kann zu ungewünschten Seiteneffekten führen.
Ist der Kontextparameter webAppRootKey wie im obigen Beispiel gesetzt, wird der Pfad statt im Parameter webapp.root
im Parameter allgemeine-anwendung abgelegt.
Da jede Webanwendung einen eindeutigen Namen besitzt, und damit einen eigenen Kontextparameter verwendet, wird das Überschreiben vermieden.
4.3. Die direkte Verwendung des Spring-Frameworks
Neben der Konfiguration der Beans enthält eine Anwendung kaum Abhängigkeiten von Spring: Da die benötigten Objekte per Dependency Injection konfiguriert werden, müssen diese nach ihrer Konfiguration lediglich verwendet werden.
In einigen Fällen existieren jedoch weitere Abhängigkeiten von Spring:
-
Für die Bereitstellung von JMX-Beans wird der Spring-MbeanExporter Mechanismus verwendet (siehe Konzept Konfiguration).
-
Bei HTTP Invoker Schnittstellen-Beans muss explizit eine Bean des eigentlichen Anwendungskontextes aufgerufen werden (siehe Nutzungsvorgaben HTTP-Invoker).
-
Beans werden per Namen aus dem Anwendungskontext ausgelesen.
-
Beans werden nicht per Dependency Injection, sondern über statische Methoden bereitgestellt. Hierüber entstehen Abhängigkeiten zur Instanziierungsreihenfolge der Beans durch Spring.
Für die noch nicht in anderen Konzepten besprochenen (letzten beiden) Themen werden im folgenden Vorgaben aufgestellt.
4.3.1. Keine Beans per Namen auslesen
Über den Anwendungskontext könnten Beans explizit per Namen ausgelesen werden. Dies ist mit einer Ausnahme verboten: Die Namen von Beans sollen nicht im Anwendungscode verwendet werden. Die Ausnahme gilt für den Zugriff von einem Anwendungskontext auf einen anderen (in Zusammenhang mit dem DispatcherServlet). In diesem Fall ist ein explizites Auslesen nicht zu vermeiden. Auszulesen ist in diesem Fall keine AWK-Komponente, sondern eine weitere Schnittstellen-Bean, welche nur für diesen Zweck verwendet wird.
4.4. Transaktionssteuerung
An der Schnittstelle des Anwendungskerns findet die Transaktionssteuerung statt. Jeder Aufruf wird in einer eigenen Transaktion abgearbeitet. Die Transaktion wird beim Aufruf des Anwendungskerns gestartet und mit der Rückgabe des Ergebnisses abgeschlossen (Commit) und somit beendet. Falls bei der Verarbeitung einer Anfrage ein nicht behebbarer Fehler auftritt, wird dieser an den Aufrufer zurück übermittelt. In diesem Fall wird die Transaktion nicht fortgeschrieben, sondern zurückgerollt (Rollback).
Der Anwendungskern bietet an seiner Schnittstelle fachliche Operationen, in fachliche Komponenten gruppiert, an. Die fachlichen Operationen sind in der Regel zustandslos. Daher ist eine Transaktion über mehrere Aufrufe des Anwendungskerns oder ein Caching über Transaktionsgrenzen hinaus nicht notwendig und nach Möglichkeit zu vermeiden. Ist eine solche Steuerung trotzdem unumgänglich, muss sie über die jeweils zuständige Nutzungsschicht (GUI, Batch oder Service) erfolgen.
|
Details zur Umsetzung von Transaktionen in der Nutzungsschicht finden sich in den jeweiligen Detailkonzepten: |
4.4.1. Transaktionssteuerung mit JPA
Spring ermöglicht es, die Transaktionssteuerung mit Annotationen zu definieren. Hierbei kann auf Ebene einzelner Methoden oder der gesamten Klasse das Verhalten von Transaktionen vorgegeben werden.
Im Anwendungskern bieten sich dazu sich die Klassen der Implementierung der Schnittstelle an, die Aufrufer weiter an die Anwendungsfall-Klassen verweisen. Üblicherweise werden für eine feingranulare Steuerung die Methoden mit Annotationen versehen. Gibt es ein für die Klasse gemeinsames Verhalten, kann stattdessen auch die Klasse mit der Annotation versehen werden.
@Transactional(rollbackFor = Throwable.class, propagation = Propagation.REQUIRED)
public class FachkomponenteAImpl implements FachkomponenteA {
...
@Transactional(rollbackFor = Throwable.class, propagation = Propagation.REQUIRED)
public Ergebnis fachlicheOperation(Aufrufparameter parameter) {
...
}
...
}Standardmäßig sollte der Propagation-Level auf Propagation.REQUIRED gesetzt sein.
Damit wird eine neue Transaktion gestartet, falls noch keine Transaktion vorliegt.
Hat aber die Nutzungsschicht bereits eine Transaktion gestartet, wird diese verwendet.
Des Weiteren wird festgelegt, dass bei jedem Fehler ein Rollback durchgeführt wird.
Damit Spring die Annotation @Transactional auswertet, muss folgende Spring-Konfiguration aktiv sein:
@EnableTransactionManagement
[...]
public class CoreConfig
{
...
}Durch diese Konfiguration erzeugt Spring passende AOP-Proxies, welche die Transaktionssteuerung übernehmen.
4.5. Aspektorientierte Programmierung in Spring
Es ist möglich, für Spring-Beans Funktionalität in Form von Aspekten zu definieren. Ihr Einsatz kann über „PointCuts“ konfiguriert werden. Pointcuts definieren (etwa über reguläre Ausdrücke) Klassen und Methoden, welche um den Aspekt erweitert werden.
Zu intensive Nutzung kann leicht zu einem schwer durchschaubaren Programmfluss führen. Deshalb soll AOP nur für folgende Bereichen genutzt werden: die Steuerung von Transaktionen, die Überwachung und die Berechtigungsprüfung.
Explizit nicht benutzt werden soll AOP für die Fehlerbehandlung.
Die Verwendung von AOP für andere Bereiche ist nur in begründeten Ausnahmefällen erlaubt.
4.5.1. AOP für Transaktionssteuerung verwenden
Für die Transaktionssteuerung ist Spring-AOP mit den dafür vorgesehenen Klassen von Spring einzusetzen. Die Verwendung wird im Kapitel Transaktionssteuerung mit JPA beschrieben. Zusammengefasst gilt:
-
Instrumentiert werden alle Schnittstellenmethoden des Anwendungskerns.
-
Für jeden Aufruf des Anwendungskerns wird eine Transaktion gestartet.
-
Falls kein Fehler auftritt, wird die Transaktion abgeschlossen (Commit), sonst zurückgerollt (Rollback).
4.5.2. AOP für Berechtigungsprüfungen verwenden
Die Berechtigungsprüfung wird über Spring AOP mit den vom Baustein „Security“ angebotenen Annotationen umgesetzt (siehe Nutzungsvorgaben Security).
4.5.3. AOP nicht für das Logging von Exceptions verwenden
Sämtliche in einem IT-System geworfenen und nicht behandelten Ausnahmen müssen inklusive ihrer Stacktraces geloggt werden. Geloggt wird dies in den Methoden der Schnittstellen-Beans. Hierfür soll Spring-AOP nicht verwendet werden.
Schnittstellen-Beans transformieren die Geschäftsobjekte des Anwendungskerns in Transportobjekte der Schnittstelle. Die Stack-Traces der Exceptions werden dabei nicht übertragen, da diese internen Informationen dem Aufrufer keinen Mehrwert bieten. Für das Logging des IT-Systems selbst sind sie jedoch wertvoll. Statt AOP ist das im Detailkonzept Komponente Service beschriebene Konstrukt der Exception-Fassade zu verwenden.
4.6. Dependency Injection
Um im Anwendungskern das Single-Responsibility-Prinzip nicht zu verletzten, wird auf das Entwurfsmuster Dependency Injection zurückgegriffen. Dabei werden die Verantwortlichkeiten für den Aufbau des Abhängigkeitsnetzes zwischen den Objekten aus den einzelnen Klassen in eine zentrale Komponente überführt. Anders als bei der herkömmlichen Vorgehensweise in der objektorientierten Programmierung ist bei der Dependency Injection nicht jedes Objekt selbst dafür zuständig, seine Abhängigkeiten (benötigte Objekte und Ressourcen) zu verwalten.
In der folgenden Grafik ist das Entwurfsmuster der Dependency Injection exemplarisch visualisiert.

Die drei verschiedene Verfahren der Dependency Injection sowie die Einsatzszenarien verdeutlicht folgende Übersicht:
| DI-Methode | Einsatzszenario | Bemerkung |
|---|---|---|
Constructor-Injection |
Für alle Beans, welche keine dynamische Anpassung zur Laufzeit benötigen. |
Kann in Produktiv-Code eingesetzt werden und ist der Standard von Spring. |
Field-Injection |
Vermeidung von Boilerplate-Code |
Darf nicht in Produktiv-Code verwendet werden. |
Method-Injection (Setter-Injection) |
Flexibles Austauschen von Beans zur Laufzeit |
Nicht immutable. Sollte nur eingesetzt werden, wenn diese Eigenschaft benötigt wird. |
|
Da die Constructor Injection diverse Vorteile gegenüber den beiden anderen Techniken liefert, empfiehlt die IsyFact die Verwendung von Constructor Injection. |
4.6.1. Constructor Injection
Bei der Constructor Injection werden alle Abhängigkeiten einer Klasse über die Konstruktoren von außen injiziert.
Dadurch werden automatisch auch die benötigten Abhängigkeiten definiert, welche der Erzeuger des Objektes zur Verfügung stellen muss.
Dieses Vorgehen hat den Vorteil, dass alle benötigten Abhängigkeiten in der Initialisierungsphase des Objektes zur Verfügung stehen.
Zusätzlich werden durch dieses Verfahren Überprüfungen auf null und die Behandlung von nicht aufgelösten Abhängigkeiten unnötig, da die Abhängigkeiten vorhanden sein müssen.
Constructor Injector hilft ebenfalls bei dem Identifizieren von zu vielen Abhängigkeiten zu einem Objekt. Wenn ein Konstruktor zu viele Argumente aufweist, kann dies ein Zeichen für eine zu große Verantwortlichkeit des Objektes sein. Ist dies der Fall, sollte an dieser Stelle über ein Refactoring nachgedacht werden.
Ein weiterer Vorteil von Constructor Injection ist, dass die injizierten Abhängigkeiten während der Laufzeit nicht veränderbar sind und so Nebenläufigkeiten und Seiteneffekte vermieden werden (s. Listing 7).
@Component
public class SomeBean {
private final AnotherBean anotherBean;
public SomeBean(AnotherBean anotherBean) {
this.anotherBean = anotherBean;
}
AnotherBean getAnotherBean() {
return anotherBean;
}
}