Detailkonzept Batch
![]() Diese Seite ist ein Teil der IsyFact-Standards.
Alle Inhalte der Seite, insbesondere Texte und Grafiken, sind urheberrechtlich geschützt.
Alle urheberrechtlichen Nutzungs- und Verwertungsrechte liegen beim Bundesverwaltungsamt.
Diese Seite ist ein Teil der IsyFact-Standards.
Alle Inhalte der Seite, insbesondere Texte und Grafiken, sind urheberrechtlich geschützt.
Alle urheberrechtlichen Nutzungs- und Verwertungsrechte liegen beim Bundesverwaltungsamt.
 Die Nutzung ist unter den Lizenzbedingungen der Creative Commons Namensnennung 4.0 International gestattet.
Die Nutzung ist unter den Lizenzbedingungen der Creative Commons Namensnennung 4.0 International gestattet.
Java Bibliothek / IT-System
| Name | Art | Version |
|---|---|---|
|
Bibliothek |
v3.3.x |
1. Einleitung
Ein Batch bzw. die Batchverarbeitung bietet die Möglichkeit, Daten automatisiert und meist sequenziell zu verarbeiten. Er stellt eine Variante zur Dialogverarbeitung dar, bei welcher die Datenverarbeitung von Benutzerinteraktionen gesteuert wird.
Neben einer Liste von Anforderungen für die Umsetzung von Batches, stellt IsyFact den technischen Baustein Batchrahmen zur Verfügung, die in diesem Dokument näher beschrieben werden.
In Kapitel Anforderungen werden die Anforderungen, in Kapitel Ausgrenzungen die Ausgrenzungen definiert. Die Funktionsweise des Batchrahmens und die verschiedenen Startarten sowie die Konfiguration folgt in Kapitel "Der Batchrahmen". Dort werden auch die Transaktionssteuerung und die Restart-Funktionalität beschrieben, die es ermöglicht, abgebrochene Batches fortzusetzen. Die Überwachung mittels JMX ist ebenfalls enthalten. Das Kapitel "Die Ausführungsbeans" beschreibt schließlich, wie die konkrete Batchlogik über Ausführungsbeans angebunden wird.
2. Einführung
2.1. Vorgehen
Der Begriff „Batch“ bedeutet im Kern lediglich „nicht interaktive Stapelverarbeitung“. Wie ein Batch technisch umgesetzt werden soll, hängt davon ab, was konkret unter einem Batch verstanden wird. Im Folgenden wird deshalb zuerst beschrieben, was ein Batch im Sinne der IsyFact ist.
Ein Batch teilt sich auf in einen „Batchrahmen“, die Batchlogik der einzelnen Batch-Anwendungen, sowie die von ihnen aufgerufenen Komponenten des Anwendungskerns. Was darunter verstanden wird, wird in Kapitel Die Aufteilung in Batchrahmen und Batchlogik beschrieben.
2.2. Was ist ein Batch?
Eine Geschäftsanwendung stellt über ihre Komponenten fachliche Operationen bereit. Diese Operationen werden (zum Teil) als Services bereitgestellt. Sie werden aber auch bei der automatisierten Bearbeitung größerer Datenmengen in Batches verwendet. Typischerweise verarbeiten Batches dabei Dateilieferungen oder eine definierte Menge von Datensätzen aus dem Datenbestand. Einige der Operationen von Anwendungskomponenten werden nur für Services, einige nur für Batch-Verarbeitungen, andere für beides verwendet.
2.3. Namenskonvention für eine Batchanwendung
Mit vielen Systemen wird eine eigene Batch-Deploymenteinheit ausgeliefert. Diese wird folgendermaßen benannt.
| Name der Batchanwendung | |
|---|---|
Schema |
|
Beispiele |
|
Variable |
Mögliche Ausprägungen |
|
Der Name einer Anwendung, wie in den vorigen Abschnitten beschrieben. Er setzt sich meistens aus einem Systemkürzel und dem Systemtyp zusammen. |
2.3.1. Die Bestandteile eines Batches und die Zielarchitektur
Ein Batch verwendet für die fachliche Verarbeitungslogik die Operationen der Komponenten der Geschäftsanwendung. Neben der fachlichen Verarbeitungslogik besteht die Anwendungslogik eines Batches aus folgenden Bestandteilen:
-
der technischen Logik, welche spezifisch für genau eine Batch-Implementierung ist: Funktionalität für das Einlesen der für die Verarbeitung benötigten Daten, das Aufrufen der Fachkomponenten etc.
-
querschnittliche Logik, welche für alle Batches gleich ist. Dies ist z. B. die Checkpoint-Restart Logik (siehe Kapitel Checkpoint / Restart Logik).
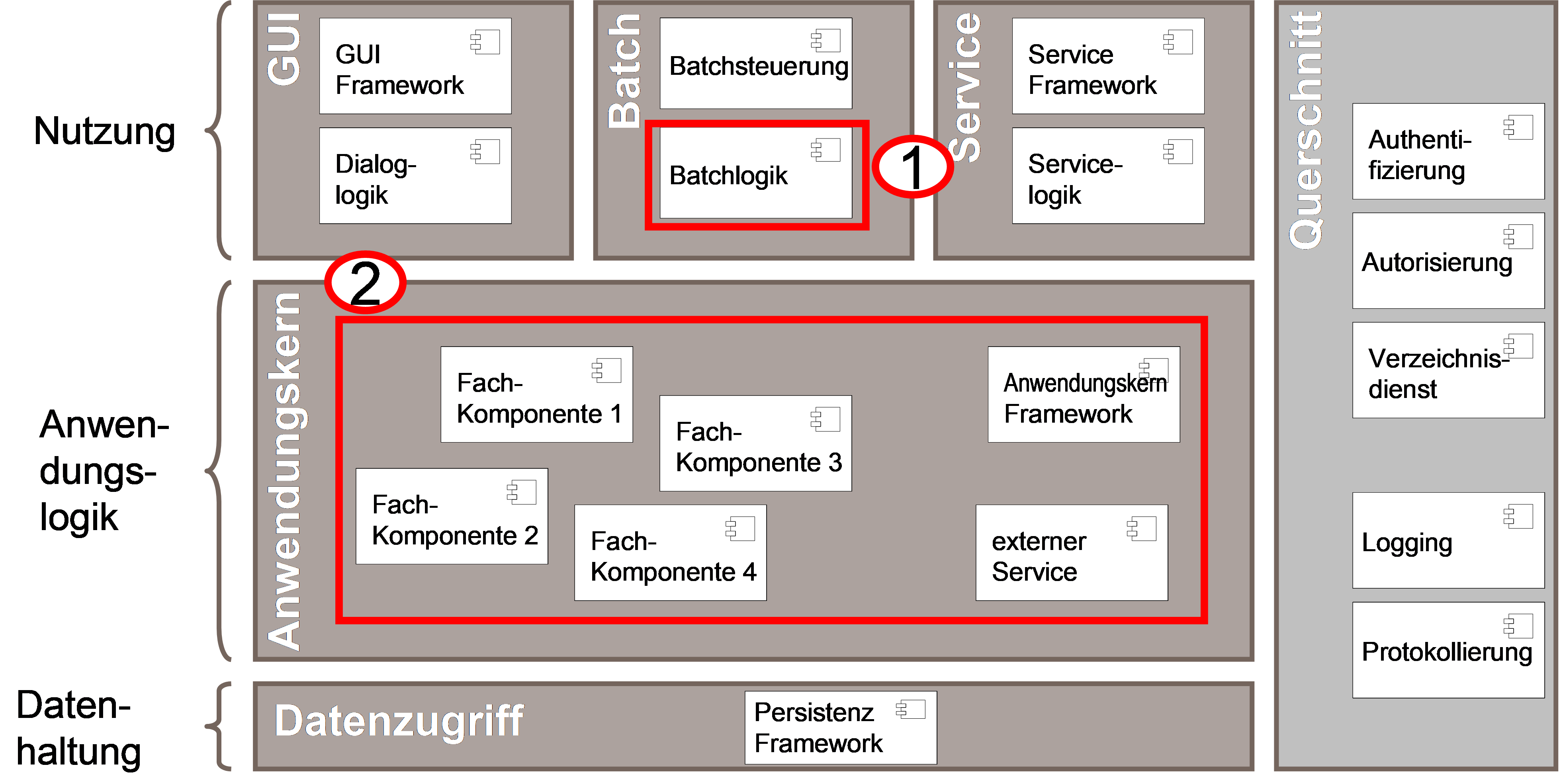
In Abbildung 1 werden diese Bestandteile in der Zielarchitektur hervorgehoben: Die spezifische technische Batchlogik wird in Punkt 1 dargestellt, die fachlichen Operationen der Komponenten finden sich in Punkt 2. Die querschnittliche Logik wird lediglich als Bibliothek eingebunden und ist in der Abbildung nicht dargestellt.
Die Komponente „Batchsteuerung“ der Zielarchitektur bezieht sich auf die Steuerung eines Batch-Netzes (siehe Abbildung 2) und wird über eine betriebliche Batchsteuerung umgesetzt. Sie wird in diesem Dokument nicht betrachtet.
Die Komponente „Batchlogik“ der Zielarchitektur ist eine logische Komponente, welche die technische Logik der Batchimplementierungen der Geschäftsanwendung beinhaltet. Diese Logik ist technisch gesehen keine Komponente, sondern eine Sammlung unabhängiger Klassen in der Batch-Schicht der Geschäftsanwendung. Im Dokument wird unter Batchlogik diese Klassensammlung und keine Komponente verstanden.
2.3.2. Checkpoint / Restart Logik
Da ein Batch in einem Lauf eine große Anzahl an Datensätzen verarbeiten muss, soll seine Verarbeitung nicht in einer Transaktion durchgeführt werden. Ebenso soll nicht jeder Datensatz in einer eigenen Transaktion verarbeitet werden, wie es die Transaktionssteuerung des Anwendungskerns vorsieht. Vielmehr wird ein Batch sein Arbeitspaket in mehreren Paketen, und damit auch Transaktionen, abarbeiten. Bei einem Wiederanlauf nach einem Fehler muss der Batch in der Lage sein, die bis zu seinem letzten Commit verarbeiteten Datensätze zu überlesen und nur die „neuen“ Datensätze zu verarbeiten. Den Commit einer Transaktion bezeichnet man in diesem Fall als Checkpoint. Das Überlesen bereits verarbeiteter Datensätze nennt man Checkpoint / Restart Fähigkeit.
Für die Umsetzung der Checkpoint / Restart Fähigkeit muss der Batch in jeder Transaktion speichern, welche Datensätze bis zum Commit verarbeitet wurden. Üblicherweise geschieht das durch die Ablage der Anzahl verarbeiteter Datensätze bis zum Commit. Abgelegt werden diese Daten in einer Batch-Statustabelle, welche für jeden Batch eine Zeile enthält.
2.3.3. Der Unterschied zwischen Batch-Netz, Batch-Schritt und Batch-Implementierung
Die Verarbeitung von Massendaten durch einen Batch verläuft meist in mehreren Schritten: Die Verarbeitung einer Datei kann beispielsweise aus ihrer Übertragung auf einen internen Server, ihrer nachfolgenden Prüfung und der Verarbeitung ihres Inhalts bestehen. Diese Verarbeitungsschritte (Batch-Schritte) eines Batches bilden ein „Batch-Netz“. Jeder Schritt wird über den Aufruf eines Shell-Skripts gestartet.
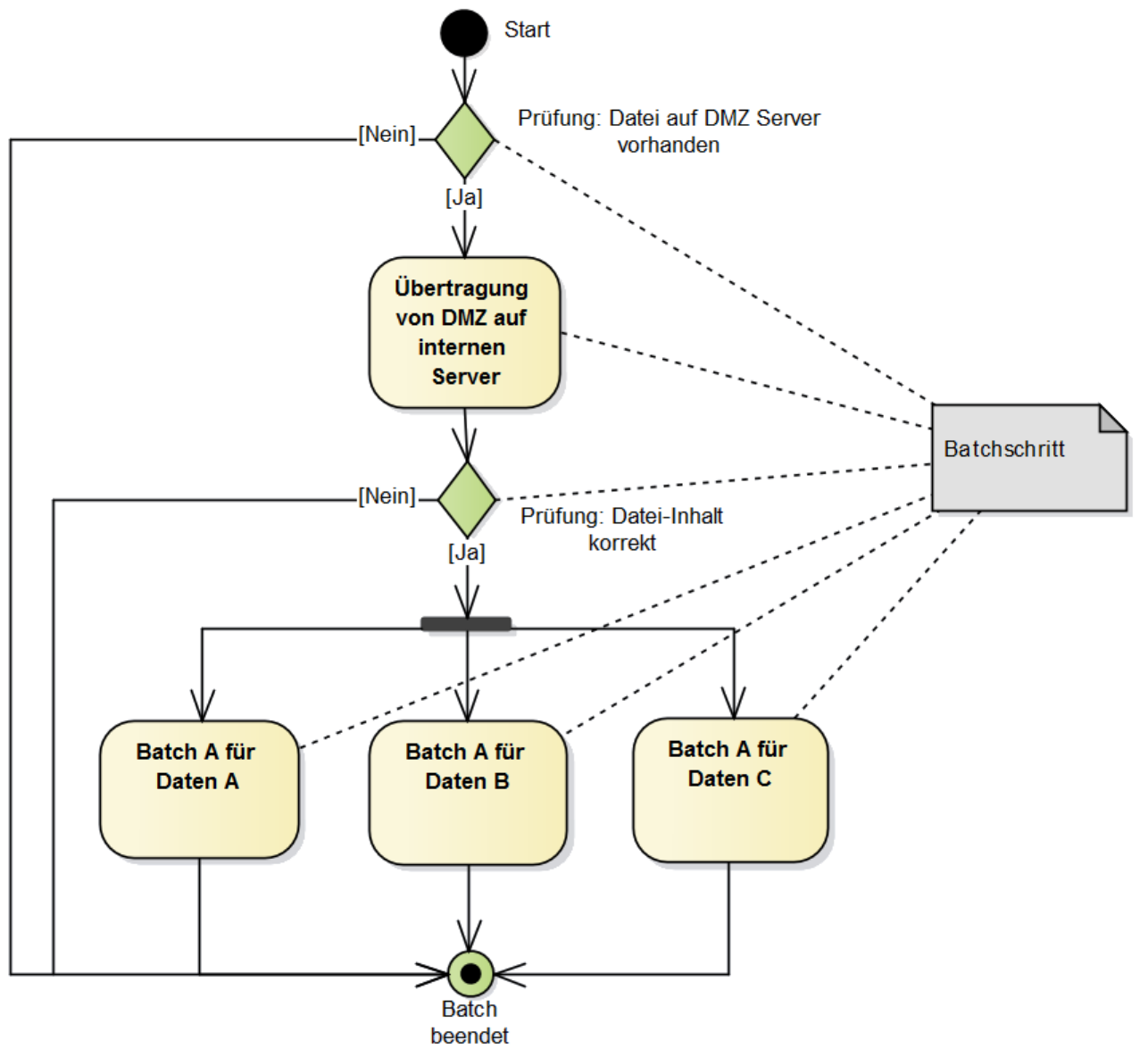
Die meisten Batch-Schritte sind keine Anwendungen: Sie werden komplett über ein Skript umgesetzt. Nur die Schritte, welche die Verarbeitung in der Geschäftsanwendung durchführen, sind Anwendungen und besitzen eine Java-Implementierung (die Batchschritt-Implementierung). In obiger Abbildung wird die Verarbeitung in der Geschäftsanwendung durch drei Batch-Schritte parallel durchgeführt. Alle drei verwenden dieselbe Batchschritt-Implementierung, arbeiten aber auf anderen Daten.
Ein Batch-Netz wird durch einen Job-Scheduler gesteuert. Ein Batch-Schritt ist dabei der Aufruf, welcher vom Scheduler aufgerufen wird. Aufgerufen wird ein Skript mit einer bestimmten Konfiguration. Über dieses Skript wird ggf. eine Geschäftsanwendung mit der übergebenen Konfiguration ausgeführt. Die Konfiguration eines Batchschrittes enthält stets eine Batchschritt-ID, welche den Batchschritt eindeutig identifiziert. Das bedeutet, dass jeder der drei Batchschritte in Abbildung 2 eine eigene Batchschritt-ID erhält, obwohl alle drei Batchschritte die gleiche Batchschritt-Implementierung verwenden. Der Grund ist, dass jeder Batchschritt auf einem anderen Nummernkreis arbeitet und somit die Batchschritte unterscheidbar sein müssen. Diese Unterscheidung erfolgt über die Batchschritt-ID.
Dieses Dokument befasst sich nicht mit Batch-Netzen oder ihrer Steuerung. Es behandelt die Geschäftsanwendung-Batchimplementierungen und ihre Konfigurationen. Der Einfachheit halber wird deshalb ein Geschäftsanwendung-Batchschritt als „Batch“ und eine Batchschritt-ID als „Batch-ID“ bezeichnet.
Wichtig ist jedoch die Unterscheidung zwischen Batch und Batch-Implementierung: Der Batch ist der Aufruf aus der Produktionssteuerung heraus. Über ihn wird die aufzurufende Batch-Implementierung sowie seine Konfiguration (inklusive der Batch-ID) definiert. Die Implementierung ist Java-Code, der von mehreren Batches verwendet werden darf.
2.3.4. Die Aufteilung in Batchrahmen und Batchlogik
Das Einlesen und Verarbeiten von Datensätzen durch den Aufruf fachlicher Komponenten wird in diesem Dokument Batchlogik genannt. Diese ist spezifisch für genau eine Batch-Implementierung.
Neben dieser Logik enthält eine Batch-Implementierung Querschnittsfunktionalität, welche stets gleich ist. Für eine Batch-Implementierung umfasst diese Querschnittsfunktionalität folgende Punkte:
-
Einlesen der Konfiguration des Batches über die Kommandozeile und Konfigurationsdateien
-
Instanziieren der Geschäftsanwendungs-Komponenten in einem Spring-Kontext
-
Initialisieren, Auslesen und Verwalten der Batch-Statustabelle
-
Aufruf des Überlesens von Datensätzen bei einem Restart
-
Steuerung der Transaktionen inklusive Speicherung des Fortschritts in einer Status-Tabelle
-
Bereitstellung von Überwachungsmöglichkeiten
-
Authentifizierung und Autorisierung eines betrieblich konfigurierten Batchbenutzers über den Baustein
isy-security -
Konfiguration, Instanziierung und Aufruf der eigentlichen Batchlogik
Diese Funktionalität wird in einer Batch-Implementierung durch eine querschnittliche Komponente namens Batchrahmen umgesetzt. Diese wird über eine Bibliothek bereitgestellt, welche in jede Geschäftsanwendung eingebunden wird.
2.3.5. Grobe Architektur des Batchrahmens
Für den Batchrahmen wurde folgende grobe Architektur gewählt:
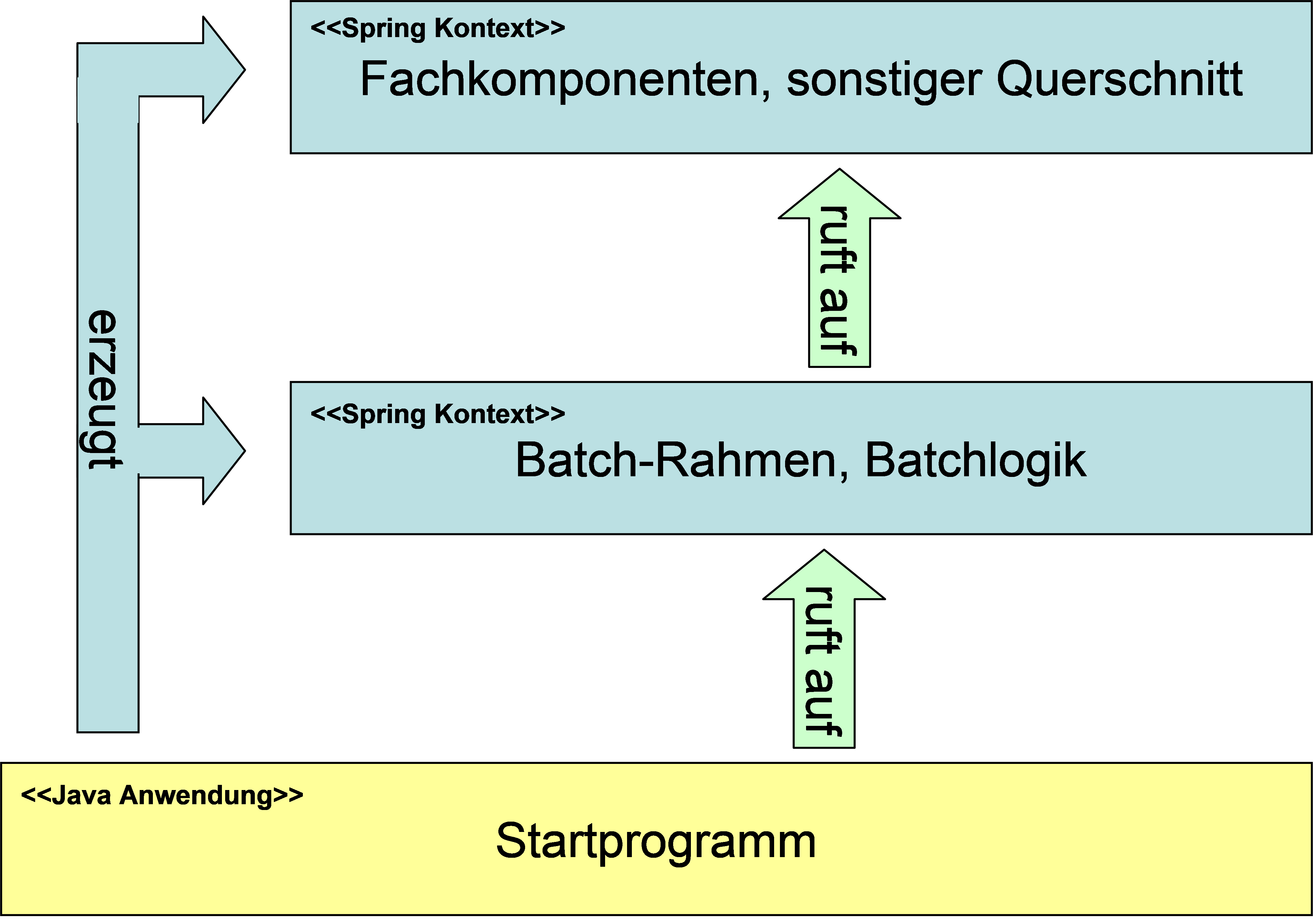
Der Batchrahmen besteht aus einem Startprogramm, welches notwendige Initialisierungen vornimmt, und einer Komponente Batchrahmen. Die Komponente Batchrahmen übernimmt die Steuerung des Batches und den Aufruf der Batchlogik.
Die Komponenten einer Geschäftsanwendung werden für einen Batch, genau wie in der Webanwendung, über das Spring-Framework verwaltet. Damit die Konfigurationen für die Webanwendung und für die Batch-Implementierungen möglichst gleich sind, werden die Komponenten für den Batchrahmen und die Batchlogik in einer separaten Konfigurationsdatei und einem separaten Spring-Kontext abgelegt. Dieser Kontext ist ein Kind-Kontext des eigentlichen Anwendungskontextes und kann alle Beans des Anwendungskontextes verwenden. So kann die Konfiguration der Webanwendung mit minimalen Anpassungen auch für den Batch verwendet werden.
Der Batchrahmen benötigt für die Speicherung des Fortschritts und des Status der Batches eine Datenbankverbindung. In der Datei werden die vom Batchrahmen benötigten Informationen gespeichert, siehe Tabellen des Batchrahmens.
Bei Bedarf können in einem Batch auch weitere Datenbankverbindungen genutzt werden. Die Einbindung weiterer Datenbanken ist in Konzept des Bausteins JPA/Hibernate beschrieben.
2.4. Batches als eigenes IT-System
Batches existieren meistens als weiterer Zugangsweg in der Nutzungsschicht einer bestehenden Geschäftsanwendung (siehe Abbildung 1), da sie auf den Daten des jeweiligen Anwendungssystems operieren.
Es kann allerdings auch Batches geben, die unabhängig von einer bestimmten Geschäftsanwendung sind. Dies kann beispielsweise der Fall sein, wenn ein Import-Batch angelieferte Dateien in verschiedene Geschäftsanwendungen importiert. Wenn Batches nicht eindeutig einem Anwendungssystem zugeordnet werden können, kann man sie auch als eigenständiges IT-System implementieren. Dieses „Batch-System“ kann dann die Service-Schnittstellen anderer Geschäftsanwendungen aufrufen. Insgesamt ist dies jedoch als Sonderfall zu betrachten. In der Regel gehören Batches zu Geschäftsanwendungen, sie enthalten damit den fachlichen Code dieser Anwendung und nutzen diesen nicht über Service-Schnittstellen (siehe Kapitel Das Deployment eines Batches).
In diesem Fall ist das Anwendungssystem architektonisch ein eigenständiges IT-System nach Zielarchitektur, nur ohne Service und GUI Bereiche in der Nutzungsschicht.
Batches die zu einer Geschäftsanwendung gehören sollen jedoch nicht als eigenständiges IT-System umgesetzt werden.
3. Anforderungen
3.1. Anforderungen an den Batchrahmen
Für den Batchrahmen selbst gelten folgende Anforderungen:
-
Er soll den vorhandenen Nutzungsvorgaben und Querschnittskonzepten entsprechen.
-
Die Spring-Konfiguration für den Batch soll der Konfiguration der Webanwendung möglichst ähnlich sein.
-
Er soll möglichst wenige Anforderungen an (bzw. Annahmen in Bezug auf) die Batchlogik stellen.
-
Die Batchlogik soll möglichst einfach implementiert werden können.
-
Die Batchrahmen-Implementierung soll programmtechnisch effizient sein.
3.2. Anforderungen an die Batchimplementierung
Für die umzusetzende Batchlogik gelten folgende Anforderungen:
-
Sie sollen keine Fachlogik enthalten, sondern die Komponenten des Anwendungskerns verwenden. Abweichungen sind nur aus zwingenden Performance-Gründen erlaubt. Dies ist jeweils mit dem technischen Chefarchitekten abzustimmen und im Systementwurf zu dokumentieren. Falls in Ausnahmefällen direkte Datenbankzugriffe notwendig sind, sind alle weiteren Verarbeitungen an die Fach-Komponenten zu delegieren.
-
Die Batchlogik soll die Logging-, Statistik- und Protokollierungs-Aufgaben nach Anforderung des Projekts umsetzen. Diese wird nicht durch den Batchrahmen umgesetzt. Insbesondere die Statistikinformationen sind für Betrieb und Fachbereich wichtige Informationsquellen, um beispielsweise Laufzeitabschätzungen für die Produktion durchführen zu können. In der Statistik sollte immer enthalten sein, wie viele Sätze verarbeitet wurden (erfolgreich und mit Fehlern) und was konkret unter dem Begriff „Satz“ zu verstehen ist. Ist dies in der Statistik nicht vermerkt, wird davon ausgegangen, dass es sich um den Hauptsatz der Geschäftsanwendung handelt. Was der Hauptsatz einer Geschäftsanwendung ist, hängt von der konkreten Anwendung ab.
-
Die Batchlogik soll die Funktionalität des „Überlesens“ von Datensätzen übernehmen. Ob und welche Datensätze zu überlesen sind, teilt der Batchrahmen mit.
-
Die Batchlogik soll dem Batchrahmen hinreichende Informationen übergeben, um den Wiederanlaufpunkt bei einem späteren Restart zu bestimmen.
-
Der Batchrahmen führt in konfigurierbaren Intervallen Commits durch, um das Fortsetzen des Batches nach einem Abbruch zu ermöglichen. Die Batchlogik soll mit solchen periodischen Commits umgehen können.
-
Die Batchlogik sollte – sofern es keine inhaltlichen Abhängigkeiten gibt – mit parallel laufenden Batches umgehen können. Damit ist nicht nur gemeint, dass die gleiche Batchschritt-Implementierung parallel auf z. B. verschiedenen Nummernkreisen arbeiten kann. Vielmehr ist damit gemeint, dass verschiedene Batchschritt-Implementierung parallel ausgeführt werden können. Dazu ist sicherzustellen, dass gemeinsam genutzte Ressourcen nicht unnötig gehalten werden.
-
Bei der Ausgabe von vielen Dateien während eines Batchlaufs sind diese strukturiert in Unterverzeichnissen abzulegen. Es ist eine Datei-Namenskonvention für die Batch-Implementierung festzulegen. Die Unterverzeichnisstruktur und die Anzahl der darin enthaltenen Dateien sollen parametrisierbar sein.
3.3. Anforderungen an die Dokumentation von Batches
Für die Dokumentation von Batches gelten neben der lückenlosen und kurzen Beschreibung der durchgeführten Funktionen noch folgende Anforderungen:
-
Es muss auf lang laufende Batches hingewiesen werden. Dies ist abhängig von der umgesetzten Batchlogik und der erwarteten Anzahl an zu verarbeitenden Datensätzen. Der Betreiber des Batches soll damit schon im Vorfeld längere Batchlaufzeiten einkalkulieren können.
-
Das zu erwartende Laufzeitverhalten bei steigendem Mengengerüst ist anzugeben. Dadurch soll eine Abschätzung geliefert werden, wie sich der Batch skalieren lässt. Analog zum zuvor genannten Punkt soll dies eine Hilfe für den Betreiber zur Kalkulation von Batchlaufzeiten sein.
-
Abhängigkeiten von Batches werden dargestellt.
4. Ausgrenzungen
Der bereitzustellende Batchrahmen soll ein unkompliziertes und einfach zu verwendendes Framework sein. Seine Funktionalitäten sollen lediglich die Verarbeitung, nicht andere betriebliche Aspekte abdecken. Explizit ausgegrenzt werden deshalb folgende Themenbereiche:
Ein explizites Handling von Eingabedateien: Ein möglicherweise erforderliches Dateihandling übernimmt die spezifische Batchlogik. Der Batchrahmen soll kein Wissen darüber besitzen.
Die Terminierung der Verarbeitung: Der Batch stellt keine direkten Schnittstellen bereit, um ihn während der Verarbeitung zu beenden.
Allerdings muss es möglich sein, einen aktiven Lauf mit dem Signal kill -15 definiert zu beenden.
Wie die zugehörige Prozess-ID ermittelt wird, ist in den Betriebshandbüchern für die Prozesse zu definieren.
Es ist auch möglich, mit dem „laufzeit“-Parameter eine maximale Laufzeit anzugeben, um den Batch nach Überschreitung der angegebenen Laufzeit sich selbst definiert beenden zu lassen.
Das Scheduling der Verarbeitung: Das Scheduling wird nicht durch den Batchrahmen, sondern durch die betriebliche Produktionssteuerung durchgeführt.
Das Prüfen von Vorbedingungen: Falls für die Ausführung Vorbedingungen gegeben sein müssen (etwa Dateien in Verzeichnissen vorliegen müssen), so liegt deren Prüfung in der Verantwortung des aufrufenden Skripts.
Das Warten auf Events: Der Batchrahmen arbeitet eine Reihe von Datensätzen ab und beendet sich danach. Er ist kein Serverprozess, welcher auf bestimmte Events (Dateien in Verzeichnissen, Sätze in Datenbank) wartet, diese verarbeitet und daraufhin weiter wartet.
Keine parallele Verarbeitung innerhalb eines Batches: Es ist erlaubt, dass mehrere Java-Prozesse mit der gleichen Batch-Implementierung (jedoch verschiedenen BatchIDs) parallel laufen.
| Siehe Unterschied zwischen Batch-Implementierung und Batch, Kapitel Was ist ein Batch?. Parallel laufende Batches sind vor allem sinnvoll, wenn sie über einem aufgeteilten Datenbestand arbeiten und ein Batch pro Teil verwendet wird. |
Innerhalb einer Verarbeitung wird jedoch stets mit einem Thread gearbeitet. Multithreading innerhalb eines Batches wird nicht unterstützt.
5. Der Batchrahmen
Der Batchrahmen ist das Framework, in welches sich die Logik eines konkreten Batches einfügt. Der Batchrahmen ruft (anhand einer Konfiguration) diese Logik auf. Da eine Batch-Anwendung über Spring verwaltet wird, wird die Batchlogik als Spring-Bean konfiguriert, als sogenannte Ausführungsbean. Diese Bean wiederum ruft die Geschäftsanwendungs-Komponenten auf, welche die fachliche Logik enthalten.
Für eine Beispielanwendung zeigt Abbildung 4 eine Auswahl der vorhandenen Beans. Wichtig ist ihre Verteilung auf zwei Anwendungskontexte: Der Batchrahmen und die Ausführungsbeans werden in einem eigenen Kontext konfiguriert. So müssen wenige Anpassungen vorgenommen werden, um aus der Anwendungskontext-Konfiguration als Webanwendung die Konfiguration für den Anwendungskontext im Batchbetrieb zu erhalten.
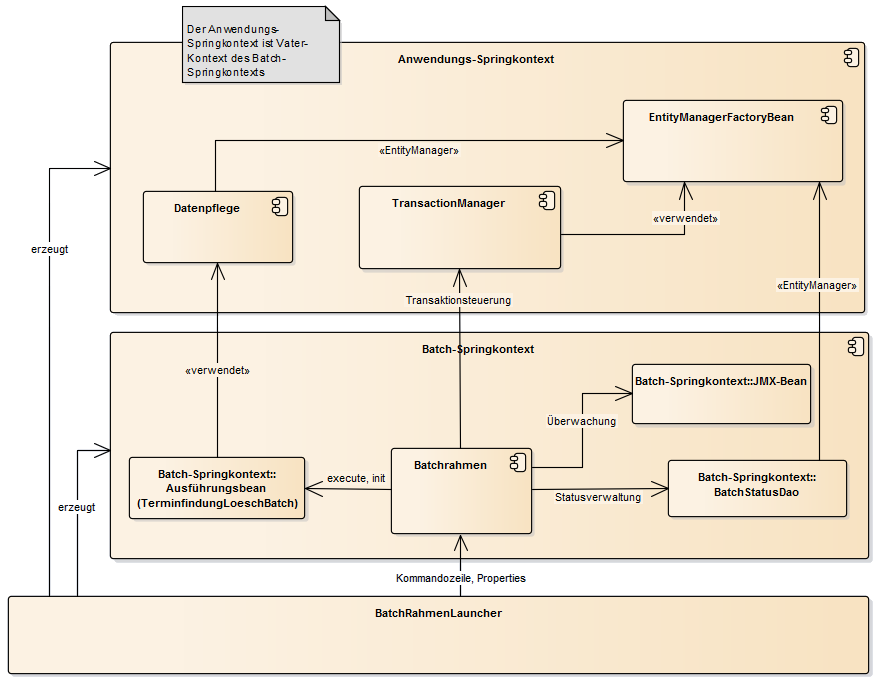
Für neue Batch-Implementierungen einer Geschäftsanwendung müssen ggf. Geschäftsanwendungs-Komponenten angepasst, Ausführungsbeans erstellt und diese im Batch-Springkontext konfiguriert werden. Die folgenden Abschnitte liefern die zur Entwicklung dieser Beans und zur Verwendung des Batchrahmens notwendigen Informationen. Im Einzelnen werden die folgenden Aspekte beschrieben:
-
Die Konfigurationsmöglichkeiten des Batchrahmens und der Ausführungsbeans.
-
Das Transaktions-Handling, die Restart-Funktionalität und die Status-Tabellen des Batchrahmens.
-
Die im Batchrahmen enthaltenen Überwachungsmöglichkeiten.
-
Die Authentifizierung und Autorisierung einer ClientRegistration.
-
Das Deployment der Batches einer Geschäftsanwendung.
5.1. Die Status und Startarten des Batchrahmens
Im Folgenden werden die Status beschrieben, in welchen sich ein Batch laut den Batchrahmen-Tabellen befinden kann. Zusätzlich werden, basierend auf diesen Status, die Möglichkeiten zum Starten eines Batchlaufs beschrieben. Diese Informationen werden hier vorgestellt und in den folgenden Abschnitten im Zusammenhang mit den Parametern und Tabellen des Batchrahmens verwendet.
Ein Batch befindet sich in einem von vier Status, welche in den Tabellen des Batchrahmens gespeichert werden:
-
neu: Status eines noch nicht gelaufenen Batches. Existiert kein Eintrag in der Datenbank, dann wird dieser Status implizit verwendet. Bricht ein noch nicht gelaufener Batch noch in der Initialisierungsphase ab, dann wird dieser Status explizit in die Datenbank geschrieben. -
laeuft: Der Batch wurde gestartet und läuft aktuell. -
abgebrochen: Der Batch ist-
mit einem Fehler
-
durch das Signal
kill -15 -
durch die Überschreitung der konfigurierten maximalen Laufzeit
-
oder weil die Grenze der zu verarbeitenden Datensätze erreicht wurde abgebrochen
-
-
beendet: Der Batch ist erfolgreich beendet worden.
Je nachdem, in welchem Zustand sich der Batch laut den Tabellen gerade befindet, lässt er sich nur mit bestimmten Startarten starten. Welche Startart verwendet wird, muss über Parameter definiert werden. Folgende Startarten sind möglich:
-
Batch im Status
neuoderbeendet:start: Der Batch startet und bearbeitet die Eingabedaten ab dem ersten Datensatz. -
Batch im Status
laeuft:ignoriereLauf: Der Batch wird gestartet, als wäre er erfolgreich beendet worden.restart: Der Batch startet neu und überliest alle bereits verarbeiteten Sätze. -
Batch im Status
abgebrochen:restart: Der Batch startet neu und überliest alle bereits verarbeiteten Sätze.ignoriereRestart: Der Batch startet neu und beginnt die Verarbeitung mit dem ersten Datensatz.
5.2. Die Konfiguration des Batchrahmens
5.2.1. Konfigurationsdatei und Kommandozeilen-Parameter
Die Konfiguration des Batchrahmens wird über zwei Arten durchgeführt: über
-
Kommandozeilen-Parameter und
-
Konfigurationsdateien.
Alle Konfigurationsparameter werden an die Ausführungsbean übergeben und können genutzt werden, um sie zu konfigurieren.
| Bei der Nutzung von Dateien, egal ob für Kommandozeilenparameter oder für Konfigurationsdateien, müssen die Dateien mit absoluten Pfaden angegeben werden. |
5.2.2. Kommandozeilen-Parameter
5.2.2.1. Namenskonvention
| Batches: Konfigurationsparameter Kommandozeile | |
|---|---|
Schema |
|
Beispiele |
|
5.2.2.2. Standard-Parameter
Vom Batchrahmen werden folgende Kommandozeilen-Parameter interpretiert:
| Parameter | Beschreibung |
|---|---|
|
Name einer Property-Datei mit Konfigurationseinträgen. Der Dateiname wird relativ zum Klassenpfad interpretiert. |
|
Starten des Batches und Verarbeitung der Daten ab dem ersten Datensatz. |
|
Starten des Batches nach einem Fehler-Abbruch: Überlesen der bereits verarbeiteten Datensätze. |
|
Auch bei Fehlern Start akzeptieren, nicht auf Restart beharren. |
|
Auch bei Status "laeuft" Start akzeptieren. |
|
Startet den Batch im Testmodus. Dieser arbeitet analog zum normalen Wirkbetrieb, jedoch werden keine Änderungen an Datenbeständen vom Anwendungssystem oder Nachbarsystemen durchgeführt. Ein detailliertes Konzept ist in Kapitel Testmodus beschrieben. |
|
Gibt eine maximale Laufzeit in Minuten an. Wird die angegebene Zeit überschritten, wird der aktuelle Datensatz zu Ende bearbeitet. Der Batch bricht vor der Verarbeitung des nächsten Datensatzes mit einem dedizierten Return-Code ab. |
5.2.3. Konfigurationsdatei(en)
Konfigurationsdateien sind syntaktisch property-Dateien. Die Konfigurationsdatei mit den unten aufgelisteten Parametern wird als statische Konfiguration im Verzeichnis`resources` abgelegt und kann daher nicht vom Betrieb angepasst werden.
Betriebliche Konfigurationen müssen wie in Kapitel Betriebliche Konfiguration der Ausführungsbean beschriebenen umgesetzt werden.
5.2.3.1. Namenskonvention
| Batches: Benennung Konfigurationsdateien (unter resources/resources/batch) | |
|---|---|
Schemata |
|
Beispiele |
|
| Batches: Konfigurationsparameter Konfigurationsdatei | |
|---|---|
Schema |
|
Beispiele |
|
5.2.3.2. Standard-Konfigurationsparameter
Die nachfolgenden Parameter sind in der Batchkomponente als Standard definiert und werden der Konfiguration in der Property-Datei hinzugefügt.
Aus der Property-Datei werden durch den Batchrahmen folgende Properties gelesen:
| Property | Beschreibung |
|---|---|
|
Name der Batchrahmen-Bean |
|
Vollqualifizierte Namen der Spring-Konfigurationsklassen der Geschäftsanwendung |
|
Vollqualifizierte Namen der Spring-Konfigurationsklassen des Batchrahmens |
|
Anzahl Satz-Verarbeitungen pro Commit |
|
Anzahl Satz-Verarbeitungen bis zum Löschen des Hibernate session cache. Dies dient Perfomancegründen und der Vermeidung von out of memory Fehlern. |
|
Name der Ausführungsbean für die Batchlogik |
|
ID des Batches (ID des Batch-Status-Datensatzes) |
|
Name des Batches in der Batch-Statustabelle |
|
Falls nicht die ganze Datei verarbeitet werden soll, sondern nur eine gewisse Anzahl an Datensätzen. |
|
Pfad zur XML-Ergebnisdatei des Batchrahmens (siehe Kapitel Rückgabewerte des Batchrahmens) |
5.2.4. Betriebliche Konfiguration der Ausführungsbean
Sämtliche obigen Parameter müssen vom Betrieb nicht angepasst werden. Falls im Ausnahmefall die Batch-ID angepasst werden muss, kann dies über den Kommandozeilen-Parameter –BatchId <BatchId> geschehen.
Falls für die Ausführungsbean eines Batches Konfigurationen notwendig sind, welche durch den Betrieb gepflegt werden müssen, so ist dies auf eine von zwei Arten umzusetzen:
-
Die Konfigurationen können der betrieblichen Konfiguration der Geschäftsanwendung hinzugefügt werden.
Konfiguration der Geschäftsanwendung: Die im Ordner configliegenden, durch den Betrieb pflegbaren Konfigurationsdateien.Die Ausführungsbean kann dann die Geschäftsanwendungs-Konfigurationsbean per Dependency Injection erhalten und sich darüber konfigurieren.
Diese Möglichkeit ist zu verwenden, falls nur ein Batch für die Geschäftsanwendung umgesetzt wird. Falls mehrere Batches umgesetzt werden, ist sie dann zu verwenden, wenn sich die Konfigurationen für die einzelnen Batches nicht widersprechen (also für verschiedene Batches verschiedene Werte für die gleiche Property erwartet werden).
-
Die Konfiguration kann in einer neuen Datei abgelegt werden, welche nur für diesen Batch verwendet wird. Diese Datei kann als Properties-Bean geladen und der Ausführer-Bean per Dependency Injection übergeben werden.
Diese Möglichkeit ist zu verwenden, falls für verschiedene Batches verschiedene Konfigurationsdateien benötigt werden.
5.2.5. Die Konfiguration der Spring-Kontexte
Wie in Kapitel Grobe Architektur des Batchrahmens beschrieben, werden für einen Batch zwei Spring-Kontexte erzeugt:
-
Ein Kontext mit den Beans der eigentlichen Geschäftsanwendung.
-
Ein Kontext mit der Batchrahmen-Bean, der Batchrahmen JMX-Bean sowie den Ausführungsbeans für die Batches der Geschäftsanwendung.
Für den Kontext der eigentlichen Geschäftsanwendung können die Spring-Konfigurationsdateien übernommen werden. In ihnen müssen folgende Anpassungen vorgenommen werden:
-
Beans, die für die Batch-Verarbeitung nicht benötigt werden, sollten entfernt werden (Service-Beans, GUI-Beans).
-
Damit die Entity-Klassen des Batchrahmens gefunden werden können, muss in der Spring-Konfiguration der Batches ein Entity-Scan hinzugefügt werden:
@EntityScan("de.bund.bva.isyfact.batchrahmen.persistence.rahmen") -
Das Nachrichten-Resource-Bundle für den Batch muss der
messageSource-Bean hinzugefügt werden.
Um Beans gezielt aus der Spring-Konfiguration der Anwendung für die Ausführung eines Batches auszuschließen, kann die
Annotation @ExludeFromBatchContext verwendet werden.
Damit werden mit @Component annotierte Klassen oder @Bean-Methoden in @Configuration-Klassen annotiert (Listing 1).
@Component
@ExcludeFromBatchContext
public class BeispielServiceExceptionFassade { ...
@Configuration
public class ServiceConfig {
@Bean
@ExcludeFromBatchContext
public BeispielServiceExceptionFassade() { ...Die Spring-Konfiguration für den Kontext des Batchrahmens muss neu erstellt werden.
Hierfür werden gesonderte @Configuration-Klassen erstellt.
|
Da Für Anwendungen, welche die Für Anwendungen, welche die Im Nachfolgenden wird die Tabelle |
6. Tabellen des Batchrahmens
Der Batchrahmen benötigt für seine Checkpoint / Restart Funktionalität die Möglichkeit, bei jedem Commit den aktuellen Stand des Batches in einer Tabelle zu speichern.
Dies wird über die Tabelle BATCH_STATUS umgesetzt.
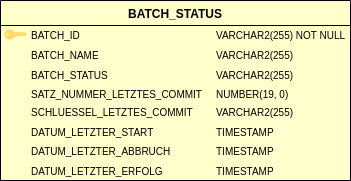
Die Tabelle BATCH_STATUS enthält für jeden Batch eine Zeile.
Ein Batch ist nicht gleichzusetzen mit der Batch-Ausführungsbean.
Für eine Bean darf es mehrere Batches geben, welche die Bean für die Ausführung jeweils anders konfigurieren.
Für einen Batch werden folgende Informationen verwendet:
| Spalte | Beschreibung |
|---|---|
|
Der Schlüssel für den Batch. Die ID sollte aus einem gemeinsamen Präfix für die Geschäftsanwendung, gefolgt von einem Suffix für den konkreten Batch, bestehen. |
|
Ein kurzer informativer Name des Batches. |
|
Einer der folgenden Werte: |
|
Die Anzahl an Sätzen, welche beim letzten Commit verarbeitet worden sind. Dies wird für die Umsetzung der Restart-Funktionalität verwendet. |
|
Der Datenbank-Schlüssel des Datensatzes, der als letztes vor dem Commit bearbeitet wurde. Dies wird für die Umsetzung der Restart-Funktionalität verwendet. Falls der Schlüssel ein zusammengesetzter Schlüssel ist, müssen sämtliche Schlüsselteile (durch Trennzeichen getrennt) in dieses Feld geschrieben werden. |
|
Das Datum des Starts des aktuellen Batch-Laufs (falls der Status "laeuft" ist) bzw. des letzten Laufes. |
|
Das Datum des letzten fehlerhaften Abbruchs des Batches. |
|
Das Datum des letzten erfolgreichen Abschlusses des Batches. |
Die Tabelle liegt im Datenbankschema der eigenen Geschäftsanwendung. Es darf keine übergreifenden Tabellen oder ein übergreifendes Datenbankschema für alle Batches gemäß IsyFact-Architektur geben.
6.1. Verwaltung der Tabelle
Die Tabelle dient nicht der Steuerung des Batches über den Betrieb, sondern nur der Ablage von Informationen zwischen zwei Batch-Läufen. Die Befüllung der Tabelle wird deshalb komplett über den Batchrahmen durchgeführt: Es müssen keine Datensätze manuell befüllt werden: Ist ein Datensatz für einen Batch noch nicht vorhanden, wird er angelegt.
Üblicherweise ist das Locking-Verhalten in Geschäftsanwendungen optimistisch: Datensätze werden nicht explizit gelockt.
Stattdessen wird über Versions-Attribute zum Commit-Zeitpunkt geprüft, ob der Datensatz innerhalb der Transaktion verändert wurde.
Für die Tabelle des Batchrahmens wird nicht optimistisch, sondern pessimistisch gelockt.
Zusätzlich wird als Hibernate Locking-Strategie LOCK_NOWAIT verwendet: Falls auf einen Datensatz zugegriffen wird, welcher gerade gelockt ist, wird nicht bis zur Freigabe gewartet, sondern eine Exception geworfen.
Die parallele Ausführung zweier Batches mit gleicher Batch-ID ist nicht erlaubt und soll zum Fehler führen.
6.2. Die Transaktionssteuerung
In der Property-Datei des Batchrahmens wird die Commit-Rate für den Batch über eine Property konfiguriert. Die Transaktionssteuerung für einen Batch arbeitet daraufhin folgendermaßen:
-
Die Klasse
BatchLauncherliest die Kommandozeile ein, interpretiert die Parameter und erzeugt alle notwendigen Spring-Kontexte. Dies geschieht außerhalb einer Transaktion. Danach gibt die Klasse die Kontrolle an die Batchrahmen-Bean weiter. -
Die Batchrahmen-Bean startet eine erste Transaktion. Sie aktualisiert die Batchrahmen-Tabellen und initialisiert die Ausführungsbean in dieser Transaktion. Die Ausführungsbean führt im Rahmen dieser Transaktion das „Vorlesen“ bis zum letzten Checkpoint sowie ggf. nötige Initialisierungen durch. Die Transaktion wird beendet. Danach beginnt die Satz-Verarbeitung.
-
Für die Satz-Verarbeitung wird eine neue Transaktion gestartet. Die einzelnen Datensätze werden verarbeitet. Bei Erreichung eines Checkpoints wird die Status-Tabelle aktualisiert, die Transaktion abgeschlossen (Commit) und eine neue gestartet.
-
Sobald der letzte Datensatz verarbeitet wurde, wird in einer letzten Transaktion die Status-Tabelle aktualisiert, auf der Ausführungsbean eine Shutdown-Methode aufgerufen und die Transaktion abgeschlossen.
Das Verhalten in Fehlerfällen ist zu jedem Zeitpunkt während der Verarbeitung gleich: Der Fehler wird geloggt und die Transaktion zurückgerollt.
Danach wird versucht, eine neue Transaktion zu starten, um die Status-Tabelle zu aktualisieren: Der Status wird auf abgebrochen gesetzt und die Spalte DatumLetzterAbbruch auf den aktuellen Zeitpunkt.
Daraufhin wird versucht, diese Transaktion abzuschließen.
Schlägt diese Transaktion fehl, kann der Batchrahmen den Abbruch nicht persistent speichern.
Der nächste Lauf muss dann mit dem Parameter -ignoriereLauf gestartet werden.
|
6.3. Die Restart-Funktionalität
Falls ein Batch durch einen Fehler oder durch das Erreichen der Anzahl zu verarbeitender Datensätze abgebrochen ist, muss ein Restart für ihn durchgeführt werden.
In diesem Fall müssen alle bereits verarbeiteten Datensätze übersprungen werden.
Ebenso wird die Wiederanlauffähigkeit nach manuellem Terminieren durch das Signal kill -15 sichergestellt.
6.3.1. Die Konfiguration im Restart-Fall
Im Restart-Fall wird nicht überprüft, dass die übergebenen Parameter denen entsprechen, die im ursprünglichen Lauf übergeben wurden. Es muss daher bei einem Restart manuell darauf geachtet werden, dass die gleichen Parameter übergeben werden.
6.3.2. Beenden eines Laufs mit kill -15 und Wiederanlauf
Durch Senden des Signals kill -15 kann ein aktiver Batchlauf beendet werden.
Beim Empfang des Signals wird der aktuelle Datensatz zu Ende bearbeitet und der Batch terminiert im wohldefinierten Zustand.
In der Statustabelle ist dann der Status „abgebrochen“ vermerkt und der Batchlauf kann mit dem Parameter „-restart“ wieder aufgesetzt werden.
6.3.3. Wiederanlauf nach Abbruch durch die Überschreitung der maximalen Laufzeit
Falls der Batch mit dem „laufzeit“-Parameter gestartet wurde, wird nach Überschreitung der angegebenen maximalen Laufzeit der aktuelle Datensatz zu Ende bearbeitet und der Batch terminiert im wohldefinierten Zustand. In der Statustabelle ist dann der Status „abgebrochen“ vermerkt und der Batchlauf kann mit dem Parameter „-restart“ wieder aufgesetzt werden.
6.3.4. Wiederanlauf nach Abbruch durch kill -9
Durch Senden des Signals kill -9 wird der aktive Batchprozess von Betriebssystemseite beendet.
Dabei wird der Java-Prozess direkt entfernt ohne die Möglichkeit, den Batchrahmen definiert zu terminieren.
Dies ist daher nur in Ausnahmesituationen vom Betrieb durchzuführen.
Da der Batchrahmen in dieser Situation kein Status-Update mehr schreiben kann, befindet sich der Eintrag „läuft“ in der Statustabelle.
Ein Wiederanlauf in dieser Situation ist mit dem Parameter „-restart“ möglich.
6.3.5. Das Vorlesen durch die Ausführungsbean
Um den Batch nach einem Fehler zum nächsten zu bearbeiteten Datensatz „vorlesen“ zu lassen, muss dieser Datensatz identifiziert werden. Dies geschieht zum einen durch den Batchrahmen selbst, welcher die Anzahl der bereits verarbeiteten Datensätze speichert. Bei auf Datenbank-Queries basierenden Batches kann diese Anzahl jedoch ggf. nicht verwendet werden, da sie sich im Laufe der Zeit ändert. Hier ist es notwendig, die zu verarbeitenden Sätze nach ihrem Schlüssel zu sortieren und den als letztes bearbeiteten Schlüssel zu speichern.
Die Batchrahmen Status-Tabelle enthält deshalb zwei Felder: Ein Feld für die Anzahl verarbeiteter Sätze und ein Feld für den Schlüssel des letzten verarbeiteten Datensatzes. Dieser Schlüssel wird von der Ausführungsbean nach der Verarbeitung eines Satzes zurückgegeben.
Bei einem Restart wird der Ausführungsbean in der Initialisierungsmethode übermittelt, ob es sich um einen Restart handelt und welche Werte für den Schlüssel und die Satznummer in der Datenbank stehen. Der Bean ist es überlassen, das Vorlesen effizient durchzuführen (etwa durch die Aufnahme des Schlüssels in das Selektionskriterium einer Query).
6.4. Die Überwachungs-Funktionalität
Die Verarbeitung eines Batches soll überwacht und nachverfolgt werden können. Für die Nachverfolgung können durch die Verarbeitungsbean zu verschiedenen Zeitpunkten Log-, Statistik- oder Protokoll-Einträge erstellt werden:
-
Zu Beginn des Batches, während der Initialisierung der Ausführungsbean.
-
Nach dem Schreiben jedes Checkpoints.
-
Bei der erfolgreichen Beendigung des Batches.
Jeder Log-Eintrag eines Batches, insbesondere die Aufrufe der Fachkomponenten, enthält pro Satz eine eindeutige Korrelations-ID. Damit können Log-Einträge nicht nur einem Batchlauf, sondern den einzelnen Sätzen eindeutig zugeordnet werden.
Für die Überwachung wird durch den Batchrahmen eine JMX-Bean bereitgestellt. Über folgende Konfiguration wird ein JMX Agent erzeugt, welcher die Bean nach außen zugreifbar macht:
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port=<PortNummer>
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=trueÜber die Java Management Console kann man danach auf die Daten zugreifen.
Bereitgestellt werden folgende Informationen:
| Property | Beschreibung |
|---|---|
|
Die Gesamtanzahl der zu bearbeitenden Sätze. Falls diese nicht bekannt ist: -1 |
|
Die Anzahl bereits verarbeiteter Sätze. |
|
Schlüssel des letzten verarbeiteten Satzes. |
|
Zeitraum in Millisekunden, der bereits für den aktuellen Satz benötigt wurde. |
|
Die ID des aktuellen Batches |
|
Name des aktuellen Batches. |
Zur Erhöhung der Sicherheit in der Betriebsumgebung muss eine Absicherung der RMI-Schnittstelle für JMX per Benutzername und Passwort erfolgen (siehe JVM-Parameter oben). Hierzu sind die JMX-Benutzer und Passwörter entweder direkt in der Datei
|
zu konfigurieren, oder der Ort dieser Datei ist über den JVM-Parameter
|
anzugeben.
Die Datei benötigt einen Eintrag für die Rolle controlRole oder für eine beliebige Rolle, für welche in
Datei JRE_HOME/lib/management/jmxremote.access readwrite-Zugriff erlaubt ist.
6.5. Authentifizierung und Autorisierung
Ein Batch wird innerhalb der Plattform gestartet. Dazu verwendet der Batch die Benutzerkennung eines technischen Benutzers „internes System“, die in seiner Startkonfiguration (als Konfigurationsdatei) hinterlegt und im Benutzerverzeichnis vorhanden ist.
Der Batchrahmen verwendet den Baustein isy-security, um den in der Batch-Konfiguration via oauth2ClientRegistrationId definierten Benutzer über einen der Authentifizierungswege Client Credential oder Ressource Owner Password Credential (deprecated) zu authentifizieren.
Im Zuge des Batchlaufs können nun über den Baustein isy-security Berechtigungsprüfungen (z.B. im Anwendungskern) stattfinden.
Nach der initialen Authentifizierung eines Benutzers führt der Batch vor jedem Verarbeitungsschritt eine Prüfung durch, ob das Authentifizierungstoken erneuert werden muss.
Eine erneute Authentifizierung wird dann vorgenommen, wenn das Token als abgelaufen gilt.
Ein Token gilt als abgelaufen, wenn es weniger als die via oauth2MinimumTokenValidity angegebenen Sekunden vor dem Ablauf steht oder im Token kein Wert für den Ablaufzeitpunkt angegeben ist.
Folgende Informationen zum Benutzer sind anzugeben
| Property | Default | Beschreibung | ||
|---|---|---|---|---|
|
null |
Die ID der OAuth 2.0 Client Registration aus |
||
|
60 |
Die Zeit in Sekunden, die ein Token mindestens weiterhin gültig sein muss, um nicht erneuert zu werden.
Steht ein Token weniger als die über die Property angegebenen Sekunden vor dem Ablauf, so wird eine erneute Authentifizierung vorgenommen.
|
In der Regel wird der Benutzer aus der betrieblichen Konfiguration der Anwendung oder alternativ aus den Aufrufparametern beim Batchstart gelesen.
In Ausnahmefällen ist es auch möglich, einen Batch zu implementieren, der ohne Benutzer laufen soll. Dies ist nur möglich, wenn bei Aufrufen des Anwendungskerns keine Autorisierungsprüfungen stattfinden und auch keine Nachbarsystemschnittstellen aufgerufen werden.
Enthält eine Anwendung mehrere Batches, so enthält sie auch mehrere BatchKonfigurationen und kann jeden Batch mit einer eigenen oauth2ClientRegistrationId und oauth2MinimumTokenValidity ausstatten.
6.6. Das Deployment eines Batches
Die Batches werden nicht einzeln deployt. Stattdessen wird ein Paket angeboten, welches sämtliche Batches der Geschäftsanwendung enthält.
Das erstellte Paket enthält den Code des Batchrahmens sowie den Code der eigentlichen Geschäftsanwendung inklusive der Batch-Ausführungsklassen und der benötigten nicht-betrieblichen Batch-Konfigurationsdateien. Für jeden Batch wird ein Shellskript zum Start bereitgestellt.
Für die Shellskripte existieren keine Vorgaben.
Falls vor der Ausführung des Batches Vorbedingungen gelten müssen (etwa Dateien in Verzeichnissen vorliegen sollen), so können sie in diesen Skripten geprüft werden.
Beispiele für Aufruf-Skripte von Batches befinden sich in der Bibliothek isy-batchrahmen, im Verzeichnis src/main/skripte/bin
Eine sinnvolle Aufteilung bei den Shellskripten ist es, ein technisches Startskript zu erstellen, was von den eigentlichen Batch-Shellskripten zum Aufruf genutzt wird.
Beispiel für ein solches Startskript befinden sich in der Bibliothek isy-batchrahmen, in der Datei src/main/skripte/bin/batch-ausfuehren.sh
Dieses Startskript soll in der Batch-Anwendung unter <batch-projekt>/src/main/resources/bin übernommen und mit der richtigen Java-Version versehen werden.
Ein beispielhaftes Shellskript zum Aufruf eines Batches kann dieses Skript dann nutzen und folgendermaßen aussehen:
#!/bin/bash
#
# Parameter für den Erinnerung-Batch
#
# -Testmodus <true|false> Flag ob nur simuliert wird oder nicht (optionaler Parameter)
#
BATCHDIR=`dirname $0`
$BATCHDIR/batch-ausfuehren.sh -start -cfg /resources/batch/batch-erinnerung-config.properties -Batchrahmen.Ergebnisdatei /tmp/erinnerung_out.xml $1 $2Bei der betrieblichen Konfiguration wird nicht zwischen dem Deployment als Web-Anwendung und dem Deployment als Batch unterschieden: Es werden jeweils dieselben betrieblichen Konfigurationsdateien verwendet. Damit der Betrieb Anpassungen dieser Dateien nicht zweimal durchführen muss, wird die betriebliche Konfiguration mit der Web-Anwendung deployt. Vor dem Deployment des Batch-Pakets muss die Webanwendung deployt sein. Falls der Batch nicht auf dem Server der Webanwendung läuft, muss die Konfigurationsdatei der Webanwendung vor der Installation des Batches auch auf diesem Server verfügbar gemacht (z.B. gemountet oder kopiert) werden. Beim Deployment des Batch-Pakets werden über symbolische Links diese betriebliche Konfigurationsdatei referenziert.
6.7. Rückgabewerte des Batchrahmens
Der Batchrahmen endet mit einem Return-Code und erzeugt optional zusätzlich noch ein ausführliches Verarbeitungsergebnis in Form einer Ergebnisdatei im XML-Format. Die Ergebnisdatei ist eine fachliche Datei, sie enthält keine betrieblichen Informationen. Alle betrieblichen Informationen über Ausführung des Batches werden in die Logdatei geschrieben, sodass der Betrieb nur diese Datei betrachten muss. Es gibt keine weiteren betriebsrelevanten Dateien neben der Logdatei.
Der Pfad der Ergebnisdatei wird über einen Konfigurationsparameter des Batches festgelegt (siehe Kapitel Konfigurationsdatei und Kommandozeilen-Parameter). Ist dieser Parameter nicht vorhanden, so wird auch keine Ergebnisdatei geschrieben. Die Ergebnisdatei hat den folgenden Aufbau:
| XML-Pfad | Attribut | Typ | Bedeutung |
|---|---|---|---|
|
Root-Tag des Batch-Ergebnisses |
||
|
|
Text |
Datum des Starts des Batchlaufs |
|
|
Text |
Uhrzeit des Starts des Batchlaufs |
|
|
Text |
Die Batch-ID des Batchlaufs |
|
|
Text |
Die Parameter des Batchlaufs |
|
Liste von Meldungen (Fehler, Warnungen oder Informationen) |
||
|
|
Text |
ID des Eintrags (z.B. Fehlernummer) |
|
|
Text |
Typ des Eintrags: F, W, I |
|
|
Text |
Text des Eintrags, z.B. Fehlertext |
|
|
Text |
Der fachliche Schlüssel des Hauptsatzes, dessen Verarbeitung diese Meldung verursacht hat. Es ist zu beachten, dass ein technischer Schlüssel an dieser Stelle nicht ausreichend ist, da der Fachbereich und der Betrieb mit diesem technischen Schlüssel nichts anfangen können. Falls es nicht möglich ist den fachlichen Schlüssel des Hauptsatzes an dieser Stelle zu ermitteln bzw. wenn dies nur auf Kosten der Laufzeit möglich ist, dann ist mit dem Fachbereich und dem Betrieb frühzeitig zu klären, ob an dieser Stelle ein anderer Schlüssel ausgegeben werden kann. |
|
Liste von statistischen Daten, die während des Batchlaufs ermittelt wurden. |
||
|
|
Text |
ID des Statistik-Eintrags |
|
|
Text |
Klartext des Eintrags, z. B. „Anzahl gelöschter Datensätze“ |
|
|
Text |
Statistischer Wert, z. B. Anzahl der gelöschten Datensätze |
|
|
Text |
Datum des Endes des Batchlaufs |
|
|
Text |
Uhrzeit des Endes des Batchlaufs |
|
|
Text |
Return-Code der Batch-Verarbeitung |
|
|
Text |
Den Return-Code zugeordneter Text |
Beispiel für ein Batchprotokoll:
<?xml version="1.0" encoding="UTF-8"?>
<Batch-Ergebnis>
<Start BatchID="GenersicheAnwendungLoeschBatch" Datum="2017-01-30" Uhrzeit="09:33:53" Parameter="-start -cfg /resources/batch/batch-loeschen-config.properties -Batchrahmen.Ergebnisdatei loeschen-batch_out.xml"/>
<Meldungen>
<Meldung ID="COMMIT" Typ="I" Text="Checkpunkt geschrieben."/>
<Meldung ID="ENDE" Typ="I" Text="Batch beendet."/>
</Meldungen>
<Statistik>
<Statistik-Eintrag ID="ANZAHL_GELOESCHT" Text="Anzahl gelöschter generischer Anwendungen" Wert="5"/>
</Statistik>
<Ende Datum="2017-01-30" Uhrzeit="09:33:58"/>
<Return-Code RC="0" Text="Verarbeitung ohne Fehler durchgeführt."/>
</Batch-Ergebnis>Zur Auswertung der Ergebnisdatei können XSLT-Stylesheets verwendet werden, die die Ergebnisdatei in eine Textdatei bzw. in HTML umwandeln. Es handelt sich hierbei um eine fachliche Transformation der Daten mit dem Ziel, diese für den Fachbereich zu filtern, zu aggregieren oder in einem bestimmten Format zu Weiterverarbeitung bereitzustellen.
Wenn die Verarbeitung erfolgreich beendet wurde, endet der Batchrahmen mit dem Return-Code 0. Er endet mit einem anderen Return-Code, falls der Batch mit einem Fehler beendet wurde oder gar nicht gestartet werden konnte. Bei Fehlern in den „Ausführungsbeans“ kann der zurückzugebende Return-Code über die aufgetretenen Exceptions bestimmt werden (siehe Kapitel Informationen zur Authentifizierung bereitstellen).
Pro Batch müssen die möglichen Rückgabewerte definiert werden. Die folgenden Werte sind reserviert und müssen von jedem Batch zurückgegeben werden, wenn das entsprechende Ereignis eingetreten ist:
| Return-Code | Bedeutung |
|---|---|
0 |
Verarbeitung ohne Fehler durchgeführt |
1 |
Verarbeitung mit Fehlern durchgeführt |
2 |
Verarbeitung mit Fehlern abgebrochen |
3 |
Batch konnte wegen Fehlern in den Aufrufparametern nicht gestartet werden |
4 |
Batch konnte wegen Fehlern in der Batch-Konfiguration nicht gestartet werden |
143 |
Batch wurde vom Benutzer abgebrochen. |
144 |
Batch wurde durch die Überschreitung der konfigurierten maximalen Laufzeit abgebrochen. |
6.8. Testmodus
Der Batch im Testmodus arbeitet analog zum normalen Wirkbetrieb, jedoch werden keine Änderungen an Datenbeständen vom Anwendungssystem oder Nachbarsystemen durchgeführt. Der Testmodus ist für den Betrieb wichtig, um Abschätzungen der Laufzeit durchführen zu können und somit den Batchbetrieb planen können. Weiter ist der Testlauf für Bereinigungsläufe wichtig, da so der Fachbereich sehen kann, welche Änderungen durch den Bereinigungslauf ausgeführt werden würden.
In diesem Kapitel werden Architekturmuster zur Umsetzung des Testmodus beschrieben:
-
Der Batch arbeitet wie im Wirkbetrieb und statt der Commits findet immer ein Datenbank-Rollback statt (siehe Kapitel Testmodus mit Rollback).
-
Die Batch-Logik wird ausgeführt, jedoch finden keine Schreiboperationen in der Datenbank oder Aufrufe von Nachbarsystemen statt, welche Änderungen in deren Datenbestand zur Folge hätten (siehe Kapitel Testmodus ohne Schreiboperationen).
6.8.1. Testmodus mit Rollback
Dieses Muster sieht vor, dass bei der Batchverarbeitung statt eines Commits ein Rollback ausgeführt wird, sodass die Änderungen, die durch den Batch erzeugt werden, nicht in die Datenbank geschrieben werden. Das Muster ist für datenbankorientierte Batches gut geeignet, die keine Änderungen an Nachbarsystemen erfordern.
Einige Batches vermerken ihren Arbeitsfortschritt in der Datenbank. Damit der Batch trotz Rollback nicht in eine Endlosschleife gerät, darf diese Änderung nicht zurückgerollt werden. Dies kann wie folgt umgesetzt werden:
Der Batch schreibt zu Beginn die IDs aller zu verarbeitenden Sätze in eine gesonderte „Task“-Tabelle. In jedem Schritt ermittelt der Batch einen Satz aus der Task-Tabelle, löscht diesen und verarbeitet den zugehörigen Datensatz. Im Testmodus wird das Löschen des Tasks in einer separaten Transaktion durchgeführt und so nicht zurückgerollt.
Folgendes Code-Beispiel demonstriert dieses Muster:
public VerarbeitungsErgebnis verarbeiteSatz() throws BatchAusfuehrungsException {
MeinBatchTask task = meinBatchTaskDao.leseEintrag();
meinBatchTaskDao.loesche(task);
// Wenn Testmodus, neue Transaktion starten
TransactionStatus txStatus = null;
if (testmodus) {
txStatus = transactionManager.getTransaction(new DefaultTransactionDefinition(TransactionDefinition.PROPAGATION_REQUIRES_NEW));
txStatus.setRollbackOnly();
}
fristenkontrolle.pruefeFrist(task.getSatznummer());
// Wenn Testmodus, Transaktion zurücksetzen
if (testmodus) {
transactionManager.rollback(txStatus);
}
}Die Umsetzung des Testmodus mit einem Datenbank-Rollback eignet sich vor allem zur Überprüfung der fehlerfreien Durchführung und bei der Bestimmung der Laufzeit eines Batches. Zusätzlich ist bei einer entsprechenden Protokollierung nachvollziehbar, welche Datensätze der Batch verarbeitet hat.
6.8.2. Testmodus ohne Schreiboperationen
Ein weiteres Konzept für die Umsetzung des Testmodus sieht vor, dass ändernde Operationen in der Datenbank unterbunden werden. Änderungen in der Datenbank oder in Nachbarsystemen werden durch entsprechende If-Abfragen abgefangen.
Dieses Muster ist dann einzusetzen, wenn die Realisierung durch ein Rollback nicht möglich oder angemessen ist. Durch Tests muss sichergestellt werden, dass nicht trotz Testmodus versehentlich Änderungen durchgeführt werden.
Das Muster ist geeignet, um im Testmodus durch die Auswertung der Batch-Protokolle und Logs die Auswirkungen bzw. durchgeführten Änderungen eines Batches vorab zu überprüfen. Es ist nicht geeignet zur Bestimmung der Laufzeit oder für die vollständige Sicherstellung der fehlerfreien Batchausführung, da Fehler bei Schreiboperationen in die Datenbank oder dem Aufruf von Nachbarsystemen nicht auftreten können.
7. Die Ausführungsbeans
Im vorangegangenen Kapitel wurden die Eigenschaften des Batchrahmens erläutert. Dieser existiert bereits und muss verwendet werden, indem Ausführungsbeans dafür entwickelt werden. In diesem Kapitel werden Vorgaben für die Ausführungsbeans definiert.
7.1. Namenskonvention
Analog zu den Anwendungsfällen werden Batchklassen mit dem Präfix Bat gekennzeichnet.
| Batches: Klassen | |
|---|---|
Schema |
|
Beispiele |
|
7.2. Keine Transaktionssteuerung in einer Ausführungsbean
Eine Ausführungsbean darf keine Transaktionen starten oder beenden.
Sämtliche vom Batchrahmen aufgerufenen Operationen (Operationen von Interface BatchAusfuehrungsBean) werden innerhalb einer Transaktion aufgerufen.
Die Ausführungsbean muss sich hiermit nicht befassen.
7.3. Logging, Protokollierung und Statistik-Aufrufe implementieren
Der Batchrahmen führt Logging nur im Fehlerfall durch. Die restlichen Informationen müssen durch die Ausführungsbean geloggt, protokolliert oder einer Statistik-Komponente übergeben.
Dazu wird die Ausführungsbean bei allen wichtigen Ereignissen aufgerufen:
-
Beim Start des Batches
-
Beim Schreiben eines Checkpoints
-
Beim Beenden des Batches
-
Bei der Verarbeitung eines Satzes
Jeder Batch erhält eine eigene Korrelations-ID.
| In älteren Versionen des Batchrahmens handelte es sich bei der Korrelations-ID für Batches um die ID des Batches. Mittlerweile wurde dies durch eine UUID ersetzt. |
Zusätzlich erhält jeder zu verarbeitende Satz auch eine eigene Korrelations-ID, welche an die Korrelations-ID des Batches angehängt wird. Die entstehende Korrelations-ID Kette wird dann dem Aufruf-Kontext hinzugefügt.
7.4. Fachliche Logik in den Komponenten der Geschäftsanwendung implementieren
Falls für die Verarbeitung im Batch Fachlogik benötigt wird, welche für die Webanwendung nicht benötigt wird, ist diese trotzdem den Geschäftsanwendungskomponenten hinzuzufügen. Die Ausführungsbean erhält die Referenzen auf die Komponenten über Dependency Injection und ruft die Fachlogik dort auf.
Auch wenn in Sonderfällen Datenbank-Aufrufe direkt durch die Ausführungsbean ausgeführt werden müssen, ist die sonstige fachliche Logik an die Fachkomponenten der Geschäftsanwendung zu delegieren.
7.5. Plausibilitätsprüfung in der Initialisierung
Im Rahmen der Initialisierung hat die Ausführungsbean unter anderem die Aufgabe, die Konsistenz und Korrektheit der Eingabedaten zu prüfen. Dies kann beispielsweise ein erstes Durchlaufen der zu verarbeitenden Datei beinhalten. Werden hierbei Fehler erkannt, muss ein entsprechender Fehler geworfen werden.
7.6. In Initialisierung Schlüssel lesen, Satz-Verarbeitung über Lookups
Falls die zu verarbeitenden Sätze eines Batches das Ergebnis einer Datenbank-Query sind, ist folgendermaßen vorzugehen:
-
In Rahmen der Initialisierung ist die Query über eine Fachkomponente abzusetzen. Diese Query soll die (fachlichen) Schlüssel von Entitäten, nicht die Entitäten selbst auslesen.
-
Die zurückgegebenen Schlüssel sind in einer Liste zu speichern und die Query ist zu schließen.
-
Beim Aufruf für eine Satzverarbeitung ist die Entität über ihren Schlüssel aus der Datenbank auszulesen und die Verarbeitung durchzuführen.
Dies bietet gegenüber dem Auslesen von Entitäten in der Query folgende Vorteile:
-
Würden Entitäten ausgelesen, wären diese nach einem Commit während der Verarbeitung nicht mehr mit einer Transaktion verbunden.
Hibernate liest Entitäten bereits bei derhasNext()-Abfrage eines Resultset-Iterators ab. So kommt es bei Checkpoints zwangsläufig zu toten Entitäten.Falls (in einem ungewöhnlichen Sonderfall) mit ResultSet-Iteratoren gearbeitet werden muss, so sollte mit einem HibernateScrollableResultgearbeitet werden. Siehe Hibernate-Referenzdokumentation. -
Durch das Ablegen der Schlüssel in einer Liste ist die Gesamtanzahl der Datensätze bekannt.
7.7. Informationen zur Authentifizierung bereitstellen
Batches müssen beim Start authentifiziert und autorisiert werden, bevor der fachliche Teil der Batchverarbeitung starten kann.
Der Batchrahmen fordert, dass in der BatchKonfiguration zur Batch spezifischen Batch-ID das neue Property oauth2ClientRegistrationId hinzugefügt wird, dessen Wert als Indirektion auf eine ClientRegistration führt, um den Batch über den Baustein isy-security zu authentifizieren.
7.8. Fehlerbehandlung in Ausführungsbeans durchführen
Die Batches sind möglichst robust zu konstruieren: Falls auf ein fachliches Problem in der Ausführungsbean reagiert werden kann, sollte dies getan werden.
Der Batchrahmen unterstützt beispielsweise nicht das Auslassen von Datensätzen im Fehlerfall (etwa für eine Verarbeitung im nächsten Batch). Falls dies umgesetzt werden soll, ist eine entsprechende Verarbeitung in der Ausführungsbean zu implementieren.
Wenn eine Ausführungsbean einen Fehler wirft, so muss dies eine BeanAusfuehrungsException oder ein davon erbender Fehler sein.
In diesen Exceptions ist es möglich, den Return-Code des Batches zu definieren.
Die Return-Codes sind für den konkreten Batch zu konfigurieren und müssen den Vorgaben in
Abschnitt Rückgabewerte des Batchrahmens entsprechen.
Wichtig ist, dass ein Batch bei einem Fehler, den der Batch nicht behandeln kann, abbricht und nicht endlos weiter läuft. Dieses Vorgehen ermöglicht es dem Betrieb, die Ursache des Fehlers zu korrigieren und den Batch neu zu starten.
7.9. Beispiele Satzverarbeitung
Abschließend ist in die beispielhafte Satzverarbeitung in einer Batch-Ausführungsbean zu sehen. Die gezeigte Satzverarbeitung setzt den Testmodus um, die Anwendungslogik ist weiterhin im Anwendungskern umgesetzt und sie übernimmt Logging, Protokollierung und Statistik-Zählung.
@Override
public VerarbeitungsErgebnis verarbeiteSatz() throws BatchAusfuehrungsException {
// Hole nächsten Task, wenn vorhanden.
if (CollectionUtils._isEmpty_(vorgangsIds)) {
return new VerarbeitungsErgebnis(null, true);
}
int vorgangsId = vorgangsIds.remove(vorgangsIds.size() - 1);
// Wenn Testmodus, neue Transaktion starten
TransactionStatus txStatus = pruefeStartSimulation();
// Laden des Vorgangs und Aufruf der AWK Komponente
// zum Versenden der Mitteilung
VorgangRo vorgang =
vorgangsverwaltung.leseVorgang(vorgangsId);
Antragsnummer antragsnummer = vorgang.getAntragsnummer();
log.debug("Versende Erinnerung zur Anfrage für Antragsnummer: " + antragsnummer + ".");
// Versende Erinnerung
try {
xxxBeteiligung.versendeErinnerungsnachricht(antragsnummer, vorgangsId);
getBatchProtokoll().ergaenzeMeldung(
new VerarbeitungsMeldung(String._valueOf_(vorgangsId), antragsnummer.toString(), MeldungTyp._INFO_, "Antragsnummer: " + antragsnummer));
statistikErinnerungVersendet.erhoeheWert();
} catch (AkteGesperrtException e) {
getBatchProtokoll().ergaenzeMeldung(
new VerarbeitungsMeldung(String._valueOf_(vorgangsId), antragsnummer.toString(),
MeldungTyp._WARNUNG_, e.getFehlertext()));
}
// Wenn Testmodus, Transaktion zurücksetzen
pruefeEndeSimulation(txStatus);
return new VerarbeitungsErgebnis(String._valueOf_(vorgangsId), false);
}7.9.1. Sonderfall Blocklöschung
Es ist nicht zwingend erforderlich, dass in einem Satz nur eine einzelne Aktion (bspw.
Löschung) durchgeführt wird. Bei großen Datenmengen kann es durchaus Sinn sinnvoll sein, pro Satz eine bestimmte Anzahl Datensätze auf einmal zu verarbeiten, wie im folgenden Codebeispiel zu sehen ist.
Die Variable blockgroesse ist dabei konfigurativ zu setzen.
Wichtig ist in so einem Sonderfall, dass das Commit-Intervall des Batches entsprechend niedrig eingestellt ist (siehe Kapitel Konfigurationsdatei und Kommandozeilen-Parameter), da ansonsten (Blockgröße * Commit-Intervall) viele Datensätze mit einer Transaktion verarbeitet werden.
@Override
public VerarbeitungsErgebnis verarbeiteSatz() throws BatchAusfuehrungsException {
log.debug("Lösche Nachrichten älter als " + fristdatum + " (Blockgröße " + blockgroesse + ").");
// Wenn Testmodus, neue Transaktion starten
TransactionStatus txStatus = pruefeStartSimulation();
int anzahlGeloeschterEintraege = nachrichtenverwaltung.loescheNachrichtenOhneAkte(fristdatum, blockgroesse);
log.debug(anzahlGeloeschterEintraege + " Nachrichten gelöscht.");
geloeschteNachrichtenStatistik.setWert(geloeschteNachrichtenStatistik.getWert() + anzahlGeloeschterEintraege);
// Wenn Testmodus, Transaktion zurücksetzen
pruefeEndeSimulation(txStatus);
return new VerarbeitungsErgebnis(null, anzahlGeloeschterEintraege < blockgroesse);
}7.9.2. Sonderfall eigenständige Transaktionssteuerung
Unter bestimmten Umständen kann es notwendig sein, die Transaktionssteuerung des Batchrahmens zu umgehen. Dies ist beispielsweise der Fall, wenn ein im Datenzugriff auftretender Fehler aus der Datenbank ignoriert werden soll. Das Auftreten einer solchen Exception führt dazu, dass die Transaktion nur noch zurückgerollt werden kann, selbst wenn die Exception gefangen und ignoriert wird.
Um dieser Problematik zu begegnen, kann in der Satzverarbeitung selbst die Transaktionsklammer nur für einen Satz geöffnet und nach der Verarbeitung entweder committed oder zurückgerollt werden.
In diesem Fall sollte das Commit-Intervall des Batchrahmens entsprechend hoch konfiguriert werden, um unnötige Commits zu vermeiden, auch wenn in dieser Transaktion nichts passiert.
8. Ausnahmeregelungen
In bestimmten Situationen, z. B. bei der Verarbeitung extrem großer Datenmengen, kann der Fall auftreten, dass die Implementierung eines Batchschritts in Java nicht sinnvoll ist. In solchen Fällen muss dann eine Sonderlösung, wie z. B. ein SQL-Skript oder ein Shell-Skript, gefunden werden. Shell-Skripte sind in dem folgenden Kapitel Shell-Batches beschrieben.
Die Entscheidung, ob in einem solchen Einzelfall eine Sonderlösung gewählt werden kann, muss zwingend in einer Architekturentscheidung erfolgen. Eine solche Abweichung von der Referenzarchitektur muss im Systementwurf in der Liste der Abweichungen aufgeführt und begründet werden. Dabei muss die Abwägung getroffen werden zwischen der Einhaltung der nicht-funktionalen Anforderungen und der Verringerung der Wartbarkeit durch mehrfach implementierte Funktionalität.
Wichtig ist, dass die einheitliche Außenschnittstelle der Batchschritte erhalten bleibt, d. h. anhand der übergebenen Parameter, Rückgabewerte, geloggten Daten darf für den Nutzer des Batchschritts nicht erkennbar sein, dass dieser in einer anderen Technologie umgesetzt ist.
Die Dokumentation der abweichenden Batchimplementierung erfolgt im Systementwurf und wird daraus in die Systemdokumentation übernommen.
9. Shell-Batches
9.1. Was ist ein Shell-Batch?
Als Shell-Batch wird ein Shell-Skript bezeichnet, das Stapelverarbeitungsbefehle ausführt, die direkt in diesem Skript definiert sind. Damit fallen sie unter die Ausnahmeregelungen des vorherigen Kapitels Ausnahmeregelungen. Reguläre Batches werden meist ebenfalls über ein Shell-Skript gestartet, ihre Logik ist aber in Java programmiert. Das Skript startet also nur das zugehörige Programm.
Der Vorteil von Shell-Batches ist, dass sie etwas schlanker sind und daher auch schneller entwickelt werden können. Komplexe fachliche Logik sollte aber immer als dediziertes Batchprogramm umgesetzt werden, da diese auf lange Sicht besser wartbar sind.
Ein Beispiel für Shell-Batches sind einmalige SQL-Migrationen. Das Shell-Skript baut dabei eine Verbindung mit dem Datenbank-Server auf und führt eine SQL-Datei aus.
Es gibt aber auch Systeme die im regulären Wirkbetrieb regelmäßig Shell-Batches ausführen; bspw. um Datenbankabzüge für statistische Auswertungen zu erstellen.
9.2. Aufbau von Shell-Batches
Ein Shell-Batch besteht aus einem SH-Skript und ggf. weiteren Dateien:
-
Property-Datei für Konfigurationen, wie bspw. die zu verwendende Datenbankverbindung
-
SQL-Skripte, die vom SH-Skript ausgeführt werden
-
weitere SH-Skripte die, die vom SH-Skript ausgeführt werden
9.2.1. Namenskonvention
Ein Shell-Skript muss folgender Namenskonvention folgen:
| Batches: Shellskript | |
|---|---|
Schemata |
|
Beispiele |
|
Die Dateien sollten entweder in einen eigenen Ordner unter /opt abgelegt werden oder – falls der Batch Teil eines bestehenden Batch-Projekts ist – in den vorhandenen Batch-Ordner des Systems deployt werden.
In letzterem Fall sollte das Deployment über das RPM des Batch-Projekts erfolgen. Andernfalls ist – insbesondere bei nur einmaligen Migrationsbatches – ein manuelles Deployment möglich.
Die SH-Skripte müssen immer nach dem folgenden Schema aufgebaut werden:
-
Beschreibungskommentar mit Parametern und Rückgabewerten
-
Automatisches Ermitteln des Home-Verzeichnisses des Batches
-
Einlesen der Übergabe-Parameter
-
Einlesen notwendiger Properties aus den Konfigurationsdateien
-
Ausführen der eigentlichen Batchlogik
Der Batch gibt zudem die Startzeit, Endzeit und Laufzeit aus.
Es müssen dokumentierte Return-Codes für erwartete Fehlerfälle verwendet werden, um die Fehleranalyse zu vereinfachen.
Folgende Rahmenbedingungen sind bei der Umsetzung einzuhalten:
-
Das Home-Verzeichnis, in dem das SH-Skript liegt, wird automatisiert ermittelt und wird nicht als Parameter übergeben.
-
Das Log-Verzeichnis muss ein optionaler Parameter sein (und damit als letzter Eingabeparameter definiert sein). Bei Nichtangabe wird der Standard-Logpfad unter
<HOMEVEREICHNIS>/log/verwendet. -
Datenbankverbindungsangaben müssen in einer Konfigurationsdatei (
<HOMEVERZEICHNIS>/etc/jpa.properties) stehen und dürfen nicht als Parameter übergeben werden. -
SQL-Skripte, die vom SH-Skript verwendet werden, müssen im Verzeichnis
<HOMEVERZEICHNIS>/sql/abgelegt werden. -
Weitere SH-Skripte, die vom Hauptskript aufgerufen werden, müssen unter
<HOMEVERZEICHNIS>/sh/abgelegt werden.
Im Folgenden ist ein Beispiel-Template eines Shell-Batches angegeben:
#!/bin/bash
#===========================================================
# Beispiel Shellbatch
#
# Vorbedingungen
# - Leeres Datenbank Schema angelegt
#
# Parameter
# - Optional: Verzeichnis, in dem die Log-Dateien abgelegt werden
#
# Rückgabewerte:
# - 0 = Erfolg
# - 10 = Keine OracleConnection angegeben (jpa.properties existiert nicht oder enthält den Schlüssel database.connection nicht)
# - 20 = Fehler beim Ausführen von Schritt 1 (01_tabelle-erstellen.sql)
# - 30 = Fehler beim Ausführen von Schritt 2 (02_tabelle-loeschen.sql)
#
# Version: $Id: shellbatch.sh <revision> <datum> <user> $
#
#===========================================================
#Zeit zu Beginn ermitteln +
start=`date +%s`
# Home-Verzeichnis ermitteln
HomeVerzeichnis=$(cd -P -- "$(dirname -- "$0")" && pwd -P)
# Parameter prüfen
if [ -z "$1" ] ; then
LogVerzeichnis=$\{HomeVerzeichnis}/log/
else
LogVerzeichnis=$1
Fi
# Auslesen der Oracle-Datenbankverbindung aus einer Konfigurationsdatei (jpa.properties).
PROPERTY_FILE="$\{HomeVerzeichnis}/etc/jpa.properties"
PROP_KEY="database.connection"
# Alles nach dem ersten "=" wird gematched (inklusive Leerzeichen)
OracleConnection=`cat $PROPERTY_FILE | grep "$PROP_KEY" | sed 's/[^=]*=\(.*\)/\1/'`
if [ -z "$OracleConnection" ] ; then
echo "+++ OracleConnection konnte nicht ermittelt werden. Existiert die jpa.properties Datei und ist der richtige Schlüssel enthalten? Abbruch!"
exit 10
fi
# Startmeldung
echo "# "$(basename $0)" um "$(date +%Y-%m-%d-%T)" gestartet"
RC=0
# Batchschritte
# 1. Ausführen eines SQL-Skripts mit SQL-Plus
if [ $\{RC} = "0" ]; then
echo "# Fuehre 01_tabelle-erstellen.sql aus ..."
LogDatei=$\{LogVerzeichnis}/shellbatch_$(date +%Y-%m-%d_%H-%M-%S).log
cd $\{HomeVerzeichnis}/sql
sqlplus "$\{OracleConnection}" @01_tabelle-erstellen.sql | tee $\{LogDatei}
res=$?
AnzahlFehler=$(egrep -c "SP2\-[0-9]\{4}\:|ORA\-[0-9]\{5}\:" $\{LogDatei})
if [ $\{AnzahlFehler} -ne 0 ]; then
echo "+++ "$\{AnzahlFehler}" Fehler in Schritt 01, RC="$\{res}"!"
RC=20
fi
fi
# 2. Ausführen eines weiteren SQL-Skripts mit SQL-Plus
if [ $\{RC} = "0" ]; then
echo "# Fuehre 02_tabelle-loeschen.sql aus ..."
LogDatei=$\{LogVerzeichnis}/shellbatch_$(date +%Y-%m-%d_%H-%M-%S).log
cd $\{HomeVerzeichnis}/sql
sqlplus "$\{OracleConnection}" @02_tabelle-loeschen.sql | tee $\{LogDatei}
res=$?
AnzahlFehler=$(egrep -c "SP2\-[0-9]\{4}\:|ORA\-[0-9]\{5}\:" $\{LogDatei})
if [ $\{AnzahlFehler} -ne 0 ]; then
echo "+++ "$\{AnzahlFehler}" Fehler in Schritt 02, RC="$\{res}"!"
RC=30
fi
fi
end=`date +%s`
# Ende-Meldung
echo "Shell-Batch wurde erfolgreich beendet. - Laufzeit" $(($end - $start)) "Sekunden"
echo "# "$(basename $0)" um "$(date +%Y-%m-%d-%T)" mit RC="$\{RC}" beendet"
exit $\{RC}Eine funktionsfähige Version dieses Beispiels ist im isy-batchrahmen unter src/main/skripte/shellbatch_template/ eingecheckt.
Um dieses ausführen zu können, muss eine funktionierende Datenbankverbindung auf ein leeres Schema in der jpa.properties Datei angegeben werden.