Softwaretechnische Architektur: Inhalt
1. Technische Architektur
Die technische Architektur (T-Architektur) beschreibt die Strukturierung der IsyFact-Plattform in IT-Systeme, den Aufbau einzelner IT-Systeme und die verwendeten übergreifenden technischen Konzepte.
1.1. Die Referenzarchitektur eines IT-Systems
Die individuell erstellten Anwendungssysteme der Systemlandschaft müssen technisch gleichartig aufgebaut sein. Daher wird im Folgenden die Referenz-Architektur beschrieben, nach der diese Anwendungssysteme software-technisch in IT-Systeme umgesetzt werden.
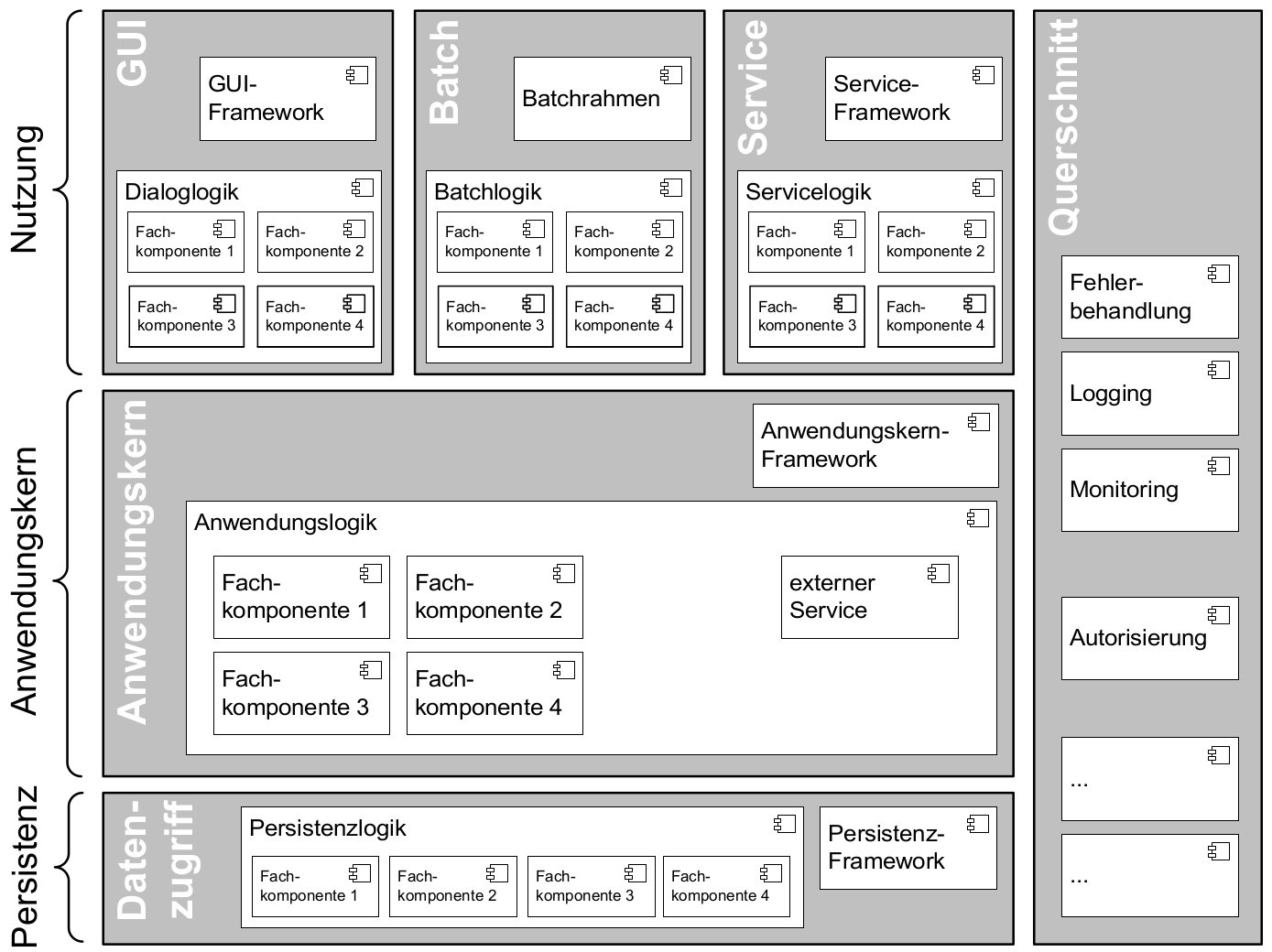
In der Persistenzschicht ist alle Funktionalität enthalten, die zum Erzeugen, Suchen, Bearbeiten und Löschen von Datenobjekten benötigt wird. Der Datenzugriff auf das DBMS ist in dieser Schicht vollständig gekapselt. In Richtung Datenbank kommuniziert diese Schicht mittels JDBC und SQL, in Richtung des Anwendungskerns stellt die Schicht Geschäftsobjekte zur Verfügung. Die Persistenz nutzt dazu das Framework Hibernate über die Java Persistence API (JPA).
Der Anwendungskern umfasst die fachliche Logik zur Datenbearbeitung, die mit dem System realisiert werden soll. Dazu gehören zum Beispiel Datenvalidierungen oder Funktionen zum Verarbeiten von Geschäftsobjekten, die über den Datenzugriff geladen wurden.
Die Nutzungsschicht ist eine Erweiterung der klassischen Drei-Schichten Architektur, in der die dritte Schicht als GUI oder Präsentation bezeichnet wird. In der Referenzarchitektur für ein IT-System wird diese Schicht noch zusätzlich erweitert um Batch und Service.
-
Aufgabe der GUI ist es, die Funktionalität der Anwendung für einen menschlichen Anwender zur Verfügung zu stellen. Dabei unterstützt die GUI den Bearbeitungsprozess einer fachlichen Aufgabe. Innerhalb des Bearbeitungsprozesses stellt sie Dialoge dar und transferiert die durch den Anwendungskern gelieferten Datenobjekte in eine präsentable Form. Dies kann sowohl durch eine Web-basierte HTML-GUI als auch durch eine sogenannte Rich-Client-Anwendung geschehen.
-
Aufgabe des Batches ist es, automatisierte Prozesse ohne einen direkten menschlichen Anwender durchzuführen. Dabei nutzt der Batch ebenfalls die Funktionen des Anwendungskerns. Auch hier gibt es spezielle Batch-Schritte, die exklusiv vom Batch benötigt werden und deshalb nicht Bestandteil des Anwendungskerns sind. Eine Besonderheit beim Batch ist, dass die Steuerung des Batch-Prozesses in der Regel über ein Scheduling-Werkzeug erfolgt.
-
Der dritte Aufrufende von Anwendungslogik sind andere Anwendungen, die mittels Services auf den Anwendungskern zugreifen. Dieser Zugriff erfolgt nicht direkt auf den Anwendungskern, sondern über die Nutzungsschicht „Service“. Dadurch können auf einfache Art technische Attribute in die Außenschnittstelle aufgenommen werden und der Service des Anwendungskerns kann auf die Kommunikationstechnik abgebildet werden, die für die Kommunikation zwischen IT-Systemen verwendet wird.
Details zur Konstruktion eines IT-Systems werden im IsyFact Systementwurf festgelegt und für das jeweilige IT-System dokumentiert.
1.2. Übergreifende technische Konzeption
Für den Aufbau eines IT-Systems gelten einige übergreifende technische Regeln, die im Folgenden vorgestellt werden.
Strukturierung des IT-Systems: Aufgrund der durch die Fachlichkeit festgelegten Funktionalität können IT-Systeme sehr komplex werden. Um diese Komplexität beherrschen zu können, wird das IT-System in Komponenten zerlegt, die jeweils genau festgelegte Teilfunktionalitäten erfüllen. Damit die gesamte geforderte Funktionalität erreicht wird, müssen die einzelnen Komponenten miteinander kommunizieren und sich kennen. Dadurch entsteht ein Komponentengeflecht. Für die Verwaltung der Komponenten innerhalb des IT-Systems und deren Kopplung wird ein Framework verwendet. Details hierzu werden im Detailkonzept Komponente Anwendungskern festgelegt. Technisch lässt sich ein IT-System in Schichten unterteilen, fachlich in Teilanwendungen. Details hierzu werden in Kapitel Der Anwendungskern beschrieben.
Transaktionen: Veränderungen am Datenbestand gehören zur Kernaufgabe von Informationssystemen. Diese Veränderungen können jedoch nicht beliebig erfolgen – sie müssen gewisse Eigenschaften haben, damit die Datenbestände nicht an Qualität verlieren: Sie müssen atomar, konsistent, isoliert und dauerhaft sein. In der Fachliteratur sind diese Eigenschaften als ACID-Eigenschaften (atomicity, consistency, isolation, durability) bekannt.
Änderungen am Datenbestand können komplex sein, das heißt es können viele Informationen und Zusammenhänge von den Änderungen betroffen sein. Solche komplexen Änderungen werden vom Informationssystem meist in einzelne, einfache Änderungsschritte zerlegt. Damit die ACID-Eigenschaften der komplexen Änderung erhalten bleiben, muss das Informationssystem entweder alle Änderungsschritte ausführen oder keinen. Damit es dazu in der Lage ist, werden die Änderungsschritte zunächst zu einer logischen Einheit zusammengefasst – einer Transaktion.
Für die Referenzarchitektur wird festgelegt, dass die Nutzungsschicht für die Steuerung der Transaktionen zuständig ist. Der Anwendungskern selbst steuert in der Regel keine Transaktionen. Er bietet der nutzenden Schicht eine Schnittstelle zur Transaktionssteuerung an, d. h. der Anwendungskern wird durch die Nutzungsschicht gesteuert.
Zugriffe auf die Datenbank: Bei Zugriffen auf die Datenbank werden die Objekte des Anwendungskerns auf die relationalen Tabellenstrukturen der Datenbank abgebildet. Dabei müssen folgende Aufgaben erfüllt werden:
-
Objekt-relationales Mapping: die Daten der relationalen Datenbank werden Attributen von Objekten zugeordnet. Dabei werden Datentypen der Datenbank in ihre Objekt-Äquivalente umgesetzt, eine Abbildung von Vererbung im Objektmodell auf relationale Strukturen durchgeführt und Fremdschlüsselbeziehungen zwischen Tabellen durch Relationen zwischen Objekten abgebildet.
-
Objektidentität: Wenn ein Datensatz im Verlauf der Bearbeitung mehrmals gelesen wird, so muss dafür gesorgt werden, dass nicht mehrfach gleiche Objekte in einer Anwendung erzeugt werden.
-
Transaktionssteuerung und Sperren: Es müssen fachliche Transaktionen auf technische Transaktionen gegen die Datenbank abgebildet werden. Dabei wird eine optimistische Sperrstrategie umgesetzt. Ein übliches Verhalten ist zum Beispiel das Folgende: Erstreckt sich eine fachliche Transaktion über mehrere Dialogschritte, wird die Zugriffsschicht erst beim Verlassen des letzten Dialogs eine technische Datenbanktransaktion auslösen. Um zu prüfen, ob die Daten in der Zwischenzeit nicht durch einen anderen Anwender verändert worden sind, wird die Zugriffsschicht beim Schreiben Zeitstempel oder Versionszähler der Datensätze überprüfen.
Um diesen großen Funktionsumfang abzudecken, wird ein Produkt zum objekt-relationalen Mapping gemäß JPA-Standard eingesetzt. Details hierzu sind im Baustein JPA/Hibernate dokumentiert.
Caching: Anwendungsspezifische Caches sind mit Spring Cache Abstraction zu implementieren. Die Caching-Funktionalität wird so mit Spring Cache Abstraction und einem Caching Provider (z.B. EHCache) bereitgestellt. Spring Cache Abstraction bietet eine effiziente und flexible Möglichkeit Caching in Anwendungen zu implementieren. Weitere und detaillierte Informationen sind in der Spring Dokumentation einzusehen. Durch die Verwendung von Spring Cache Abstraction wird, z.B. über die Nutzung von Annotationen, das Hinzufügen von Caching zu bestehenden Methoden erleichtert. Der zugrundeliegende Code ist nicht wesentlich zu verändern. Mit dem abstrahierten Caching ist die Cache-Implementierung unabhängig von dem genutzten Cache-Provider. Die Wahl des Cache-Providers ist gemäß einer notwendigen Skalierung und betrieblichen Gegebenheiten abzustimmen. EHCache wird empfohlen (Vlg. Produktkatalog: Entwicklung). Für weitere Informationen zu EHCache sind in der EHCache Dokumentation einzusehen.
1.3. Der Anwendungskern
Der Anwendungskern ist der zentrale Baustein eines IT-Systems. Hier werden die fachlichen Funktionen der Anwendung realisiert.
Der Anwendungskern besteht aus zwei wesentlichen Bestandteilen: den Fachkomponenten und dem Anwendungskern-Framework. Weiterhin ist dort dargestellt, dass externe Services als Komponente in den Anwendungskern integriert sind. Diese drei Aspekte werden im Folgenden im Detail beschrieben.
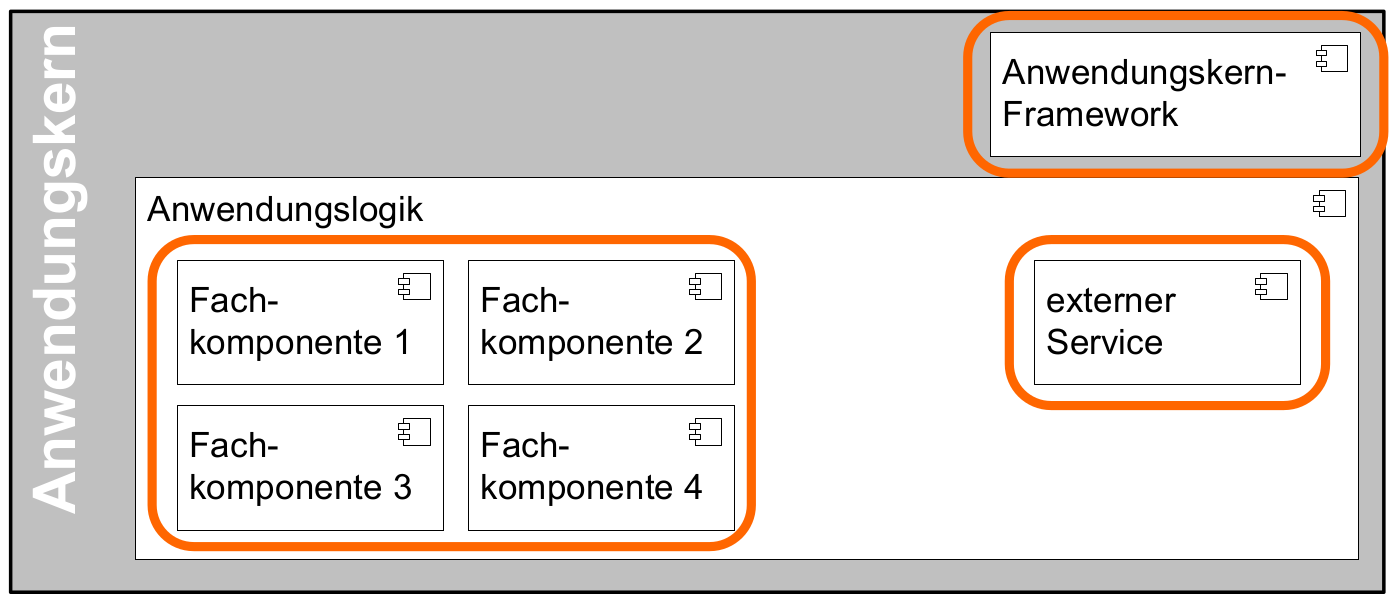
Nicht Teil des Anwendungskerns sind spezielle Dialogabläufe, z.B. dialogspezifische Bearbeitungsverfahren wie die Anwenderführung über Wizards. Diese Prozesse, die nur durch einen einzigen Dialog genutzt werden, sind Teil der Schicht Nutzung. Der Anwendungskern stellt somit im Wesentlichen allgemein nutzbare Services zur Verfügung.
Fachkomponenten setzen die Anwendungskomponenten aus der fachlichen Architektur um. Sie bilden damit den Schnitt der Anwendungskomponenten in die technische Architektur ab. Fachkomponenten beinhalten möglichst wenig Technik und trennen so Anwendungslogik von Technologie.
Eine allgemeine Anwendung enthält die Fachkomponenten Erstellung, Teilnahme und Verwaltung.
| Fachkomponenten sind der Schlüssel für gute Wartbarkeit und einfache Weiterentwickelbarkeit des Anwendungskerns. Die Trennung von Anwendungslogik und Technik ist deshalb auch in anderen Schichten der technischen Architektur vorgesehen, z. B. in der Persistenz. |
Komponenten-Framework: Für querschnittliche Funktionalität innerhalb des Anwendungskerns wird das Spring-Framework genutzt. Hauptaufgabe des Frameworks ist es, die Komponenten zu konfigurieren und miteinander bekannt zu machen. Dadurch wird die Trennung zwischen Fachlichkeit und Technik verbessert. Beispiel für querschnittliche Funktionalität ist die deklarative Steuerung von Transaktionen.
Externe Services: Wenn der Anwendungskern fachliche Services benötigt, die von anderen IT-Systemen innerhalb der Plattform angeboten werden, so werden diese Services als Komponente im Anwendungskern abgebildet. Dadurch ist die Funktionalität sauber gekapselt, was die Wartbarkeit erhöht. Wenn der externe Service ausgetauscht werden soll, ist keine Änderung der gesamten Anwendung notwendig – es ist lediglich eine interne Änderung der externen Service-Komponente notwendig. Für andere fachliche Komponenten des Anwendungskerns ist nicht zu unterscheiden, ob es sich beim Aufruf einer Komponentenschnittstelle um eine in dieser Komponente implementierte Funktion oder um einen Serviceaufruf handelt. Komponenten, die externe Services kapseln, sind im Idealfall von außen nicht von fachlichen Komponenten des Anwendungskerns unterscheidbar. Diese Komponenten haben damit zwei Hauptaufgaben: Sie müssen die technischen Aspekte der Kommunikation umsetzen und sie müssen Schnittstellendaten und Exceptions der aufgerufenen Services in die Datenformate der Anwendung transformieren.
Weitere Details können dem Detailkonzept Komponente Anwendungskern entnommen werden.
1.4. Datenzugriff
In der Persistenz-Schicht sind die Fachkomponenten auch gemäß den Komponenten aus der fachlichen Architektur strukturiert. Die Komponenten des Anwendungskerns besitzen die Datenhoheit auf die Entitäten, die ihnen eindeutig zuzuordnen sind. Diese Entitäten stammen aus den korrespondierenden Komponenten in der Persistenz-Schicht. Nur die korrespondierende Anwendungskern-Komponente darf Änderungen an den entsprechenden persistenten Entitäten vornehmen.
Andernfalls ist nicht sichergestellt, dass andere Komponenten keine Änderungen an den persistenten Entitäten vornehmen. Für den Transfer über Komponentengrenzen hinweg - oder aus dem Anwendungskern hinaus - müssen alle Komponenten des Anwendungskerns die ihnen zugeordneten persistenten Entitäten auf Geschäftsobjekte abbilden. Wenn Entitäten von mehreren Komponenten genutzt werden und keiner einzelnen Komponente zugeordnet werden können, sollten sie in einem eigenen querschnittlichen Package abgelegt werden.
1.5. GUI
Bei grafischen Benutzeroberflächen (englisch: Graphical User Interface, GUI) gibt es eine Vielfalt unterschiedlichster Komplexitäten: von einfachen Stammdatensystemen über Dialogsysteme mit vielen einfachen Dialogen, die aber intensiv miteinander interagieren, bis zu Clients mit wenigen, aber sehr komplexen Dialogen. Eine gute Architektur muss für alle relevanten Varianten einen tragfähigen Rahmen schaffen.
Im Wesentlichen müssen innerhalb einer GUI verschiedene Aufgaben erledigt werden:
-
Die Masken und Informationen müssen am Bildschirm angezeigt werden.
-
Der Dialog muss auf Benutzerinteraktionen reagieren.
-
Einzelne Dialoge müssen ggf. zu Dialogabläufen zusammengefasst werden und benötigen Kontext-Informationen wie den aktuell angemeldeten Benutzer. Die Dialogabläufe bilden einen Workflow. Dieser ist in der Regel in der Dialogsteuerung abgebildet, er kann auch durch eine Workflow-Komponente gesteuert werden.
-
Der Dialog muss direkt mit dem Anwendungskern kommunizieren, um Daten zu lesen, die veränderten Daten zu speichern und komplexere fachliche Funktionen auszuführen.
Vorgaben zur konkreten Bedienung sind im Bedienkonzept beschrieben.
Die Validierung auf GUI-Ebene ist optional. Sie wird empfohlen, wenn sie die Benutzererfahrung verbessert. Bei Syntaxfehlern kann die GUI beispielsweise einen Hinweis anzeigen, ohne den Server aufzurufen, wodurch Zeit gespart und die Leistung verbessert wird. Die Abwehr gegen Injection-Angriffen, beispielsweise Cross Site Scripting (XSS), wird in der GUI unabhängig davon dringend empfohlen.
Trotzdem darf sich der Anwendungskern niemals auf die syntaktische Validierung der GUI verlassen und auch potenziell schädliche Eingabewerte berücksichtigen. Die fachliche Validierung der Eingabewerte erfolgt ebenfalls im Anwendungskern, da es sich um Geschäftslogik handelt und oft Datenbankabfragen erforderlich sind.
1.5.1. Klassische Web-GUI
Die in Abbildung 2 dargestellte GUI-Architektur für eine klassische Webanwendung besteht aus 4 Komponenten, die die oben geschilderten wesentlichen Aufgaben übernehmen. Diese Komponenten sind der Dialograhmen, die Dialoge, die GUI-Bibliothek und die Dialoglogik.
Dialograhmen: Die Komponente Dialograhmen definiert die Ablaufumgebung für Dialoge. Der Dialograhmen kennt die Dialogabläufe und die notwendigen Kontextinformationen.
Dialog: Aufgaben der Dialogkomponenten sind die Reaktion auf Benutzerinteraktionen und den Datenzugriff des aktuellen Dialogs.
GUI-Bibliothek: Die Komponente GUI-Bibliothek ist in der Lage, Masken am Bildschirm darzustellen und die einzelnen Elemente der Masken mit Informationen zu versorgen.
Dialoglogik: Die Komponente Dialoglogik enthält die vom Dialog benötigten Fachklassen und übernimmt die direkte Kommunikation mit dem Anwendungskern. Liegt der Anwendungskern auf einem Server, so speichert der Anwendungskern auch Login-Informationen, Session-Daten und ähnliches.
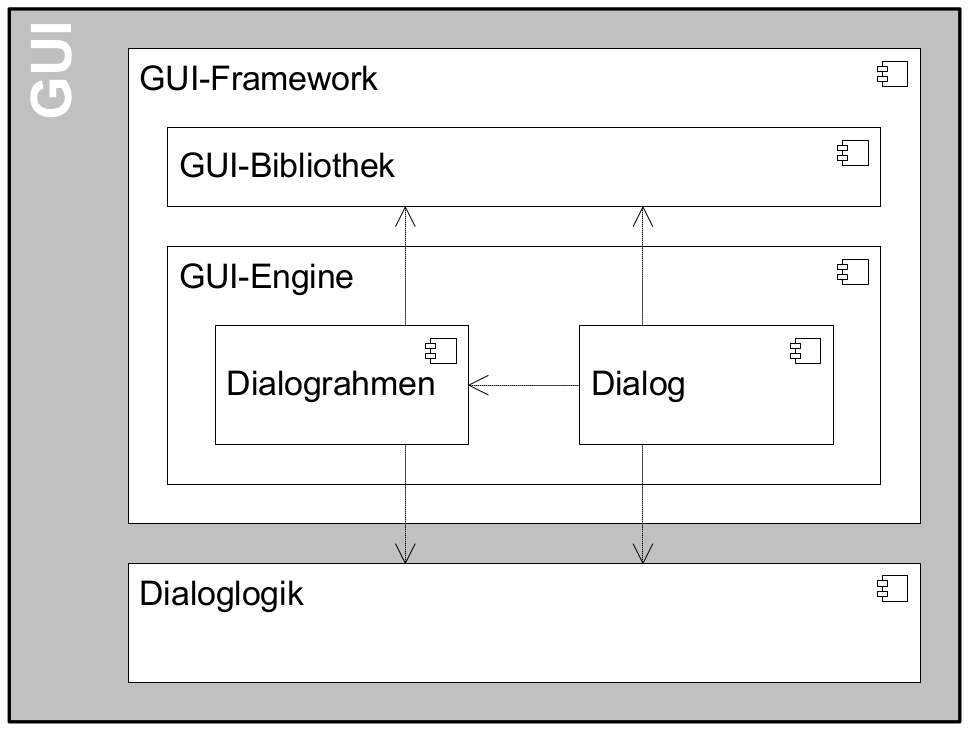
Die GUI-Architektur setzt eine Trennung der Dialogsteuerung und des Layouts um. Diese Trennung hat den Vorteil, dass das Layout der Bildschirmmasken bei Bedarf relativ einfach ausgetauscht werden kann. Während der Entwicklung können Spezialisten für das Layout unabhängig von den Spezialisten für die Umsetzung der Dialogsteuerung arbeiten. Für die Dialogsteuerung von Web-GUIs wird das Framework SpringWebFlow (GUI-Engine) verwendet, für das Layout JSF (GUI-Bibliothek).
Ein am Client durchgeführter Arbeitsprozess besteht in der Regel aus mehr als einem Dialogschritt und damit aus mehr als einem Aufruf des Servers. Dabei sind zum Beispiel folgende Aufgaben zu lösen:
-
Über mehrere Dialogschritte müssen Zustandsinformationen erhalten werden.
-
Ergebnisse von aufwändigen Operationen sollen in einem Cache gehalten werden.
Dieser Zustand muss innerhalb der Anwendung abgebildet werden. Hierzu wird ein zustandsloser Server realisiert und der Zustand wird in der Datenbank gehalten. Der Serverprozess selbst hat keinen Zustand. Sobald ein Aufruf durch den Client erfolgt, muss der Server zunächst den aktuellen Zustand rekonstruieren. Dies erfolgt dadurch, dass der Client eine Session-ID übergibt und der Server die benötigten Daten aus einem Datenbank-Zwischenspeicher unter diesem Schlüssel nachschlägt. Mit dieser Lösung lassen sich sehr einfach Loadbalancing- und Failover-Lösungen über Rechner-Cluster realisieren.
Weiterführende technische Details zur GUI sind im Detailkonzept Komponente Web-GUI enthalten.
1.5.2. Single Page Application
Eine GUI kann auch als Single Page Application (SPA) umgesetzt werden.
Dadurch ist eine Reduzierung der Last auf dem Server möglich und die Umsetzung von komplexeren Nutzerinteraktionen wird erleichtert; vor allem bei diesen Fällen kann sich eine Migration lohnen. Zudem können teilweise Offline-Funktionalitäten umgesetzt werden.
Genauer zu prüfen ist der Einsatz von SPAs vor allem in Fällen, in denen Clients nur über sehr schwache Ressourcen verfügen.
Folgende Komponenten kommen in einer SPA normalerweise zum Einsatz:
-
GUI-Framework: Das Framework kümmert sich darum, vom Browser korrekt renderbaren Code zu erzeugen und gibt die dazu nötigen Mittel vor. Für die IsyFact ist hier Angular vorgesehen.
-
GUI-Bibliothek(en): Die GUI-Bibliotheken bieten wiederverwendbare und stylebare Komponenten im Kontext des Frameworks an.
-
Dialoglogik: Die Dialoglogik liegt rein clientseitig vor; sie ist der Ort, an dem Front-End-Code entwickelt wird.
1.6. Batch
Ein Batch realisiert eine eigenständige Verarbeitung ohne direkten Benutzereingriff während des Ablaufes. An einen Batch werden verschiedene Anforderungen gestellt: Ausführungszeitpunkt, Abhängigkeiten, Datenvolumen, ausgeführte Funktionalität, Eingaben, Ausgaben usw.
Aus Architektur-Sicht werden diese Anforderungen durch zwei Komponenten abgedeckt: den Batchrahmen und die Batchlogik.
Batchrahmen: Der Batchrahmen stellt die Schnittstelle für den Aufruf der Batchfunktionalität zur Verfügung. Er übernimmt auch die Transaktionssteuerung und die Steuerung für einen Restart.
Batchlogik: Die Batchlogik wird vom Batchrahmen aufgerufen, um die Funktionalität des Batchverarbeitungsprogramms zu aktivieren. Die Funktionalität, das heißt die fachliche Logik und die Arbeitsschritte eines Batches, werden als Anwendungsfälle erfasst. Wenn diese Anwendungsfälle auch von anderen Nutzern benötigt werden, dann sind sie im Anwendungskern implementiert.
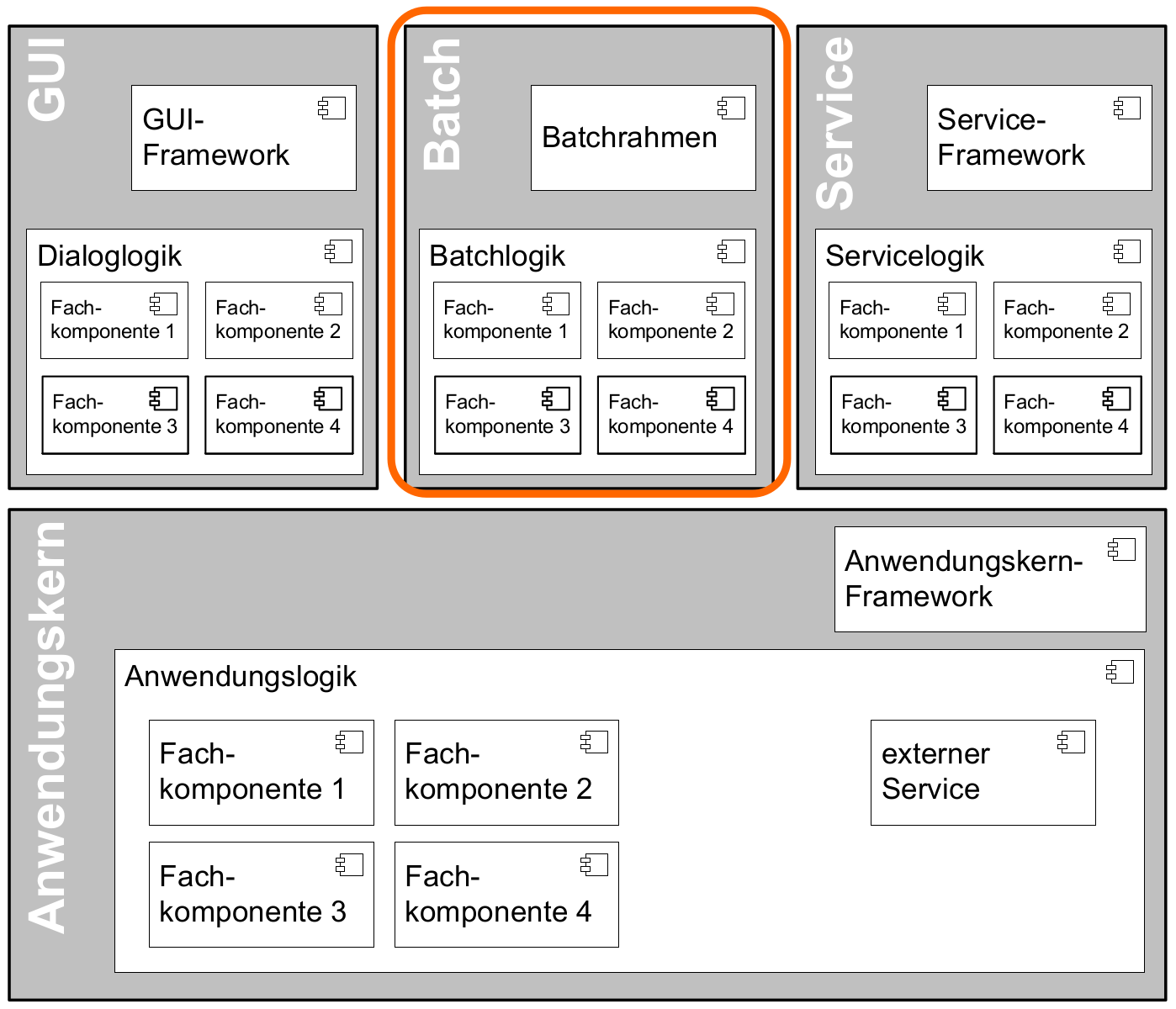
Batches werden als eigener Prozess auf einem eigenen Server ausgeführt, das heißt sie laufen nicht in der virtuellen Maschine des Application Servers ab. Batches werden somit in einer eigenen Ablaufumgebung ausgeführt und greifen direkt auf die Datenbank oder auch auf Dateien zu. Die benötigte Funktionalität des Anwendungskerns wird dem Batch als Bibliothek zur Verfügung gestellt und nicht über einen Service-Aufruf genutzt. Der Grund für diese Entscheidung liegt in den Datenmengen, die normalerweise von einem Batch verarbeitet werden: Die Übermittlung dieser Datenmengen über eine remote genutzte Schnittstelle ist ein möglicher Flaschenhals in der Anwendung. Dieser Flaschenhals wird durch die Nutzung der Anwendungskernfunktionalität als Bibliothek vermieden.
Batch-Abläufe bestehen aus einem oder mehreren Batch-Schritten. Die einzelnen Batch-Schritte werden von einem Scheduler aufgerufen und zum vollständigen Batch-Ablauf verbunden. Ein Batch-Schritt wird von einem Programm implementiert, das mit entsprechenden Parametern vom Scheduler aufgerufen werden kann. Die hier beschrieben Batches sind genau diese Batch-Schritte.
Die Batch-Schritte haben eine genormte Schnittstelle für Aufruf und Rückgabewerte. Sie sind in der Regel restart-fähig. Es gibt einen Batch-Rahmen, der dies unterstützt.
Weiterführende technische Details zum Batch sind im Detailkonzept Komponente Batch enthalten.
1.7. Servicezugriffe
Services des Anwendungskerns, die vom IT-System zur Verfügung gestellt werden sollen, werden durch die Komponenten von „Service“ innerhalb der Schicht „Nutzung“ angereichert und nach außen gegeben. Dabei können alle Funktionen des Anwendungskerns genutzt werden. Die Service-Komponenten werden entsprechend den Anwendungskern-Komponenten geschnitten, d.h. für jede Komponente des Kerns, die einen Service anbieten soll, wird eine eigene Service-Komponente implementiert. Service-Komponenten werden nicht mehrere Anwendungskern-Komponenten. Dies würde dem Gebot, in den Services keine Logik zu implementieren, widersprechen.
Der Aufbau der Komponente Service ist in Abbildung 4 dargestellt. Intern besteht die Komponente „Service“ aus zwei Teilen: dem Service-Framework und der Service-Logik.
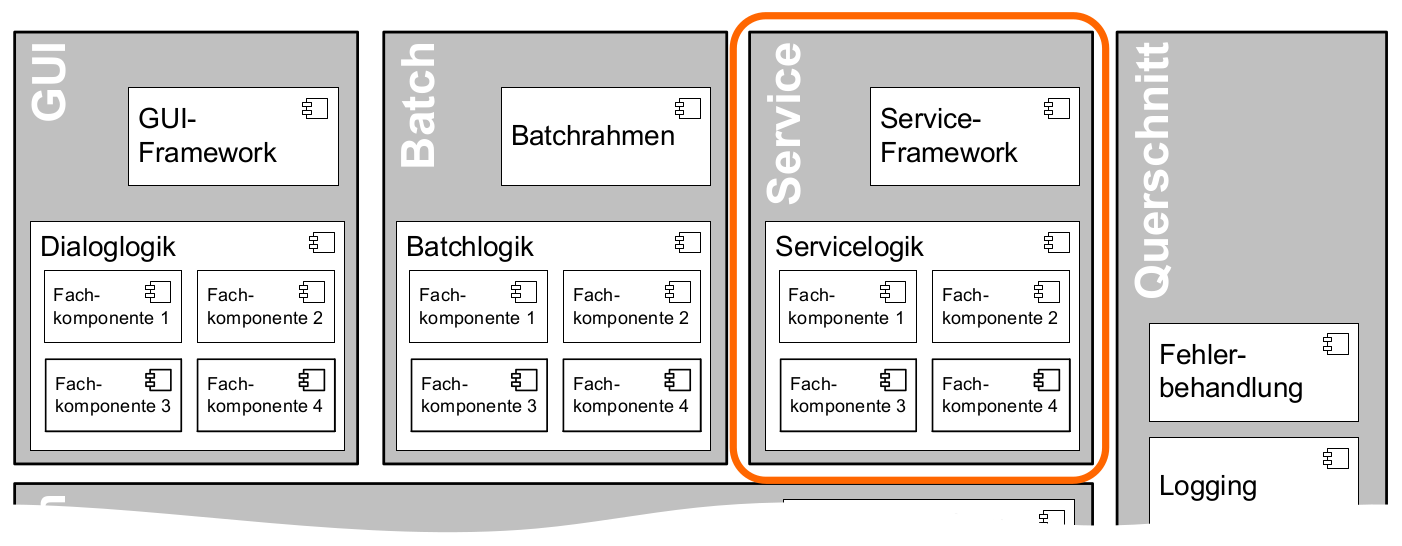
Service-Framework: Das Service-Framework ist die Bezeichnung für die Technologie, mit der die Services des Anwendungskerns zur Verfügung gestellt werden.
|
Hierfür wird aktuell das Framework Spring HTTP Invoker verwendet. Ab IsyFact 2.0 ist die Verwendung von REST-Schnittstellen erlaubt. HTTP Invoker wird in folgenden Releases (IsyFact 2.x) als Schnittstellenformat abgelöst. Die Verwendung von REST-Schnittstellen wird einem gesonderten Konzept erläutert. |
In der Regel wird ein extern angebotener Service noch durch zusätzliche Daten oder Logik ergänzt. Diese werden in der Komponente Service-Logik implementiert.
Service-Logik: Die Service-Logik enthält Daten und Funktionalität, die für die Bereitstellung des Services relevant sind. Im Normalfall ist der Funktionsumfang der Komponente Service-Logik viel geringer als der Funktionsumfang der Entsprechungen im Anwendungskern. Dies liegt darin begründet, dass die Komponente Service-Logik die Funktionalität des Anwendungskerns nutzt, um den Service bereitzustellen. Die Kernfunktionalität des Services ist also im Anwendungskern implementiert. Die Schnittstelle zwischen den Komponenten „Service“ und „Anwendungskern“ ist daher eine interne Schnittstelle.
Weiterführende technische Details zu Services sind im Detailkonzept Komponente Service enthalten.
1.8. Unterstützung technischer Funktionalitäten
Neben der GUI, Services, Batch, Anwendungskern und Persistenzschicht benötigt ein IT-System mehrere querschnittliche Funktionalitäten. Diese querschnittlichen Funktionalitäten sind in jeweils eigenen Dokumenten beschrieben. Eine Übersicht dazu liefern die Beschreibungen der Bausteine der IsyFact-Standard sowie der IsyFact-Erweiterungen.