Nutzungsvorgaben Polling
Java Bibliothek / IT-System
| Name | Art | Version |
|---|---|---|
|
Bibliothek |
v4.2.2 |
1. Einleitung
Im Konzept Polling werden die konzeptionellen Grundlagen und Vorgaben für Polling definiert, um eine einheitliche Umsetzung in der gesamten Anwendungslandschaft zu gewährleisten.
Dieses Dokument beschreibt die Verwendung der Bibliothek isy-polling, die dieses Verfahren implementiert.
Dieses Dokument richtet sich an Entwickler und Chefdesigner, die Polling-Funktionalität in eine Anwendung integrieren wollen.
2. Die Bibliothek isy-polling
Die Bibliothek isy-polling der IsyFact-Standards implementiert den im Konzept Polling dargestellten Synchronisationsmechanismus über JMX.
Die Bibliothek kann mit mehreren zu pollenden Datenquellen und beliebig vielen Instanzen der Anwendung zum Abfragen einer Datenquelle umgehen.
Zur weiteren Erläuterung der einzelnen Klassen der Bibliothek wird zunächst der Begriff „Polling-Cluster“ definiert:
| Ein Polling-Cluster besteht aus einer Menge von Anwendungsinstanzen, die jeweils die gleiche Datenquelle abfragen und wird durch eine innerhalb der Anwendung eindeutige ID identifiziert. |
Ein Polling-Cluster wird durch die Klasse PollingCluster implementiert.
Diese Klasse ist dafür zuständig, die Informationen eines Polling-Clusters zu verwalten.
Hierzu zählen insbesondere der Zeitpunkt der letzten Polling-Aktivität und die Wartezeit.
Die wesentlichen Parameter eines Polling-Clusters werden über die Anwendungskonfiguration festgelegt und beim Start der Anwendung eingelesen.
Die Verwaltung des Pollings für mehrere Nachrichtenquellen erfolgt über einen Polling-Verwalter (Klasse PollingVerwalter).
Der Polling-Verwalter kennt und verwaltet alle PollingCluster der Anwendung.
Die Klasse PollingVerwalter ist die einzige Klasse der Bibliothek, die eine Anwendungsimplementierung direkt nutzt.
Die Methode startePolling prüft, ob die aufrufende Anwendungsinstanz das Polling durchführen darf.
Hierzu wird ihr die ID des Polling-Clusters als Argument übergeben.
Sie liefert true, wenn das Polling gestartet werden darf, ansonsten false.
Hierfür wird der seit der letzten Polling-Aktivität vergangene Zeitraum der anderen Instanzen des Polling-Clusters über JMX abgefragt und zusammen mit der im Polling-Cluster hinterlegten Wartezeit ausgewertet.
Die Methode aktualisiereZeitpunktLetztePollingAktivitaet setzt den Zeitpunkt der letzten Polling-Aktivität für den Polling-Cluster mit der übergebenen ID auf den aktuellen Systemzeitpunkt, die Methode getZeitpunktLetztePollingAktivitaet liefert den Zeitpunkt der letzten Polling-Aktivität für den Polling-Cluster mit der übergebenen ID.
Mit der Annotation PollingAktion ist es möglich, eine Methode zu annotieren, bei deren Aufruf dann der Zeitstempel für den angegebenen Polling-Cluster aktualisiert wird.
Der zugehörige Interceptor ist in der Klasse PollingAktionInterceptor implementiert.
Schließlich ermöglicht die Klasse PollingMBean den anderen Instanzen, den seit der letzten Polling-Aktivität vergangenen Zeitraum über JMX abzufragen.
In Abbildung 1 ist das Klassendiagramm der Bibliothek isy-polling dargestellt.
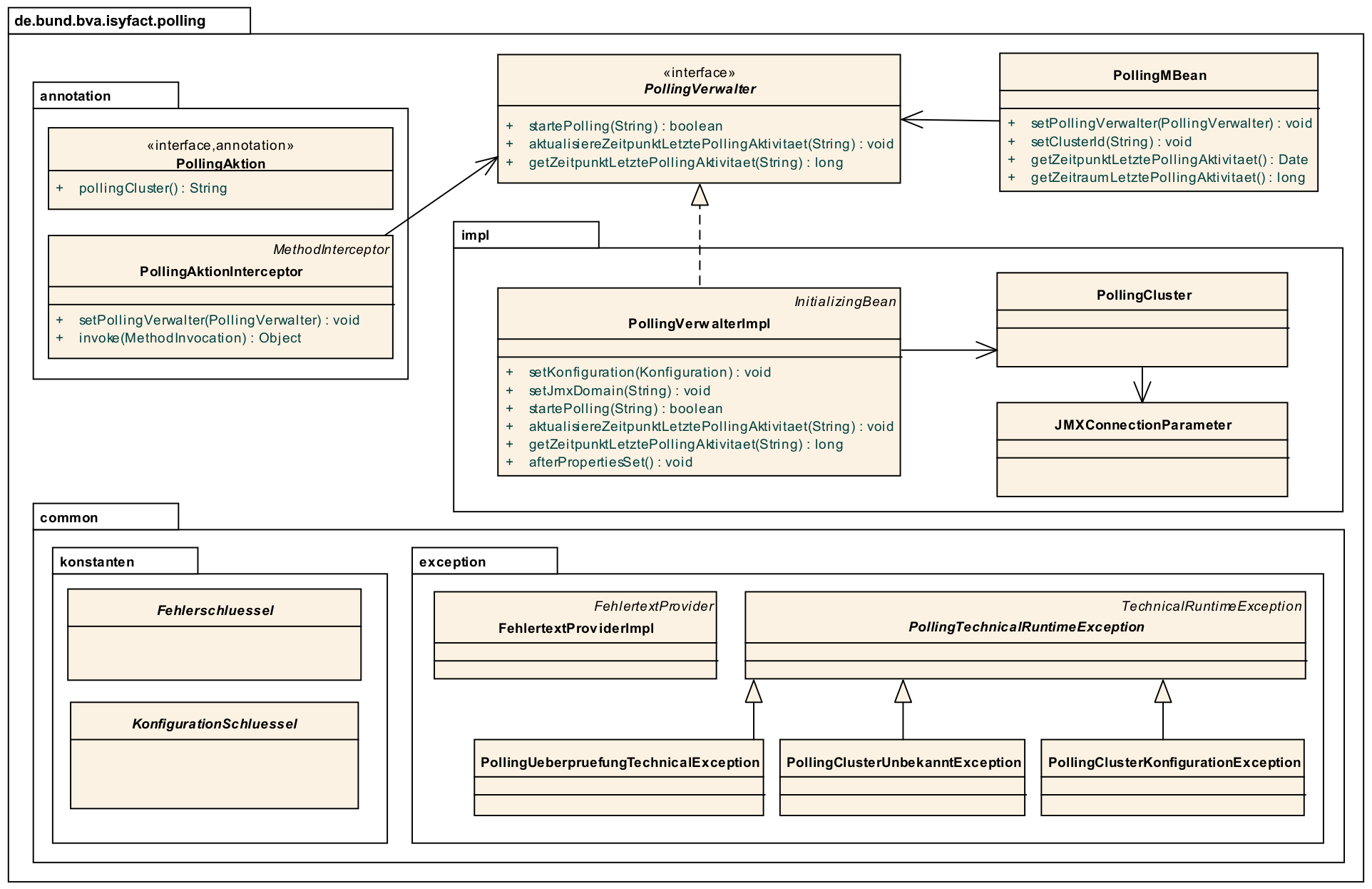
3. Einbinden der Bibliothek in die Anwendung
Polling wird in der Regel in einem Verarbeitungszyklus implementiert, der über einen Timer gestartet wird. Der Verarbeitungszyklus kann eine oder nacheinander mehrere Datenquellen abfragen.
Das Einbinden der Bibliothek isy-polling in eine Anwendung erfolgt über Spring.
JMX-Verbindungen und Polling-Cluster werden über die Anwendungskonfiguration definiert.
Im Folgenden wird im Detail beschrieben, wie die Bibliothek eingebunden und genutzt wird.
3.1. Anwendungskonfiguration
In der Anwendungskonfiguration werden Polling-Cluster und JMX-Verbindungsparameter definiert. Bei der Definition der Polling-Cluster hat man die Möglichkeit einen Cluster für einen gesamten Verarbeitungszyklus oder einen Cluster für jede abzufragende Datenquelle zu definieren. Welche der beiden Möglichkeiten gewählt wird, hängt vom konkreten Anwendungsfall ab und muss beim Entwurf der Anwendung entschieden werden.
3.1.1. Lastverteilung über Cluster-Definition
Wird ein Polling-Cluster je zu pollender Datenquelle festgelegt, so kann eine gewisse Lastverteilung erreicht werden wie folgendes Beispiel zeigt:
Beispiel:
In einer Anwendung ist ein Verarbeitungszyklus so realisiert, dass drei E-Mail-Konten nacheinander abgefragt werden. Der Verarbeitungszyklus wird periodisch über einen Timer gestartet. Es gibt zwei Instanzen der Anwendung. Wird für jedes E-Mail-Konto ein eigener Polling-Cluster definiert, so ist der Ablauf der folgende:
Der Timer im Knoten 1 startet den Verarbeitungszyklus. Es wird zunächst der Polling-Verwalter gefragt, ob das Polling für den Cluster 1 gestartet werden darf. Knoten 2 hat das Polling noch nicht begonnen, so dass der Polling-Verwalter im Knoten 1 die Verarbeitung der Nachrichten aus dem E-Mail-Konto 1 erlaubt.
Zwischenzeitlich startet auch der Timer im Knoten 2 einen Verarbeitungszyklus. Der Polling-Verwalter im Knoten 2 erkennt, dass das Polling im Knoten 1 für den Cluster 1 bereits aktiv ist und verweigert die Erlaubnis, die Nachrichten des E-Mail-Konto 1 abzuarbeiten. Die Anwendung fragt den Polling-Verwalter daher als nächstes um Erlaubnis, das Polling für den Cluster 2 durchzuführen. Das wird erlaubt und Knoten 2 verarbeitet die Nachrichten des E-Mail-Konto 2.
Während Knoten 2 noch mit den Nachrichten des E-Mail-Konto 2 beschäftigt ist, hat Knoten 1 alle Nachrichten aus E-Mail-Konto 1 verarbeitet. Er fragt jetzt den Polling-Verwalter um Erlaubnis, das Polling für den Cluster 2 durchzuführen. Die Erlaubnis wird verweigert, weil Knoten 2 bereits damit beschäftigt ist. Daher fragt die Anwendung als nächstes um Erlaubnis, das Polling für den Cluster 3 durchzuführen. Das wird erlaubt und Knoten 1 verarbeitet die Nachrichten aus dem E-Mail-Konto 3.
Knoten 2 ist mit der Verarbeitung des E-Mail-Konto 2 fertig und möchte nun E-Mail-Konto 3 verarbeiten, was aber verweigert wird, da Knoten 1 bereits damit beschäftigt ist. Dies schließt den Verarbeitungszyklus im Knoten 2 ab.
Dieses Beispiel zeigt, dass E-Mail-Konten parallel von beiden Instanzen abgearbeitet werden können.
3.1.2. Konfiguration über Properties
Polling-Cluster und JMX-Verbindungsparameter werden über Properties in application.properties konfiguriert.
Konfigurationsparameter einer Ausprägung haben dann das Namensschema <Konfigurationsklassen-Präfix>.<ID der Ausprägung>.<Name des Konfigurationsparameters>.
Das Beispiel in Listing 1 zeigt folgende Vorgaben:
-
Die Properties von für die Konfiguration der JMX-Verbindungen haben das Präfix
isy.polling.jmx.verbindungen. Das Präfix für die Cluster-Konfiguration istisy.polling.cluster. -
Für die Konfiguration der JMX-Verbindung gibt es die Konfigurationsparameter
host,port,benutzerundpasswort. Für die Konfiguration der Cluster gibt es die Parametername,wartezeit,jmxverbindungen. -
Es gilt die Konvention, dass IDs für Ausprägungen großgeschrieben werden. Damit kann an einzelnen Konfigurationseinträgen sofort erkannt werden, dass sie zu einer Konfigurationsklasse gehören.
isy.polling.jmx.verbindungen.SERVER1.host = host1
isy.polling.jmx.verbindungen.SERVER1.port = 9001
isy.polling.jmx.verbindungen.SERVER1.benutzer = userid1
isy.polling.jmx.verbindungen.SERVER1.passwort = pwd1
isy.polling.cluster.POSTFACH1_CLUSTER.name = Postfachabruf-1
isy.polling.cluster.POSTFACH1_CLUSTER.wartezeit = 600
isy.polling.cluster.POSTFACH2_CLUSTER.name = Postfachabruf-2
isy.polling.cluster.POSTFACH2_CLUSTER.wartezeit = 700
isy.polling.cluster.POSTFACH2_CLUSTER.jmxverbindungen = server1,server23.1.2.1. Konfigurationsparameter
JMX-Verbindungen haben die folgenden Attribute:
isy.polling.jmx.verbindungen.<ID>.host:
Hostangabe für den JMX-Zugriff.
isy.polling.jmx.verbindungen.<ID>.port:
Portangabe für den JMX-Zugriff.
isy.polling.jmx.verbindungen.<ID>.benutzer:
Benutzerkennung für den JMX-Zugriff
isy.polling.jmx.verbindungen.<ID>.passwort:
Kennwort für den JMX-Zugriff
Polling-Cluster haben die folgenden Attribute:
isy.polling.cluster.<ID>.name:
Name des Polling-Clusters.
Der hier festgelegte Name wird zur MBean-Identifikation benutzt und ist in der JMX-Konsole sichtbar.
isy.polling.cluster.<ID>.wartezeit:
Wartezeit in Sekunden, die abgelaufen sein muss, damit diese Anwendung das Polling übernehmen kann.
Dieser Wert sollte doppelt so groß sein, wie der Delay-Wert des Timers, der den Verarbeitungszyklus auslöst.
Die Wartezeit muss mindestens 10 Sekunden betragen.
isy.polling.cluster.<ID>.jmxverbindungen:
Kommaseparierte Liste von IDs der Verbindungsparameter zu den übrigen Clusterservern.
Dieser Eintrag ist optional und wird in der Regel nicht benötigt.
Wird er weggelassen, so werden alle für das Polling konfigurierten JMX-Verbindungen zugeordnet.
Die JMX-Domain für den Polling-Verwalter ist in der Regel das Basispackage der Anwendung:
isy.polling.jmx.domain=<Domäne>
3.1.3. Konfiguration für den Test
Für Tests der Anwendung, insbesondere für lokale Entwicklertests, stehen in der Regel nicht mehrere Instanzen der Anwendung zur Verfügung. In diesem Fall kann das konfigurierte Polling die Tests behindern.
Für Tests kann der Polling-Verwalter in den Standalone-Modus versetzt werden. In diesem Modus erkennt der Polling-Verwalter, dass keine Cluster-Partner existieren und die Polling-Aktionen werden immer zugelassen.
Der Standalone-Modus wird automatisch gesetzt, wenn in der Konfiguration der keine JMX-Verbindungen über die Property isy.polling.jmx.verbindungen konfiguriert werden.
Da dieses Verhalten in der Regel im Produktivbetrieb nicht erwünscht ist, wird die folgende Warnung in die Log-Ausgabe geschrieben:
| Für das Polling der Anwendung wurden keine JMX-Verbindungsparameter angegeben! Der Polling-Modus wurde auf "Standalone" gesetzt! |
3.1.4. Beispiel für eine Polling-Konfiguration
In Listing 2 ist eine vollständige Polling-Konfiguration für einen Cluster aufgeführt, der aus insgesamt zwei Instanzen der Anwendung besteht.
# -----------------------------------------------------------
# Parameter für das Polling
# -----------------------------------------------------------
# Verbindungsparameter zum anderen Knoten
# Hostangabe für den JMX-Zugriff
isy.polling.jmx.verbindungen.SERVER2.host = localhost
# Portangabe für den JMX-Zugriff
isy.polling.jmx.verbindungen.SERVER2.port = 9010
# Benutzerkennung für den JMX-Zugriff
isy.polling.jmx.verbindungen.SERVER2.benutzer = userid
# Kennwort für den JMX-Zugriff
isy.polling.jmx.verbindungen.SERVER2.passwort = pwd
# JMX-Domain; In der Regel das Basispackage der Anwendung
isy.polling.jmx.domain=de.bund.bva.domaene.anwendung
# Name des Clusters. Dieser Name wird zur Bildung der MBean-
# Identifikation verwendet.
isy.polling.cluster.MAILABRUF_CLUSTER.name = XY-Nachrichten
# Wartezeit in Sekunden, die abgelaufen sein muss, damit
# diese Anwendung das Polling übernehmen kann.
isy.polling.cluster.MAILABRUF_CLUSTER.wartezeit = 600Cluster können nicht dynamisch nur durch die Konfiguration erzeugt werden. Sie sind vielmehr eng mit der Anwendungslogik verknüpft und sollten daher nicht vom Betrieb geändert werden.
3.1.5. Beispiel für eine Polling-Konfiguration mit Lastverteilung
In Listing 3 ist die Polling-Konfiguration für zwei zu pollende Datenquellen mit jeweils eigenem Polling-Cluster aufgeführt. Die beiden Cluster bestehen jeweils aus den zwei gleichen Instanzen der Anwendung. Wie in Kapitel Lastverteilung über Cluster Definition beschrieben, kann so eine Lastverteilung erfolgen.
# -----------------------------------------------------------
# Parameter für das Polling
# -----------------------------------------------------------
# Verbindungsparameter zum anderen Knoten
# Hostangabe für den JMX-Zugriff
isy.polling.jmx.verbindungen.SERVER2.host = localhost
# Portangabe für den JMX-Zugriff
isy.polling.jmx.verbindungen.SERVER2.port = 9010
# Benutzerkennung für den JMX-Zugriff
isy.polling.jmx.verbindungen.SERVER2.benutzer = userid
# Kennwort für den JMX-Zugriff
isy.polling.jmx.verbindungen.SERVER2.passwort = pwd
# JMX-Domain; In der Regel das Basispackage der Anwendung
isy.polling.jmx.domain=de.bund.bva.domaene.anwendung
# Parameter des POSTFACH1_CLUSTER
# Name des Clusters. Dieser Name wird zur Bildung der MBean-
# Identifikation verwendet.
isy.polling.cluster.POSTFACH1_CLUSTER.name = Postfachabruf-1
# Wartezeit in Sekunden, die abgelaufen sein muss, damit
# diese Anwendung das Polling übernehmen kann.
isy.polling.cluster.POSTFACH1_CLUSTER.wartezeit = 600
# Parameter des POSTFACH2_CLUSTER
# Name des Clusters. Dieser Name wird zur Bildung der MBean-
# Identifikation verwendet.
isy.polling.cluster.POSTFACH2_CLUSTER.name = Postfachabruf-2
# Wartezeit in Sekunden, die abgelaufen sein muss, damit
# diese Anwendung das Polling übernehmen kann.
isy.polling.cluster.POSTFACH2_CLUSTER.wartezeit = 6003.2. Spring-Konfiguration
Die Bean für den Polling-Verwalter wird automatisch durch isy-polling konfiguriert.
Der Interceptor, der zur Verwendung der @PollingAktion-Annotation notwendig, wird ebenfalls automatisch konfiguriert.
Zusätzlich wird für jeden Cluster eine MBean konfiguriert (Listing 4).
@Bean
public PollingMBean mailabrufClusterMonitor(PollingVerwalter pollingVerwalter) {
PollingMBean mBean = new PollingMBean();
mBean.setClusterId("MAILABRUF_CLUSTER");
mBean.setPollingVerwalter(pollingVerwalter);
return mBean;
}Listing 4: Die Property pollingVerwalter enthält die Referenz auf die Komponente „Polling-Verwalter“, die Property clusterId enthält die ID des Polling-Clusters, für den sie den seit der letzten Polling-Aktivität vergangenen Zeitraum liefern soll.
Die Einbindung in JMX erfolgt über den MBean-Exporter dann wie in Listing 5.
@Bean
public MBeanExporter mBeanExporter(@Qualifier("mailabrufClusterMonitor") PollingMBean mailabrufClusterMonitor, IsyPollingProperties isyPollingProperties) {
MBeanExporter mBeanExporter = new MBeanExporter();
mBeanExporter.setRegistrationPolicy(RegistrationPolicy.REPLACE_EXISTING);
mBeanExporter.setAssembler(new MetadataMBeanInfoAssembler(new AnnotationJmxAttributeSource()));
mBeanExporter.setAutodetect(false);
Map<String, Object> mBeans = new HashMap<>();
String key = "de.bund.bva.isyfact.polling:type=PollingStatus,name=\"Polling-Aktivitaet-"
+ isyPollingProperties.getCluster().get("MAILABRUF_CLUSTER").getName() + "\"";
mBeans.put(key, mailabrufClusterMonitor);
mBeanExporter.setBeans(mBeans);
return mBeanExporter;
}Hierbei ist zu beachten, dass der Cluster-Name aus der Konfiguration hier für die Bildung des Keys für die MBeans verwendet wird.
3.3. Nutzung im Code
Wie bereits erwähnt, wird Polling in der Regel in einem Verarbeitungszyklus implementiert, der über einen Timer gestartet wird. Der Verarbeitungszyklus kann eine oder nacheinander mehrere Datenquellen abfragen, für die jeweils ein Polling-Cluster definiert sein kann. Für jeden Polling-Cluster werden in einem Verarbeitungszyklus die folgenden Schritte ausgeführt:
Listing 6, ob das Polling für den Cluster gestartet werden darf. Ist das nicht der Fall, ist die Verarbeitung für den Cluster beendet.
if(!pollingVerwalter.startePolling("MAILABRUF_CLUSTER")) {
LOG.info("Verarbeitung wurde nicht gestartet, da die " +
"Wartezeit für den Cluster mit der ID " +
"\"MAILABRUF_CLUSTER\" noch nicht " +
"abgelaufen ist.");
return;
}
fuehreVerarbeitungDurch();-
Durchführen der Verarbeitung für jeden Datensatz. Am Ende der Verarbeitung eines Datensatzes wird der Zeitpunkt der letzten Polling-Aktivität aktualisiert.
// ...
for (Datensatz datensatz: datensaetze) {
// Verarbeite Datensatz
// ...
pollingVerwalter.aktualisiereZeitpunktLetztePollingAktivitaet("MAILABRUF_CLUSTER");
}
// ...oder
/**
* Führt eine Polling-Aktion aus
*/
@PollingAktion(pollingCluster="MAILABRUF_CLUSTER")
public void doPollingAktion () {
// Verarbeite Datensatz
// ...
}
// ...
for (Datensatz datensatz: datensaetze) {
// Verarbeite Datensatz
// ...
doPollingAktion();
}
// ...